ABBYY Vantage 允许您使用托管在 Vantage 服务器上的共享文件夹,用于导入和导出文档和 Skill,以及更新数据目录(data catalog)。
在开始使用共享文件夹(NFS 共享)之前,您需要在客户端计算机上配置与这些共享文件夹的连接。请在运行 Windows 的客户端计算机上执行以下步骤:
- 以管理员身份运行 Windows PowerShell。
- 安装 Windows NFS Client:
dism /online /Enable-Feature /FeatureName:ServicesForNFS-ClientOnly
dism /online /Enable-Feature /FeatureName:ClientForNFS-Infrastructure
- 根据贵公司的策略,配置 Windows 用户与 Unix UID 和 GID 之间的映射:
New-ItemProperty -Path "HKLM:\Software\Microsoft\ClientForNFS\CurrentVersion\Default" -Name "AnonymousGid" -Value 65532 -PropertyType DWord
New-ItemProperty -Path "HKLM:\Software\Microsoft\ClientForNFS\CurrentVersion\Default" -Name "AnonymousUid" -Value 65532 -PropertyType DWord
- 重启 NFS 客户端:
nfsadmin client stop
nfsadmin client start
开始之前,请确保已安装 kubectl 命令行工具,并且已建立与 Kubernetes 集群的连接。
- 运行以下命令以访问 Consul Web 界面:
kubectl port-forward -n abbyy-infrastructure service/consul-ui 8500:80
http://localhost:8500/ui/dc1/kv/secret/。
- 使用打开的 Key/Value 选项卡来选择正确的 Vantage 环境。
- 选择 platform 或 vantage 项目之一,以及使用该数据库的相应服务(例如 mail)。
- 转到每个服务都包含的 database 部分。
- 打开 SqlServer 部分。
- 在 connectionString 键下:
- 将 Server 的旧值替换为新服务器的地址
- 在 Database 参数中指定新的数据库
- 在 User Id 和 Password 参数中指定登录凭据
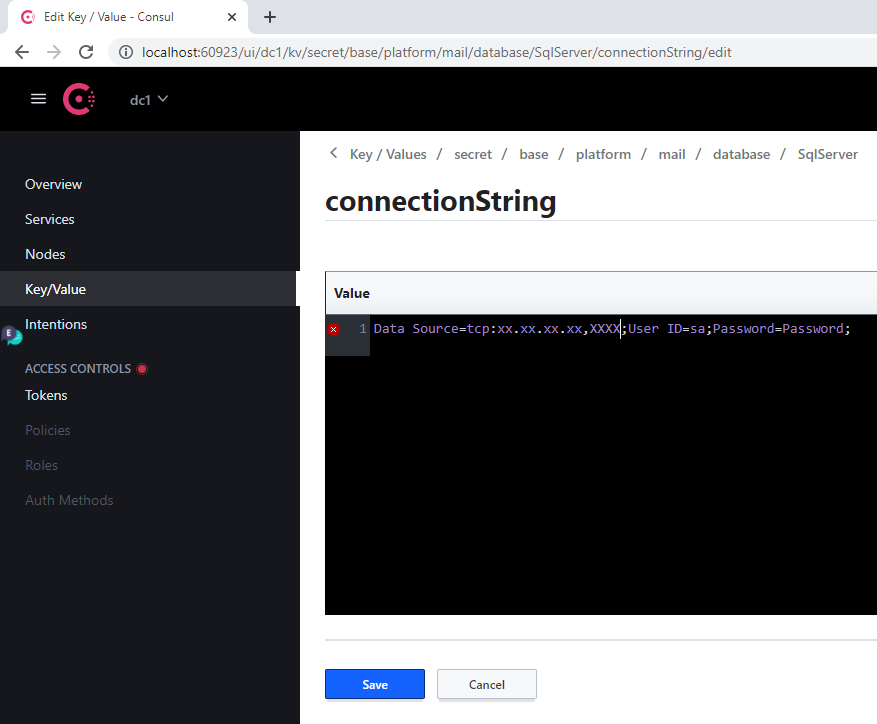
- 单击 Save。
- 通过运行以下命令重新启动已修改的服务:
label=mail
kubectl -n abbyy-vantage rollout restart $(kubectl -n abbyy-vantage get deployments -l app.kubernetes.io/component=$label -o name)
当服务器地址发生变化时,必须对每个数据库执行此操作。
| Consul 区段名称 | 服务标签 | 备注 |
|---|
| api-gateway-registry | api-gateway-registry | |
| api-registry | api-registry | |
| auth-adminapi2 | auth-adminapi2 | |
| auth-identity | auth-identity | |
| auth | auth-sts-identity, auth-adminapi2 | 此数据库由两个服务使用 |
| blob-storage | blob-storage | |
| cron-service | cron-service | |
| documentsetstorage | documentsetstorage | |
| mail | mail | |
| security-audit | security-audit | |
| storage | storage | 数据库区段存储在 fileMetadata 数据目录(data catalog)中 |
| workflow-facade | workflow-facade | |
| workflow-scheduler | workflow-scheduler | |
| Consul 区段名称 | 服务标签 |
|---|
| catalogstorage | catalogstorage |
| folderimport | folderimport |
| interactive-jobs | interactive-jobs |
| mailimport | mailimport |
| permissions | permissions |
| publicapi | publicapi |
| reporting | reporting |
| secretstorage | secretstorage |
| skill-monitor | skill-monitor |
| skillinfo | skillinfo |
| subscriptions | subscriptions |
| tokenmanagement | tokenmanagement |
| transactions | transactions |
| workspace | workspace |
- 虚拟 GPU 的最小显存:12 GB
- 主机上每个虚拟 GPU 至少需要 1 个 CPU 和 4 GB 内存(例如,一台具有单个 12 GB 虚拟 GPU 的虚拟机必须至少配备 2 个 CPU 和 8 GB 内存)
您可以使用虚拟 GPU(vGPU)将一块物理 GPU 划分为多个虚拟机使用,从而更高效地利用 Vantage 资源。
要设置 vGPU:
- 将 nVidia GRID 驱动程序包从 nVidia application hub 复制到带有 GPU 的虚拟机上,并运行以下命令:
