Visão geral
- Criar uma atividade de extração baseada em prompt
- Configurar uma conexão com um LLM
- Escrever prompts de extração eficazes
- Definir o formato e a estrutura de saída
- Aplicar nível de rigor e regras de validação
- Testar e aprimorar sua extração
- Extração de informações de Fornecedor a partir de faturas
- Captura de dados de documentos em nível de cabeçalho
- Processamento de documentos semiestruturados
- Documentos com layouts variáveis
Pré-requisitos
- Acesso ao ABBYY Vantage Advanced Designer
- Uma conexão LLM configurada (consulte Como configurar conexões LLM)
- Uma Skill de Documento com documentos de exemplo carregados
- Conhecimento básico da estrutura do JSON
- Definições de campos para os dados que você deseja extrair
Entendendo a extração baseada em prompts
O que é Extração Baseada em Prompt?
- Role: O papel que o LLM deve desempenhar (por exemplo, “modelo de extração de dados”)
- Instructions: Como extrair e formatar os dados
- Output Structure: O formato JSON exato para os resultados
- Rules: Diretrizes para lidar com dados ambíguos ou ausentes
Benefícios
- Nenhum dado de treinamento é necessário: Funciona apenas com engenharia de prompts
- Flexível: Fácil de adicionar ou modificar campos
- Lida com variações: LLMs conseguem entender diferentes formatos de documento
