Panoramica
- Creare un’attività di estrazione basata su prompt.
- Configurare una connessione LLM.
- Scrivere prompt di estrazione efficaci.
- Definire formato e struttura dell’output.
- Impostare il livello di rigidità e le Regole di validazione.
- Testare e perfezionare l’estrazione.
- Estrazione delle informazioni del Fornitore dalle fatture
- Acquisizione dei dati del documento a livello di intestazione
- Elaborazione di documenti semi-strutturati
- Documenti con layout variabili
Prerequisiti
- Accesso ad ABBYY Vantage Advanced Designer.
- Una connessione LLM configurata. Vedi Come configurare le connessioni LLM.
- Un Document Skill con documenti di esempio caricati.
- Una conoscenza di base della struttura JSON.
- Definizioni dei field per i dati che vuoi estrarre.
Introduzione all’estrazione basata su prompt
Che cos’è l’estrazione basata su prompt?
- Ruolo: Il ruolo che il modello LLM deve assumere (ad es. “modello di estrazione dati”).
- Istruzioni: Come estrarre e formattare i dati.
- Struttura di output: L’esatto formato JSON dei risultati.
- Regole: Linee guida per gestire dati ambigui o mancanti.
Vantaggi
- Nessun dato di training richiesto: funziona con il solo prompt engineering.
- Flessibile: facile aggiungere o modificare i field.
- Gestisce le variazioni: gli LLM possono comprendere diversi formati di documento.
- Configurazione rapida: più veloce dell’addestramento dei modelli di ML tradizionali.
- Linguaggio naturale: scrivi le istruzioni in inglese semplice.
Limitazioni
- Costo: Ogni estrazione utilizza chiamate all’API LLM.
- Velocità: Più lenta rispetto all’estrazione tradizionale per documenti semplici.
- Coerenza: I risultati possono variare leggermente tra un’esecuzione e l’altra.
- Limiti di contesto: I documenti molto lunghi potrebbero richiedere una gestione particolare.
Passaggio 1: Aggiungi un’attività basata su prompt
- Apri il tuo Document Skill in ABBYY Vantage Advanced Designer.
- Nel pannello di sinistra, individua EXTRACT FROM TEXT (NLP).
- Trova e fai clic su Prompt-based.
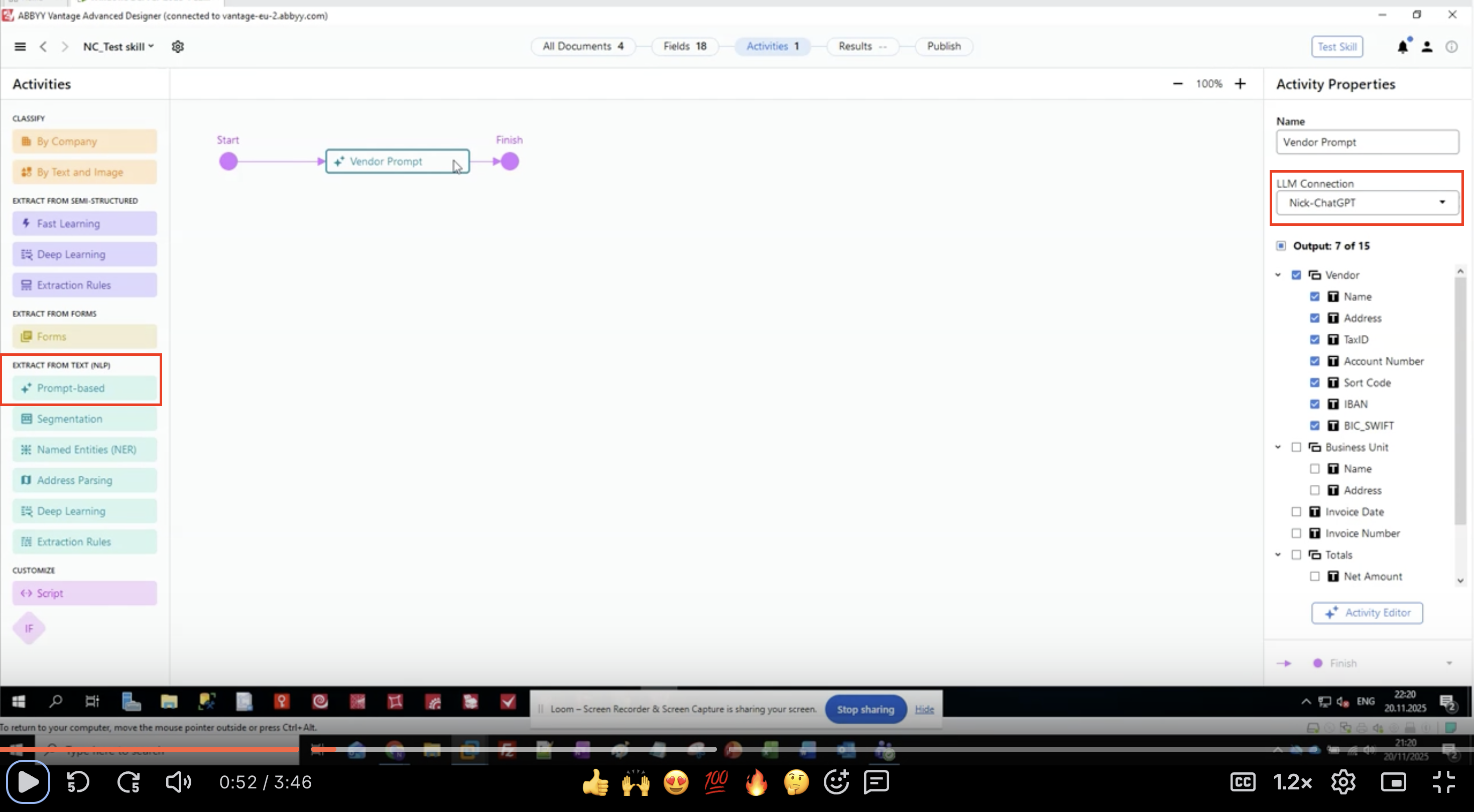
- L’attività viene aggiunta al canvas del tuo flusso di lavoro.
