跳转到主要内容模糊区间是一种工具,用于让程序基于长度评估某个假设的质量。模糊区间可以用长度单位(点、毫米等)或字符数(用于文本行的情况)来度量。对于一个模糊区间,必须指定四个值,以确定可能范围和最佳范围。为便于使用,程序提供了直观的模糊区间编辑器。
假设有一个模糊区间 {f1,f2,f3,f4},检测到的字符串长度(对于空白则为点数)为 L。如果长度 L 位于 f2 到 f3 之间(即 L>=f2 and L<=f3),则该假设的质量为 1。若长度位于 f1 到 f2 之间,则该假设的质量按比例从 0 线性增加至 1(Quality(f1) = 0, Quality(f2)=1)。同样地,若长度位于 f3 到 f4 之间,则该假设的质量按比例从 1 线性降低至 0(Quality(f3) = 1, Quality(f4) = 0)。如果长度不在 f1 到 f4 的范围内(即 L<f1 or L>f4),则该假设的质量为 0(Quality(L) = 0)。检测对象的假设质量还会与 Character count 属性的取值相乘,该属性会根据检测对象的长度进行选择。
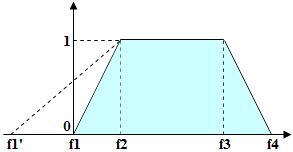
注意: 多个元素组成的任何假设链的质量,均通过将链中各元素的假设质量相乘来计算。如果链足够长,且由于限制过于严格导致各个假设的质量评估偏低,那么整条链的最终质量也可能过低。
因此,建议确保所选假设的质量评估尽可能高。另一方面,你还需要能够根据质量区分不同假设,以便选择最佳方案。为此,应当以不过度惩罚可接受假设为原则,合理设置模糊区间(用于假设评估的数学函数)。
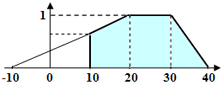
模糊区间的左边界也可以取负值(尽管实际并不存在负长度的字符串)。这有助于在 (0, 1) 区间内使质量曲线不那么陡峭,从而降低质量惩罚。如果需要为该参数设置下限(例如,字符串长度不能小于 10 个字符,且字符串长度的模糊区间为 [-10,20,30,40}),可以直接在 Hypothesis Evaluation 中设置 Value.Length >= 10 来实现。
 我们不建议将区间边界设置得过于严格。这在处理质量不一的图像时尤为重要。例如,在某些图像上,由于源文档质量较差或扫描设置的原因,可能会在空白处出现夹带字母的情况。在这种情况下,程序可能会将一个字符识别为多个字符,若区间过于严格,就可能导致假设质量大幅下降。结果,程序可能会丢弃该假设(尽管其本质可能是正确的),而选择另一个假设。因此,如果需要通过比较长度在假设之间进行选择,应在 Hypothesis Evaluation 中结合其他附加条件来完成。
我们不建议将区间边界设置得过于严格。这在处理质量不一的图像时尤为重要。例如,在某些图像上,由于源文档质量较差或扫描设置的原因,可能会在空白处出现夹带字母的情况。在这种情况下,程序可能会将一个字符识别为多个字符,若区间过于严格,就可能导致假设质量大幅下降。结果,程序可能会丢弃该假设(尽管其本质可能是正确的),而选择另一个假设。因此,如果需要通过比较长度在假设之间进行选择,应在 Hypothesis Evaluation 中结合其他附加条件来完成。