- Configuração rápida: Mais rápido do que treinar modelos tradicionais de aprendizado de máquina
- Linguagem natural: Escreva instruções em inglês simples
Limitações
- Custo: Cada extração usa chamadas à API de LLM
- Velocidade: Mais lenta que a extração tradicional para documentos simples
- Consistência: Os resultados podem variar ligeiramente entre diferentes execuções
- Limites de contexto: Documentos muito longos podem exigir tratamento especial
Etapa 1: Adicionar uma Atividade Baseada em Prompt
- Abra sua Skill de Documento no ABBYY Vantage Advanced Designer
- No painel esquerdo, localize EXTRACT FROM TEXT (NLP)
- Encontre e clique em Prompt-based
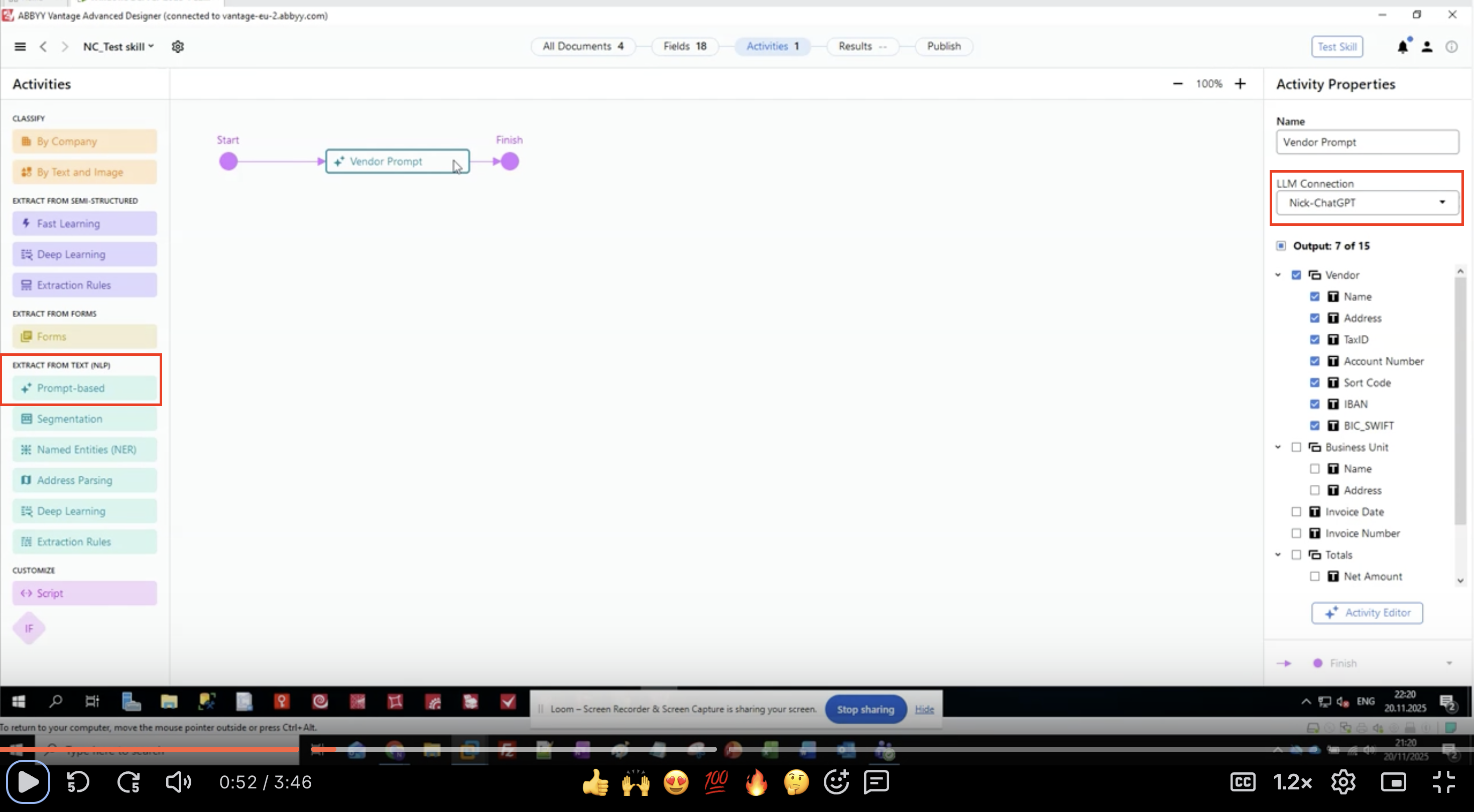
- A atividade aparece no canvas do seu fluxo de trabalho
- Conecte-a entre as atividades de entrada e saída
Etapa 2: Configurar a conexão de LLM
- Selecione a atividade baseada em prompt no seu fluxo de trabalho
- No painel Activity Properties à direita, localize LLM Connection
- Clique no menu suspenso
-
Selecione, na lista, a conexão de LLM que você configurou
- Exemplo:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Exemplo:
- Verifique se a conexão está selecionada
Etapa 3: Definir campos de saída
- No painel Activity Properties, localize a seção Output