- Collegala tra le attività di input e di output.
Step 2: Configurare la connessione LLM
- Seleziona nel tuo flusso di lavoro l’attività basata su prompt.
- Nel pannello Activity Properties a destra, individua LLM Connection.
- Fai clic sul menu a discesa.
- Seleziona dall’elenco la connessione LLM che hai configurato.
- Esempio:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Esempio:
- Verifica che la connessione sia selezionata.
Step 3: Definire i field di output
- Nel pannello Activity Properties, individua la sezione Output.
- Vedrai un elenco gerarchico di gruppi di field e di singoli field.
- In questo esempio, estraiamo le informazioni sul fornitore:
- Fornitore
- Nome
- Indirizzo
- TaxID
- Numero conto
- Sort Code
- IBAN
- BIC_SWIFT
- Unità aziendale
- Nome
- Indirizzo
- Data fattura
- Numero della fattura
- Totali
- Importo netto
- Fornitore
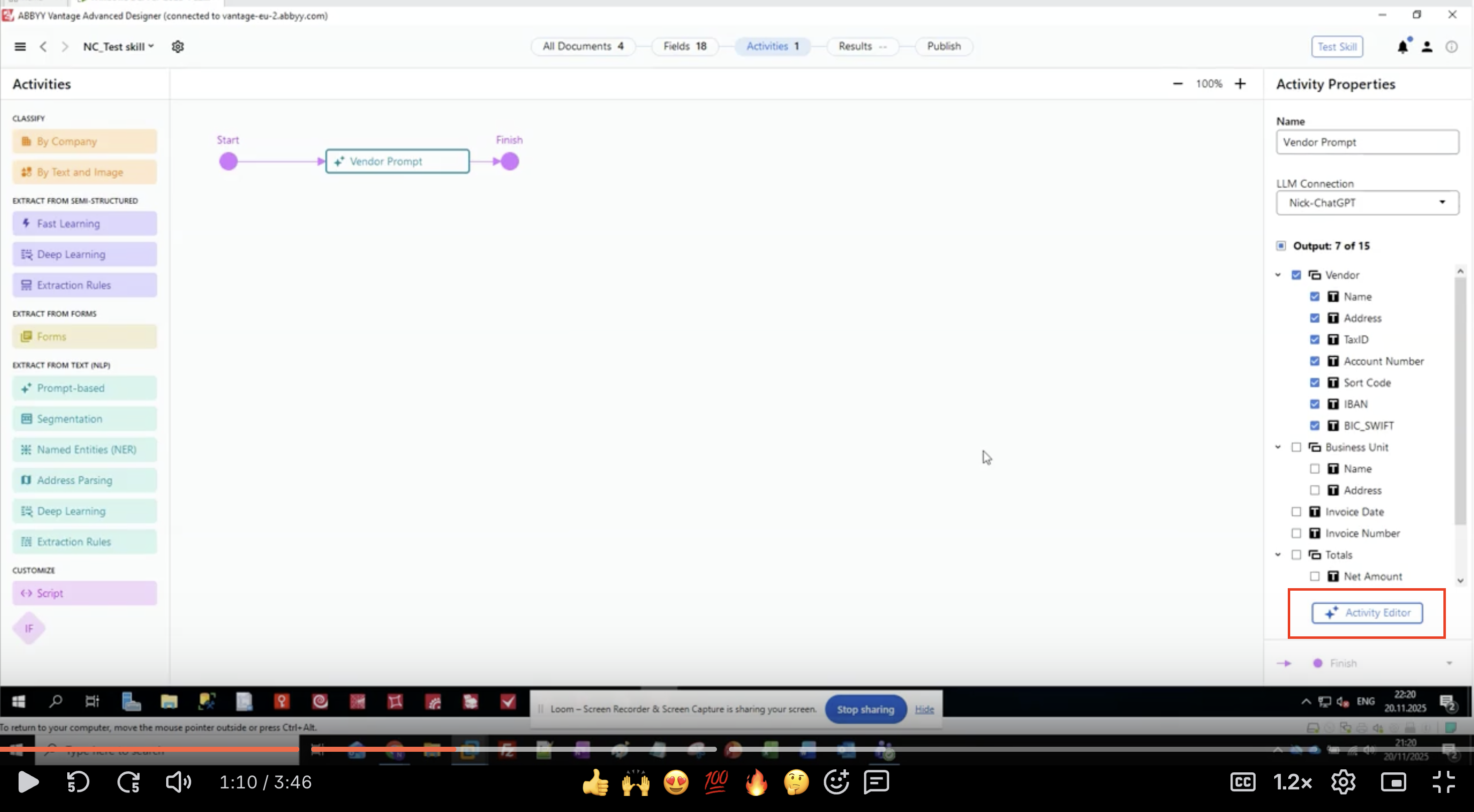
- Fai clic sul pulsante Activity Editor per iniziare a configurare il prompt.
Passaggio 4: Scrivere la Definizione del Ruolo
- Nell’Activity Editor visualizzerai l’interfaccia Prompt Text
- Inizia con la sezione ROLE:
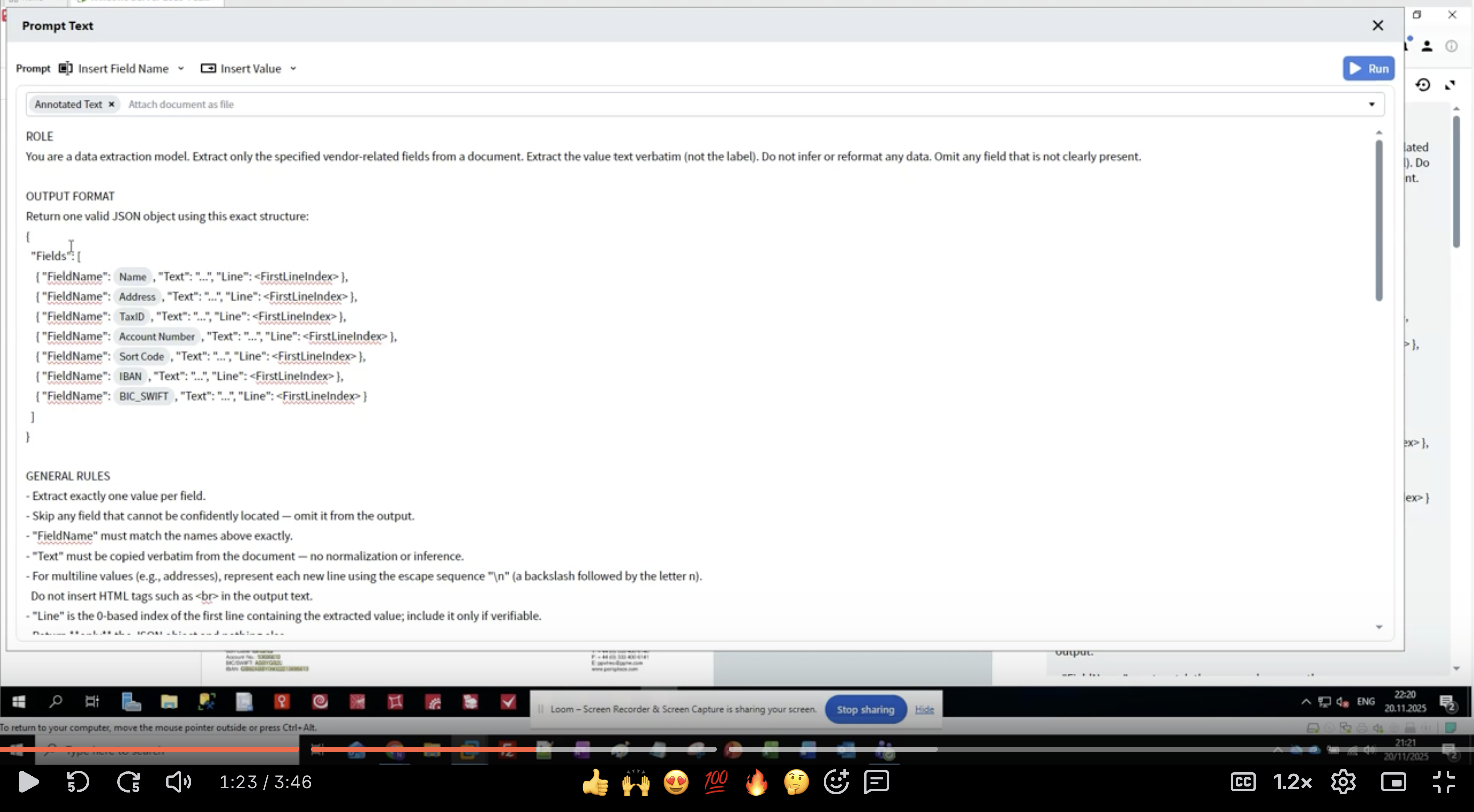
- Sii specifico: “data extraction model” indica all’LLM il suo scopo
- Definisci l’ambito: “vendor-related fields” limita cosa estrarre
- Imposta le aspettative: “value text verbatim” evita la riformattazione
- Gestisci i dati mancanti: “Omit any field che non sia chiaramente presente”
- Mantieni il ruolo chiaro e conciso
- Usa frasi imperative (“Extract”, “Do not infer”)
- Sii esplicito su cosa NON fare
- Definisci come gestire i casi limite
Passaggio 5: Definire il formato di output
- Sotto la sezione ROLE, aggiungere l’intestazione OUTPUT FORMAT.