- Você verá uma lista hierárquica de grupos de campos e campos
- Neste exemplo, estamos extraindo informações do Fornecedor:
- Fornecedor
- Name
- Address
- TaxID
- Número da conta
- Sort Code
- IBAN
- BIC_SWIFT
- Unidade de negócio
- Name
- Address
- Data da fatura
- Número da fatura
- Totais
- Montante líquido
- Fornecedor
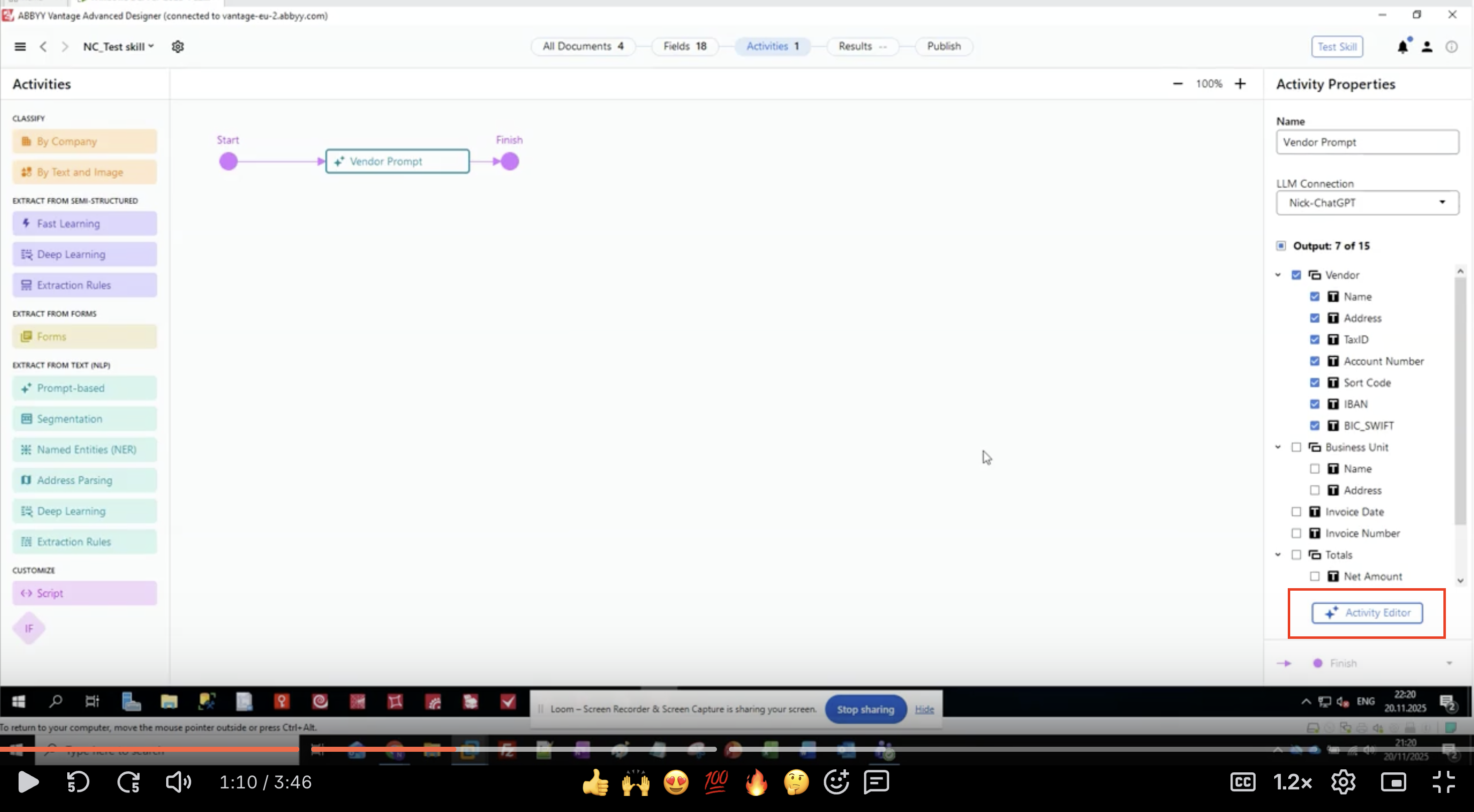
- Clique no botão Activity Editor para começar a configurar o prompt
Etapa 4: Definir a Função
- No Activity Editor, você verá a interface Prompt Text
- Comece pela seção ROLE:
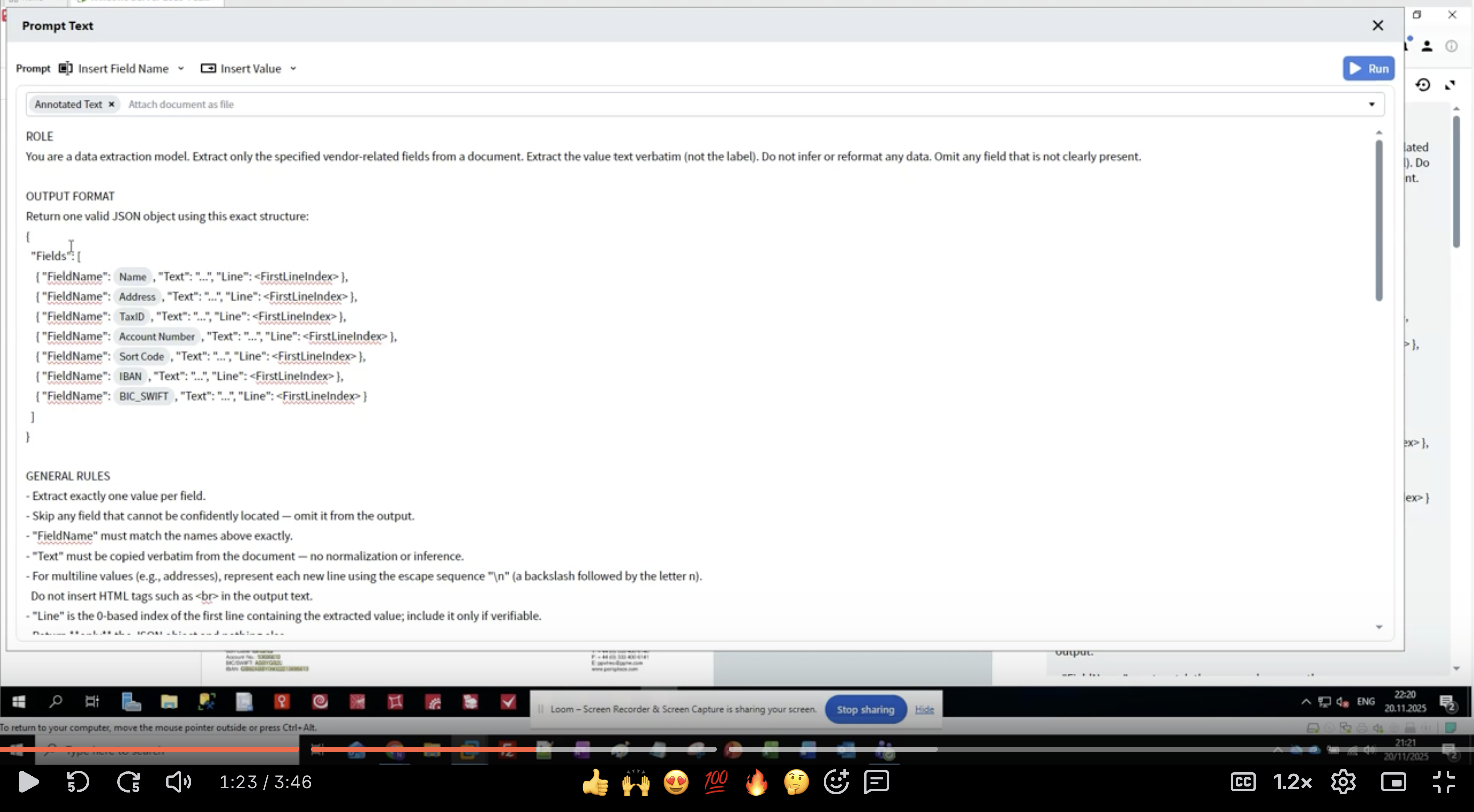
- Seja específico: “data extraction model” informa ao LLM seu propósito
- Defina o escopo: “vendor-related fields” limita o que extrair
- Defina expectativas: “value text verbatim” evita reformatar
- Trate dados ausentes: “Omit any field that is not clearly present”
- Mantenha o papel claro e conciso
- Use declarações no imperativo (“Extract”, “Do not infer”)
- Seja explícito sobre o que NÃO fazer
- Defina como lidar com casos de borda
Etapa 5: Definir o Formato de Saída
- Abaixo da seção ROLE, adicione o título OUTPUT FORMAT
- Defina a estrutura JSON:
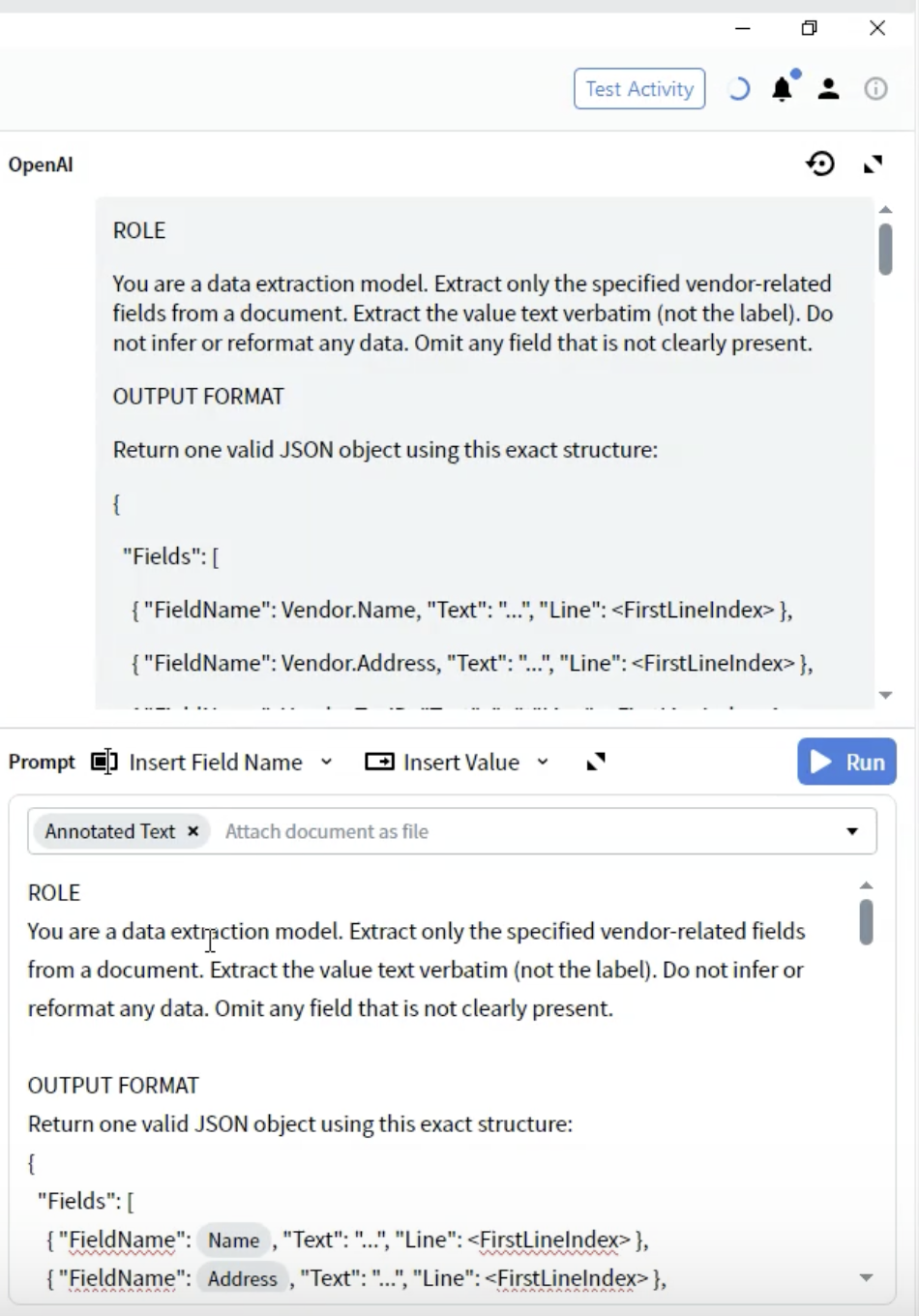
- FieldName: Deve corresponder exatamente às definições dos seus campos (por exemplo,
Vendor.Name) - Text: O valor extraído como uma string