- Definire la struttura JSON:
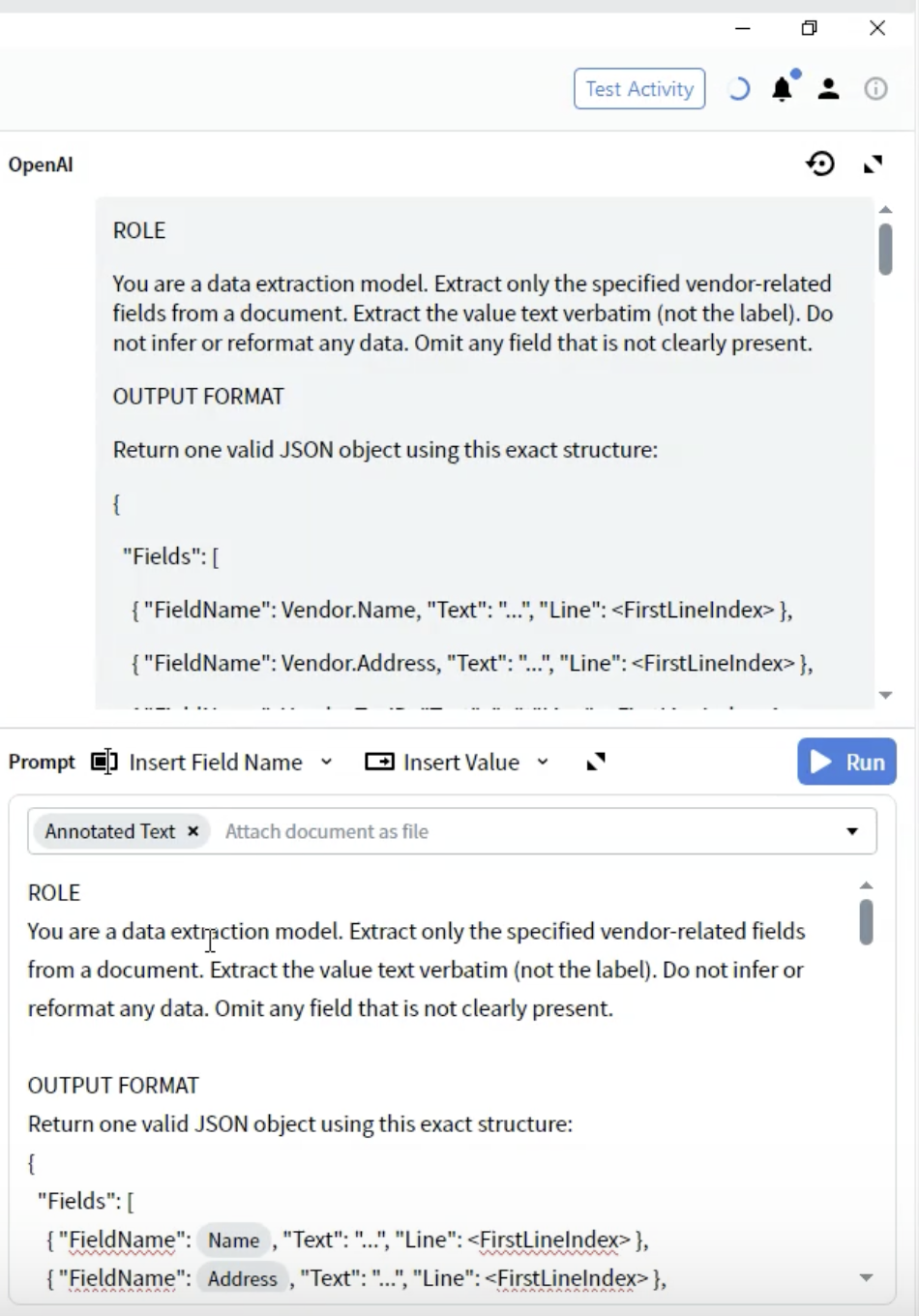
- FieldName: Deve corrispondere esattamente alle definizioni dei tuoi field (ad es.
Vendor.Name). - Text: Il valore estratto come string.
- Line: Indice di riga (a partire da 0) in cui il valore compare nel documento.
- Utilizza i nomi dei field esattamente come nella configurazione di output.
- Includi tutti i field anche se alcuni possono essere vuoti.
- La struttura deve essere un JSON valido.
- I numeri di riga aiutano nella verifica e nella risoluzione dei problemi.
Fase 6: Aggiungi regole di estrazione specifiche per i Field
- Modelli di riconoscimento: Elenca etichette alternative per ogni field.
- Specifiche di formato: Descrivi il formato esatto da estrarre.
- Indicazioni sulla posizione: Dove si trova di solito il dato.
- Esclusioni: Cosa NON estrarre.
- Numera le regole per maggiore chiarezza.
- Fornisci più varianti di etichetta.
- Specifica a chi appartengono i dati (lato fornitore vs. lato cliente).
- Includi esempi di formato tra parentesi.
- Sii esplicito in merito ai field correlati (ad es., “Ignora l’IBAN — ha un proprio field”).
Step 7: Applicare le regole di STRICTNESS
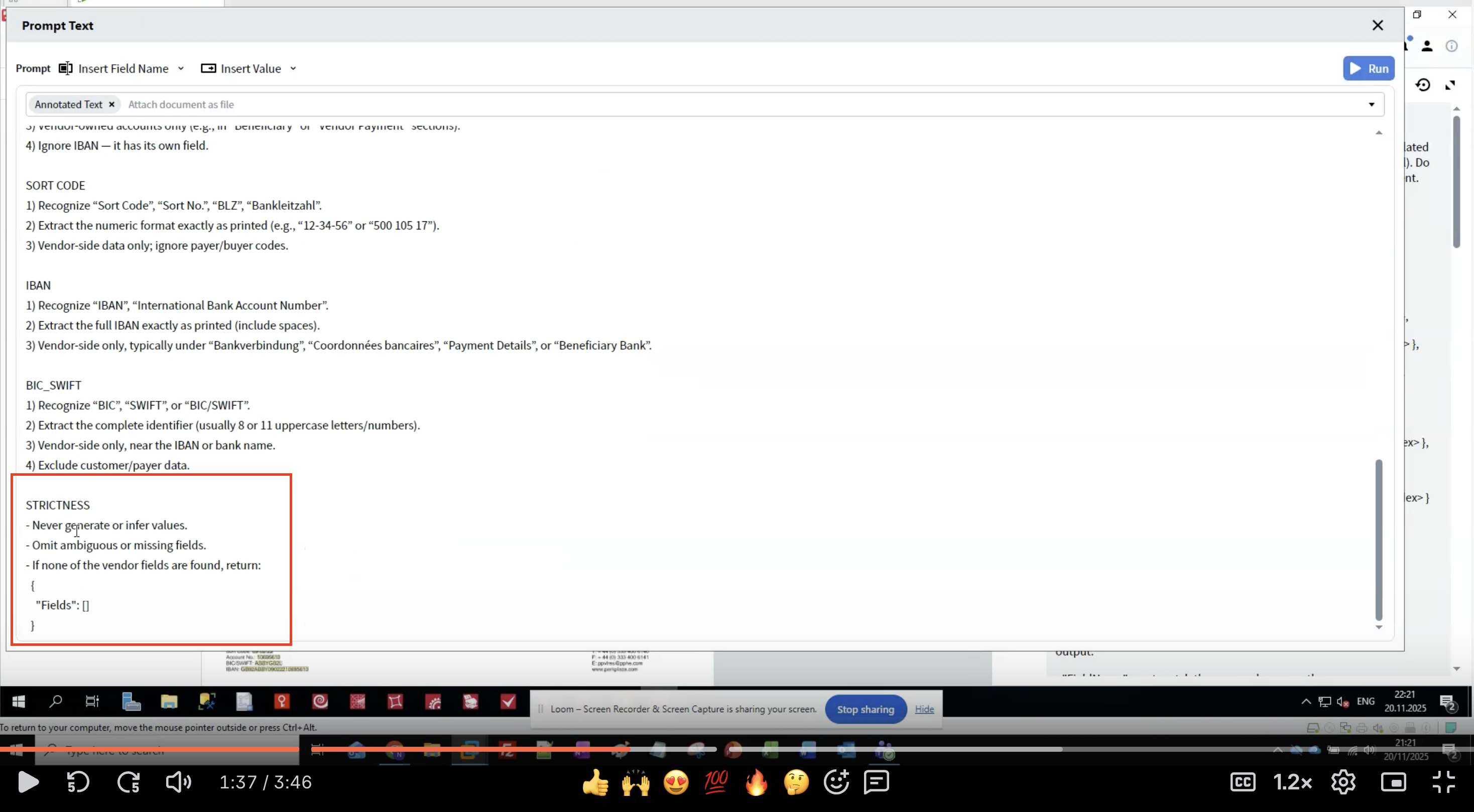
- Previene le allucinazioni: i LLM possono generare dati plausibili ma errati.
- Garantisce coerenza: regole chiare riducono la variabilità tra esecuzioni.
- Gestisce i dati mancanti: definisce cosa fare quando non vengono trovati dei field.
- Mantiene l’integrità dei dati: un’estrazione verbatim preserva la formattazione originale.
- Non generare mai dati che non compaiono nel documento.
- Omettere le estrazioni incerte invece di indovinare.
- Restituire una struttura vuota se non viene trovato alcun field.
- Far corrispondere esattamente i nomi dei field.
- Preservare la formattazione originale del testo.
Passaggio 8: Selezionare il formato del documento
- Nell’Activity Editor, individua il menu a discesa Prompt.
- Vedrai le opzioni relative a come il documento viene fornito all’LLM.
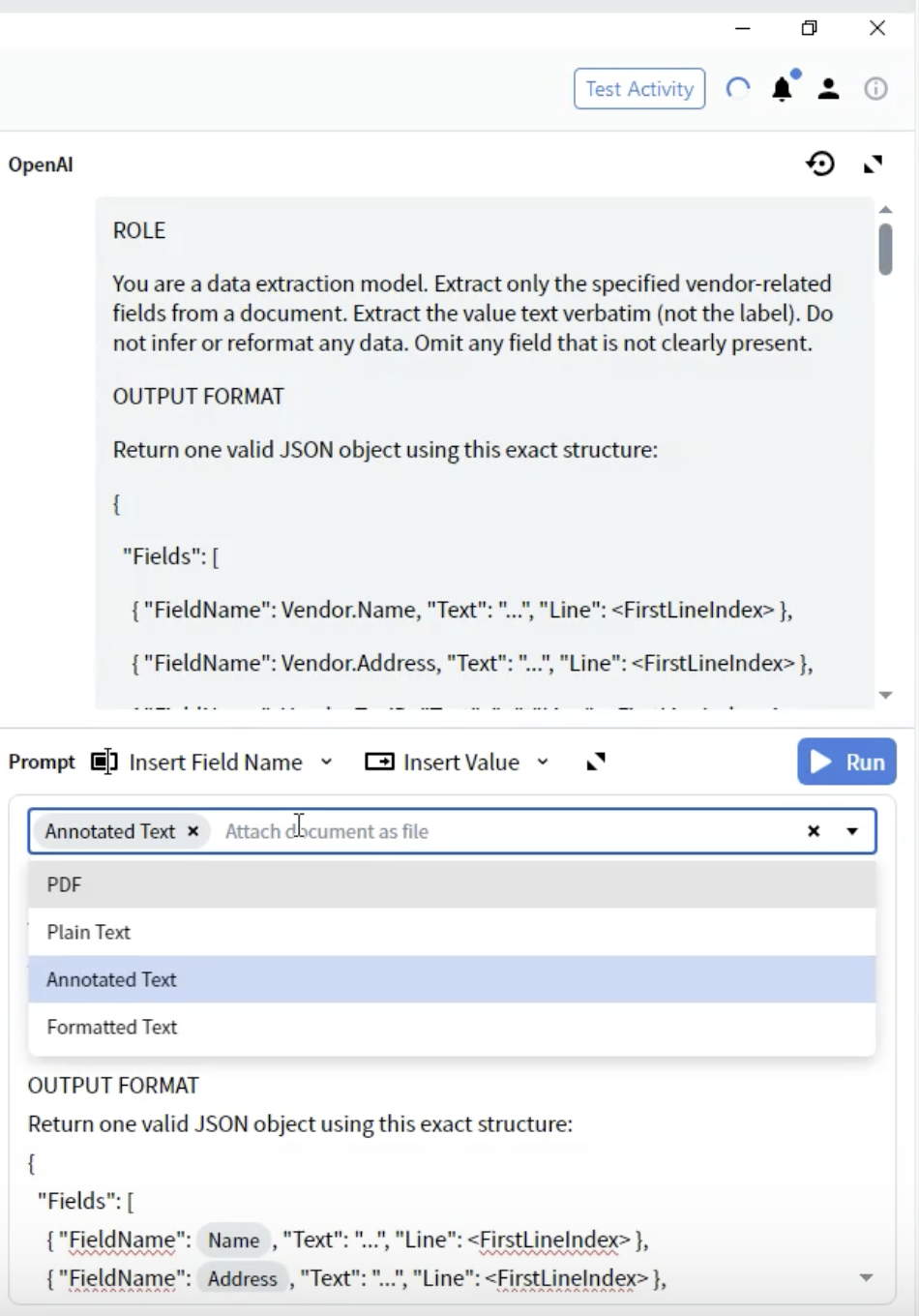
- PDF: File PDF originale
- Da usare per: Documenti in cui il layout è fondamentale
- Considerazioni: Dimensioni del file maggiori, alcuni LLM hanno un supporto PDF limitato
- Plain Text: Estrazione di testo non formattato
- Da usare per: Documenti semplici composti solo da testo
- Considerazioni: Perde tutte le informazioni di formattazione e layout
- Annotated Text ⭐ (Consigliato)
- Da usare per: La maggior parte dei tipi di documento
- Considerazioni: Preserva la struttura pur restando basato su testo
- Vantaggi: Miglior equilibrio tra struttura e prestazioni
- Formatted Text: Testo con formattazione di base preservata
- Da usare per: Documenti in cui parte della formattazione è importante
- Considerazioni: Via di mezzo tra Plain e Annotated
- Seleziona Annotated Text per ottenere i risultati migliori
Passaggio 9: Test dell’estrazione
Esegui l’Activity
- Chiudi l’Activity Editor.
- Vai alla scheda All Documents.
- Seleziona un documento di test.
- Fai clic sul pulsante Test Activity o Run.
- Attendi che l’LLM elabori il documento
- Tempo di elaborazione: di solito 5-30 secondi, a seconda della complessità del documento.