- Line: Índice de linha baseado em zero em que o valor aparece no documento
- Use exatamente os nomes de campo da sua configuração de Output
- Inclua todos os campos, mesmo que alguns estejam vazios
- A estrutura deve ser um JSON válido
- Os números de linha ajudam na verificação e na solução de problemas
Etapa 6: Adicionar regras de extração específicas para cada Field
- Padrões de reconhecimento: liste rótulos alternativos para cada campo
- Especificações de formato: descreva o formato exato a ser extraído
- Dicas de localização: onde normalmente encontrar os dados
- Exclusões: o que NÃO deve ser extraído
- Numere suas regras para maior clareza
- Forneça diversas variações de rótulo
- Especifique a origem dos dados (lado do fornecedor vs. lado do cliente)
- Inclua exemplos de formato entre parênteses
- Seja explícito sobre campos relacionados (por exemplo, “Ignore o IBAN — ele tem seu próprio campo”)
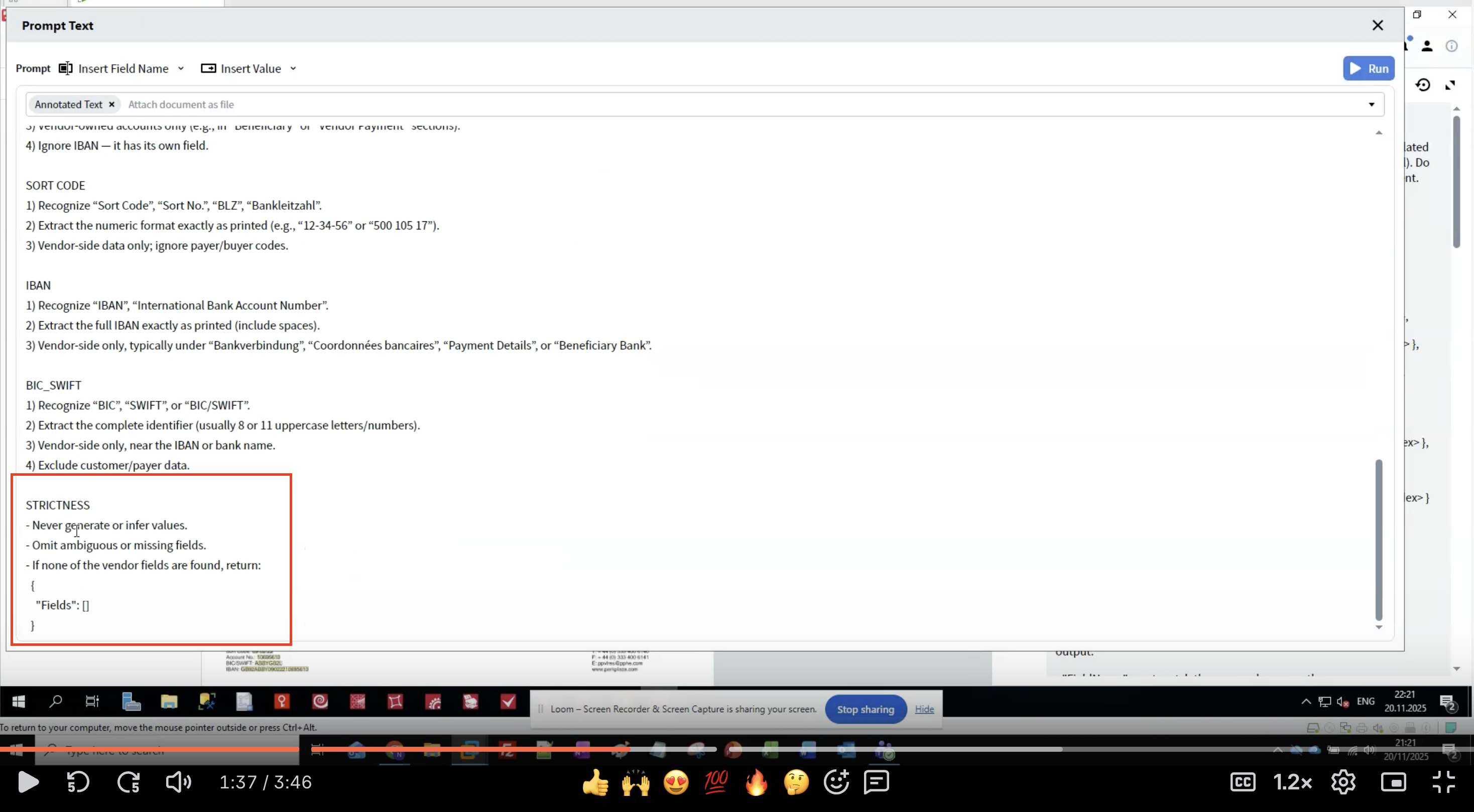
Etapa 7: Aplicar Regras de Rigor
- Evita alucinações: LLMs podem gerar dados plausíveis, porém incorretos
- Garante consistência: Regras claras reduzem a variação entre execuções
- Lida com dados ausentes: Define o que fazer quando campos não são encontrados
- Mantém a integridade dos dados: Extração literal preserva a formatação original