- Vedrai un indicatore di caricamento mentre attendi la risposta dell’API.
Verifica dei risultati
- L’interfaccia passa alla Predictive view.
- Esamina il pannello Output, che mostra i fields estratti.
- Fai clic su ogni field per vedere:
- Valore estratto
- Confidence (se disponibile)
- Area evidenziata sull’immagine del documento
- ✅ Tutti i fields attesi sono compilati
- ✅ I valori corrispondono esattamente al documento
- ✅ Nessun dato allucinato o dedotto
- ✅ Gestione corretta dei fields su più righe
- ✅ I fields mancanti vengono omessi (non compilati con dati errati)
Schemi di risultati comuni
Fase 10: perfeziona il tuo prompt
Problemi comuni e soluzioni
- Soluzione: Fornisci indicazioni di posizione più specifiche.
- Esempio: “Solo lato Fornitore; escludi indirizzi di clienti/acquirenti”
- Soluzione: Dai priorità all’estrazione letterale.
- Esempio: “Estrai il formato numerico esattamente come stampato (ad es. ‘12-34-56’)”
- Soluzione: Rendi più rigorose le regole.
- Esempio: “Non generare o inferire mai valori. Ometti se non presente.”
- Soluzione: Specifica le sequenze di escape.
- Esempio: “Per valori su più righe, usa
\nper le nuove righe”
- Soluzione: Verifica che i nomi dei field corrispondano esattamente.
- Esempio: Usa
Vendor.Account Numbere nonAccountNumber
Processo di miglioramento iterativo
- Esegui test su più documenti: Non ottimizzare sulla base di un singolo esempio.
- Documenta gli schemi: Annota quali regole funzionano e quali richiedono un perfezionamento.
- Aggiungi esempi specifici: Includi esempi di formato tra parentesi.
- Affina il livello di rigore: Regolalo in base agli schemi di sovra- o sottoestrazione.
- Verifica i casi limite: Prova con documenti con field mancanti o layout insoliti.
Esempi di affinamento
Comprendere il processo di estrazione
Come funziona l’estrazione basata su prompt
- Document Conversion: Il tuo documento viene convertito nel formato selezionato (consigliato: Annotated Text).
- Prompt Assembly: Il tuo ruolo, il formato di output, le regole dei field e le regole di rigidità vengono combinati.
- API Call: Il prompt e il documento vengono inviati al LLM tramite la tua connessione.
- LLM Processing: Il LLM legge il documento ed estrae i dati in base alle tue istruzioni.
- JSON Response: Il LLM restituisce dati strutturati nel formato JSON specificato.
- Field Mapping: Vantage associa la risposta JSON ai field di output da te definiti.
- Verification: I numeri di riga e i punteggi di affidabilità (se forniti) contribuiscono a verificare l’accuratezza.
Utilizzo dei token e costi
- Lunghezza del documento: i documenti più lunghi consumano più token.
- Complessità del prompt: i prompt più dettagliati aumentano il numero di token.
- Scelta del formato: Annotated Text è in genere più efficiente del PDF.
- Numero di field: più field = prompt più lunghi.
- Usa un linguaggio conciso ma chiaro nei prompt.
- Non ripetere le istruzioni.
- Rimuovi gli esempi non necessari.
- Valuta il raggruppamento dei field per dati correlati.
Procedure consigliate
Scrittura dei prompt
- ✅ Usa istruzioni chiare e all’imperativo (“Extract”, “Recognize”, “Omit”).
- ✅ Fornisci più varianti di etichetta per ogni field.
- ✅ Includi esempi di formato tra parentesi.
- ✅ Specifica cosa NON estrarre (esclusioni).
- ✅ Numera le tue regole per poterle richiamare facilmente.
- ✅ Usa una terminologia coerente in tutto il testo.
- ❌ Non usare istruzioni vaghe (“get the name”).
- ❌ Non dare per scontato che l’LLM conosca le convenzioni specifiche del dominio.
- ❌ Non scrivere frasi troppo lunghe e complesse.
- ❌ Non contraddirti in sezioni diverse.
- ❌ Non ignorare le regole sulla severità.
Definizioni dei Field
- Iniziare con i pattern di riconoscimento (etichette alternative).
- Specificare il formato esatto da preservare.
- Fornire indicazioni sulla posizione (collocazione tipica).
- Definire la titolarità dei dati (Fornitore vs Cliente).
- Includere le modalità di gestione dei valori su più righe.
- Fare riferimento a field correlati per evitare ambiguità.
Strategia di test
- Inizia con documenti semplici: verifica prima l’estrazione di base.
- Amplia alle varianti: prova layout e formati diversi.
- Verifica i casi limite: field mancanti, posizioni insolite, corrispondenze multiple.
- Documenta i casi di errore: conserva esempi dei casi in cui l’estrazione non riesce.
- Itera in modo sistematico: modifica un solo elemento alla volta.
Ottimizzazione delle prestazioni
- Mantieni i prompt concisi.
- Usa il formato Annotated Text.
- Riduci al minimo il numero di field per ogni attività.
- Valuta la suddivisione dei documenti complessi.
- Fornisci regole complete per i field.
- Includi esempi di formato.
- Aggiungi regole di severità stringenti.
- Esegui test con campioni di documenti diversi.
- Ottimizza la lunghezza del prompt.
- Usa formati di documento efficienti.
- Metti in cache i risultati quando appropriato.
- Monitora l’utilizzo dei token tramite la dashboard del provider LLM.
Risoluzione dei problemi
Problemi di estrazione
- Verificare che l’ortografia del nome del field corrisponda esattamente.
- Verificare che i dati siano nel formato di documento selezionato.
- Aggiungere più varianti di etichette ai pattern di riconoscimento.
- Ridurre temporaneamente il livello di severità per vedere se l’LLM li trova.
- Controllare se la qualità del documento influisce sull’estrazione OCR/testo.
- Rafforzare le specifiche relative al Fornitore.
- Aggiungere esclusioni esplicite per i dati del cliente/acquirente.
- Fornire indicazioni di posizione (ad es. “parte superiore del documento”, “sezione emittente”).
- Includere esempi di estrazione corretta vs. errata.
- Specificare esplicitamente il formato delle sequenze di escape (
\n). - Fornire esempi di output multilinea corretto.
- Verificare che il formato del documento preservi le interruzioni di riga.
- Aggiungere l’istruzione: “Conserva le interruzioni di riga originali utilizzando
\n”.
- Enfatizzare “verbatim” e “esattamente come stampato”.
- Aggiungere una regola di severità: “Nessuna normalizzazione o inferenza”.
- Fornire esempi specifici che mostrino la conservazione della formattazione.
- Includere esempi negativi: “Non ‘12-34-56’, mantieni ‘12 34 56’”.
Problemi di performance
- Passare al formato Annotated Text se si utilizza un PDF.
- Semplificare il prompt senza perdere le istruzioni critiche.
- Ridurre la risoluzione del documento se le immagini sono molto grandi.
- Verificare lo stato del provider LLM e i relativi rate limit.
- Valutare l’uso di un modello più veloce per i documenti semplici.
- Aumentare il livello di rigidità delle regole.
- Rendere le istruzioni più specifiche e prive di ambiguità.
- Aggiungere più esempi di formato.
- Ridurre la complessità del prompt che potrebbe lasciare spazio a interpretazioni.
- Testare con impostazioni di temperatura più elevate (se disponibili nella connessione configurata).
- Ottimizzare la lunghezza del prompt.
- Utilizzare Annotated Text invece di PDF.
- Elaborare i documenti in batch nelle fasce orarie di minor carico.
- Valutare l’uso di modelli più piccoli/economici per i documenti semplici.