- Nunca gerar dados que não estejam no documento
- Omitir extrações incertas em vez de adivinhar
- Retornar uma estrutura vazia se nenhum campo for encontrado
- Usar exatamente os mesmos nomes de campos
- Preservar a formatação original do texto
Etapa 8: Selecionar formato do documento
- No Activity Editor, localize a lista suspensa Prompt
- Você verá opções de como o documento será fornecido ao LLM
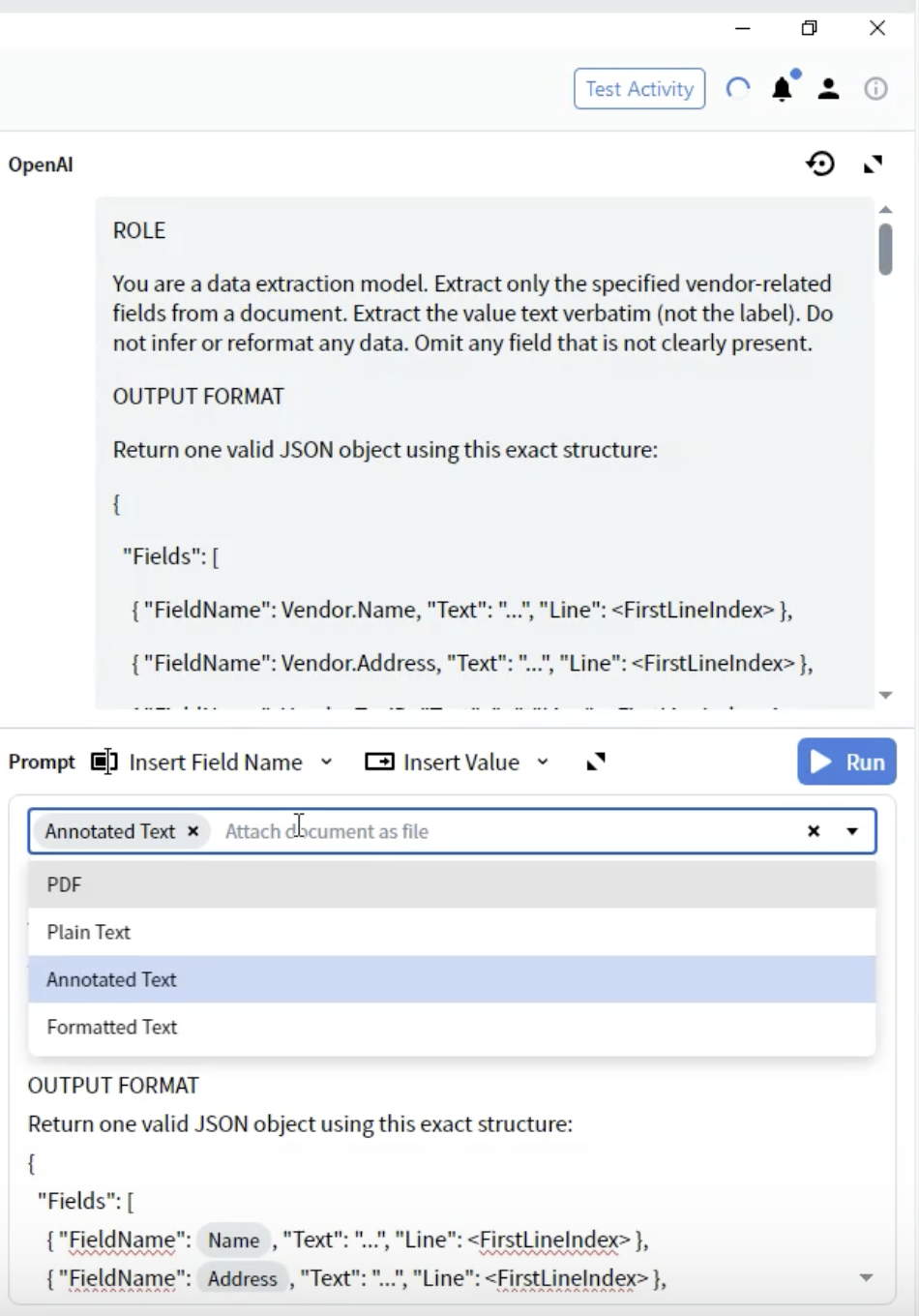
-
PDF: Arquivo PDF original
- Use para: Documentos em que o layout é crítico
- Considerações: Arquivo de tamanho maior; alguns LLMs têm suporte limitado a PDF
-
Plain Text: Extração de texto sem formatação
- Use para: Documentos simples, somente texto
- Considerações: Perde toda a formatação e as informações de layout
-
Annotated Text ⭐ (Recomendado)
- Use para: A maioria dos tipos de documento
- Considerações: Preserva a estrutura, embora seja baseado em texto
- Benefícios: Melhor equilíbrio entre estrutura e desempenho
-
Formatted Text: Texto com formatação básica preservada
- Use para: Documentos em que alguma formatação é importante
- Considerações: Meio-termo entre Plain e Annotated
- Selecione Annotated Text para obter os melhores resultados
Etapa 9: Teste sua extração
Executar a Activity
- Feche o Activity Editor
- Navegue até a guia All Documents
- Selecione um documento de teste
- Clique no botão Test Activity ou Run
- Aguarde o LLM processar o documento
- Tempo de processamento: normalmente de 5 a 30 segundos, dependendo da complexidade do documento
- Você verá um indicador de carregamento enquanto aguarda a resposta da API
Revisar resultados
- A interface muda para a Predictive view
- Revise o painel Output, que exibe os campos extraídos
- Clique em cada campo para ver:
- Valor extraído
- Confiança (se disponível)
- Região destacada na imagem do documento
- ✅ Todos os campos esperados estão preenchidos
- ✅ Os valores correspondem exatamente ao documento
- ✅ Não há dados alucinados ou inferidos
- ✅ Tratamento adequado de campos multilinha
- ✅ Campos ausentes são omitidos (não são preenchidos com dados incorretos)
Padrões comuns de resultados
Etapa 10: Aprimore seu prompt
Problemas Comuns e Soluções
- Solução: Adicione indicações de localização mais específicas
- Exemplo: “Apenas do lado do Fornecedor; exclua os endereços do cliente/comprador”
- Solução: Reforce a extração literal
- Exemplo: “Extraia o formato numérico exatamente como impresso (por exemplo, ‘12-34-56’)”
- Solução: Reforce as regras de rigor
- Exemplo: “Nunca gere ou infira valores. Omita se não estiver presente.”