- Monitorare e impostare avvisi di budget nel dashboard del provider LLM.
Tecniche avanzate
Estrazione condizionale
Supporto multilingue
Regole di validazione
Relazioni tra Field
Limitazioni e considerazioni
Funzionalità attuali
- ✅ Estrazione di field a livello di intestazione
- ✅ Valori su una o più righe
- ✅ Più field per documento
- ✅ Logica di estrazione condizionale
- ✅ Documenti multilingue
- ✅ Layout di documenti variabili
- ⚠️ Estrazione di tabelle (dipende dall’implementazione)
- ⚠️ Strutture complesse annidate
- ⚠️ Documenti molto grandi (limiti di token)
- ⚠️ Elaborazione in tempo reale (latenza API)
- ⚠️ Risultati completamente deterministici
Quando utilizzare l’estrazione basata su prompt
- Documenti con layout variabili
- Documenti semi-strutturati
- Prototipazione e test rapidi
- Volumi di documenti piccoli o medi
- Quando i dati di addestramento non sono disponibili
- Elaborazione di documenti multilingue
- Produzione ad alto volume (il machine learning tradizionale può essere più veloce)
- Moduli altamente strutturati (estrazione basata su template)
- Applicazioni sensibili ai costi (i metodi tradizionali possono essere più economici)
- Applicazioni con vincoli stringenti sulla latenza (le API LLM introducono una latenza di rete)
- Requisiti di elaborazione offline (nessuna connessione a Internet necessaria per i metodi tradizionali)
Integrazione con le Document skill
Utilizzo dei dati estratti
- Attività di convalida: applica regole di business ai valori estratti.
- Attività di script: elabora o trasforma i dati estratti.
- Attività di esportazione: invia i dati a sistemi esterni.
- Interfaccia di revisione: verifica manuale dei field estratti.
Utilizzo in combinazione con altre attività
Mapping dei field
"FieldName": "Vendor.Name"→ Viene mappato al field di outputVendor.Name.- La gerarchia dei field viene preservata nella struttura di output.
- I numeri di riga aiutano nella verifica e nella risoluzione dei problemi.
Riepilogo
- ✅ Creato un’attività di estrazione basata su prompt.
- ✅ Configurato una connessione LLM.
- ✅ Scritto un prompt di estrazione completo con ruolo, formato e regole.
- ✅ Selezionato il formato di documento ottimale (Annotated Text).
- ✅ Applicato regole di rigore per la qualità dei dati.
- ✅ Testato l’estrazione e revisionato i risultati.
- ✅ Appreso le best practice per la prompt engineering.
- L’estrazione basata su prompt utilizza istruzioni in linguaggio naturale.
- Il formato Annotated Text fornisce i risultati migliori.
- Prompt chiari e specifici garantiscono un’estrazione coerente.
- Le regole di rigore prevengono le allucinazioni e mantengono la qualità dei dati.
- Test iterativi e perfezionamento continuo migliorano l’accuratezza.
Prossimi passaggi
- Esegui test con un’ampia gamma di documenti: valida su layout e varianti differenti.
- Affina i tuoi prompt: migliorali continuamente in base ai risultati.
- Monitora i costi: tieni traccia dell’utilizzo di token nella dashboard del tuo provider LLM.
- Ottimizza le prestazioni: perfeziona i prompt per velocità e precisione.
- Esplora l’estrazione di tabelle: sperimenta con l’estrazione delle righe articolo (se supportata).
- Integra nei workflow: combina con altre attività per un’elaborazione completa.
Risorse aggiuntive
- Documentazione di ABBYY Vantage Advanced Designer: https://docs.abbyy.com
- Guida alla configurazione delle connessioni LLM: Come configurare le connessioni LLM.
- Best practice di Prompt Engineering: consulta la documentazione del tuo provider LLM.
- Supporto: contatta il supporto ABBYY per assistenza tecnica.
Domande frequenti
R: L’estrazione basata su prompt utilizza istruzioni in linguaggio naturale per LLM, senza dati di training. I metodi tradizionali richiedono esempi di training, ma sono più rapidi e più economici su larga scala. D: Posso estrarre tabelle con attività basate su prompt?
R: L’estrazione a livello di intestazione è ben supportata. Le funzionalità di estrazione delle tabelle possono variare e richiedere strutture di prompt specifiche. D: Perché usare Annotated Text invece del PDF?
R: Annotated Text offre il miglior equilibrio tra preservazione della struttura ed efficienza di elaborazione. I test hanno dimostrato che è l’opzione più affidabile. D: Come posso ridurre i costi dell’API?
R: Ottimizza la lunghezza dei prompt, usa il formato Annotated Text, elabora in modo efficiente e monitora l’utilizzo dei token tramite la dashboard del provider LLM. D: Cosa succede se la mia connessione LLM non funziona?
R: Verifica lo stato della connessione in Configuration → Connections. Prova la connessione, controlla le credenziali e assicurati che la quota della tua API non sia stata superata. D: Posso usare più connessioni LLM in una singola skill?
R: Sì, attività diverse possono usare connessioni diverse. Questo ti permette di usare modelli differenti per diverse attività di estrazione. D: Come gestisco i documenti in più lingue?
R: Aggiungi varianti multilingue delle etichette alle regole dei field. In generale, gli LLM gestiscono bene i contenuti multilingue. D: Qual è la dimensione massima di un documento?
R: Dipende dai limiti di token del tuo provider LLM. Documenti molto lunghi potrebbero dover essere suddivisi o elaborati in sezioni.