- Solução: Especifique as sequências de escape
- Exemplo: “Para valores multilinha, use
\npara quebras de linha”
- Solução: Verifique se os nomes de campo correspondem exatamente
- Exemplo: Use
Vendor.Account Numbere nãoAccountNumber
Processo iterativo de melhoria
- Teste com vários documentos: Não otimize para um único exemplo
- Documente os padrões: Anote quais regras funcionam e quais precisam de refinamento
- Adicione exemplos específicos: Inclua exemplos de formatos entre parênteses
- Refine o nível de rigor: Ajuste com base em padrões de extração excessiva ou insuficiente
- Teste casos-limite: Experimente documentos com campos ausentes e layouts incomuns
Exemplos de melhorias
Compreendendo o processo de extração
Como funciona a extração baseada em prompts
- Conversão do documento: Seu documento é convertido para o formato selecionado (Annotated Text recomendado)
- Montagem do prompt: Seu papel, o formato de saída, as regras de campo e as regras de estrita observância são combinados
- Chamada de API: O prompt e o documento são enviados para o LLM por meio da sua conexão
- Processamento pelo LLM: O LLM lê o documento e extrai os dados de acordo com suas instruções
- Resposta JSON: O LLM retorna dados estruturados no formato JSON especificado
- Mapeamento de campos: O Vantage mapeia a resposta JSON para os campos de saída que você definiu
- Verificação: Números de linha e escores de confiança (se fornecidos) ajudam a verificar a precisão
Uso de tokens e custos
- Tamanho do documento: Documentos mais longos usam mais tokens
- Complexidade do prompt: Prompts detalhados aumentam a contagem de tokens
- Escolha do formato: Annotated Text é geralmente mais eficiente do que PDF
- Número de campos: Mais campos = prompts mais longos
- Use uma linguagem clara e concisa nos prompts
- Não duplique instruções
- Remova exemplos desnecessários
- Considere agrupar campos para dados relacionados
Melhores práticas
Criação de prompts
- ✅ Use instruções claras, no imperativo (“Extract”, “Recognize”, “Omit”)
- ✅ Forneça várias opções de rótulo para cada campo
- ✅ Inclua exemplos de formato entre parênteses
- ✅ Especifique o que NÃO deve ser extraído (exclusões)
- ✅ Numere suas regras para facilitar a referência
- ✅ Use uma terminologia consistente em todo o texto
- ❌ Usar instruções vagas (“get the name”)
- ❌ Presumir que o LLM conhece convenções específicas do domínio
- ❌ Escrever frases excessivamente longas e complexas
- ❌ Entrar em contradição em seções diferentes
- ❌ Ignorar regras de rigor (strictness)
Definições de campos
- Comece com padrões de reconhecimento (rótulos alternativos)
- Especifique o formato exato a ser preservado
- Forneça indicações de localização (posicionamento típico)
- Defina a responsabilidade sobre os dados (fornecedor vs. cliente)
- Inclua o tratamento de valores em várias linhas
- Faça referência a campos relacionados para evitar confusão
Estratégia de testes
- Comece com documentos simples: Teste primeiro a extração básica
- Amplie para variações: Experimente diferentes layouts e formatos
- Teste casos limite: Campos ausentes, posições incomuns, múltiplas correspondências
- Registre as falhas: Mantenha exemplos de onde a extração falha
- Itere de forma sistemática: Altere um elemento de cada vez
Otimização de desempenho
- Mantenha os prompts concisos
- Use o formato Annotated Text
- Minimize o número de campos por atividade
- Considere dividir documentos complexos
- Forneça regras abrangentes para campos
- Inclua exemplos de formato
- Adicione regras de validação mais rígidas
- Teste com amostras de documentos diversos
- Otimize o comprimento do prompt
- Use formatos de documento eficientes
- Armazene em cache os resultados quando apropriado
- Monitore o uso de tokens no painel do provedor de LLM
Solução de problemas
Problemas de Extração
- Verifique se a grafia do nome do campo corresponde exatamente
- Verifique se os dados estão no formato de documento selecionado
- Adicione mais variações de rótulos aos padrões de reconhecimento
- Reduza o rigor temporariamente para ver se o LLM encontra os dados
- Verifique se a qualidade do documento afeta a extração de OCR/texto
- Reforce as especificações do lado do fornecedor
- Adicione exclusões explícitas para dados de cliente/comprador
- Forneça dicas de localização (por exemplo, “topo do documento”, “seção do emissor”)
- Inclua exemplos de extração correta vs. incorreta
- Especifique explicitamente o formato da sequência de escape (
\n) - Forneça exemplos de saída multilinha correta
- Verifique se o formato do documento preserva as quebras de linha
- Adicione a instrução: “Preserve as quebras de linha originais usando
\n”
- Enfatize “verbatim” e “exatamente como impresso”
- Adicione uma regra rígida: “Sem normalização ou inferência”
- Forneça exemplos específicos mostrando a preservação da formatação
- Inclua exemplos negativos: “Não ‘12-34-56’, mantenha como ‘12 34 56‘“
Problemas de desempenho
- Altere para o formato Annotated Text se estiver usando PDF
- Simplifique o prompt sem perder instruções essenciais
- Reduza a resolução do documento se as imagens forem muito grandes
- Verifique o status do provedor de LLM e os limites de requisições
- Considere usar um modelo mais rápido para documentos simples
- Torne as regras de validação mais rígidas
- Torne as instruções mais específicas e sem ambiguidades
- Adicione mais exemplos de formato
- Reduza a complexidade do prompt que possa levar a diferentes interpretações
- Teste com configurações de temperature mais altas (se disponível na integração)
- Otimize o tamanho do prompt
- Use Annotated Text em vez de PDF
- Processe documentos em lotes fora do horário de pico
- Considere usar modelos menores/mais baratos para documentos simples
- Monitore e configure alertas de orçamento no painel do provedor de LLM
Técnicas avançadas
Extração condicional
Suporte multilíngue
Regras de validação
Relações entre campos
Limitações e considerações
Capacidades atuais
- ✅ Extração de campo em nível de cabeçalho
- ✅ Valores de linha única e multilinha
- ✅ Vários campos por documento
- ✅ Lógica de extração condicional
- ✅ Documentos em vários idiomas
- ✅ Layouts de documentos variáveis
- ⚠️ Extração de tabelas (varia conforme a implementação)
- ⚠️ Estruturas complexas aninhadas
- ⚠️ Documentos muito grandes (limites de tokens)
- ⚠️ Processamento em tempo real (latência da API)
- ⚠️ Garantia de resultados determinísticos
Quando usar a extração baseada em prompt
- Documentos com layouts variáveis
- Documentos semiestruturados
- Prototipagem e testes rápidos
- Pequenos a médios volumes de documentos
- Quando não há dados de treinamento disponíveis
- Processamento de documentos em vários idiomas
- Produção em grande volume (ML tradicional pode ser mais rápido)
- Formulários altamente estruturados (extração baseada em templates)
- Aplicações sensíveis a custos (métodos tradicionais podem ser mais baratos)
- Aplicações com requisitos críticos de latência (APIs de LLMs têm atraso de rede)
- Requisitos de processamento offline (os métodos tradicionais não exigem conexão à internet)
Integração com Skills de Documento
Usando Dados Extraídos
- Atividades de Validação: Aplicar regras de negócio aos valores extraídos
- Atividades de Script: Processar ou transformar dados extraídos
- Atividades de Exportação: Enviar dados para sistemas externos
- Interface de Revisão: Verificação manual dos campos extraídos
Combinar com outras atividades
Mapeamento de campos
"FieldName": "Vendor.Name"→ É mapeado para o campo de saídaVendor.Name- A hierarquia de campos é preservada na estrutura de saída
- Os números de linha ajudam na verificação e solução de problemas
Resumo
- ✅ Criou uma atividade de extração baseada em prompt
- ✅ Configurou uma conexão com um LLM
- ✅ Escreveu um prompt de extração abrangente com papel, formato e regras
- ✅ Selecionou o formato de documento ideal (Annotated Text)
- ✅ Aplicou regras de rigor para garantir a qualidade dos dados
- ✅ Testou a extração e revisou os resultados
- ✅ Aprendeu práticas recomendadas para engenharia de prompts
- A extração baseada em prompt usa instruções em linguagem natural
- O formato Annotated Text oferece os melhores resultados
- Prompts claros e específicos produzem extrações consistentes
- Regras de rigor evitam alucinações e mantêm a qualidade dos dados
- Testes e refinamentos iterativos melhoram a precisão
Próximas etapas
- Teste com documentos variados: Valide em diferentes layouts e variações
- Refine seus prompts: Melhore continuamente com base nos resultados
- Monitore os custos: Acompanhe o uso de tokens no painel do seu provedor de LLM
- Otimize o desempenho: Ajuste seus prompts para obter mais velocidade e precisão
- Explore a extração de tabelas: Experimente extrair itens (se houver suporte)
- Integre com fluxos de trabalho: Combine com outras atividades para um processamento completo
Recursos adicionais
- Documentação do ABBYY Vantage Advanced Designer: https://docs.abbyy.com
- Guia de configuração de conexões com LLM: Como configurar conexões com LLM
- Boas práticas de engenharia de prompts (Prompt Engineering): Consulte a documentação do provedor de LLM que você utiliza
- Suporte: Entre em contato com o suporte da ABBYY para obter assistência técnica