apt-get update
apt-get install dkms
dpkg -i nvidia-linux-grid-535_535.54.03_amd64.deb
-
在 Kubernetes 集群上安装 nVidia GPU Operator:
a. 在运行 Vantage 安装程序容器之前,将许可证令牌文件(在 nVidia application hub 中生成)放在
$PWD/gpu/ 文件夹中。
b. 在运行 Vantage 安装程序容器的命令中添加参数 -v $PWD/gpu:/ansible/files/gpu:ro:
docker run -it \
-v $PWD/kube:/root/.kube \
-v $PWD/ssh/ansible:/root/.ssh/ansible \
-v "//var/run/docker.sock:/var/run/docker.sock" \
-v $PWD/inventory:/ansible/inventories/k8s/inventory \
-v $PWD/env_specific.yml:/ansible/inventories/k8s/group_vars/all/env_specific.yml \
-v $PWD/ssl:/ansible/files/ssl:ro \
-v $PWD/gpu:/ansible/files/gpu:ro \
--privileged \
registry.local/vantage/vantage-k8s:2.7.1
[abbyy_workers] 组中添加一个 GPU 节点。该 GPU 虚拟机的名称必须包含 “gpu”:
[abbyy_workers]
worker16-48-w01 ansible_host=10.10.10.27
worker16-48-w02 ansible_host=10.10.10.21
worker16-48-w03 ansible_host=10.10.10.20
worker2-12-a40-gpu01 ansible_host=10.10.10.60
chmod 600 /root/.ssh/ansible
ansible-playbook -i inventories/k8s -v playbooks/4-Kubernetes-k8s.yml
- 运行以下 Playbook 来配置 vGPU:
ansible-playbook -i inventories/k8s -v playbooks/setup-gpu-node.yml
- 运行 Vantage 安装程序容器:
docker run -it \
-v $PWD/kube:/root/.kube \
-v $PWD/ssh/ansible:/root/.ssh/ansible \
-v "//var/run/docker.sock:/var/run/docker.sock" \
-v $PWD/inventory:/ansible/inventories/k8s/inventory \
-v $PWD/env_specific.yml:/ansible/inventories/k8s/group_vars/all/env_specific.yml \
-v $PWD/ssl:/ansible/files/ssl:ro \
--privileged \
registry.local/vantage/vantage-k8s:2.7.1
- 在清单文件的
[abbyy_workers] 组中添加一个 GPU 节点(例如 worker2-12-a40-gpu01):
[abbyy_workers]
worker16-48-w01 ansible_host=10.10.10.27
worker16-48-w02 ansible_host=10.10.10.21
worker16-48-w03 ansible_host=10.10.10.20
worker2-12-a40-gpu01 ansible_host=10.10.10.60
- 运行 Playbook:
ansible-playbook -i inventories/k8s -v playbooks/4-Kubernetes-k8s.yml
- 安装 GPU Operator 的 Helm Chart:
helm upgrade --install gpu-operator ansible/files/helm/charts/gpu-operator --create-namespace --debug -n gpu-operator
- 为节点添加污点:
kubectl taint nodes worker2-12-a40-gpu01 nvidia.com/gpu:NoSchedule
- 运行以下命令:
kubectl apply -f filename
- 创建一个包含以下内容的 YAML 文件并将其应用:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
namespace: gpu-operator
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # 请求 1 个 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
- key: k8s.abbyy.com/techcore
effect: NoSchedule
value: "true"
- 检查 pod 日志。您应能看到一条包含
Test PASSED 的响应:
kubectl -n gpu-operator logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
- 将以下参数添加到
env_specific.yml 文件中:
techcore:
use_gpu_workers: true
use_nn_extraction_training_workers: true
- 执行以下操作之一:
- 如果已经安装了 Vantage,请运行以下 playbook 以部署 GPU worker:
ansible-playbook -i inventories/k8s -v playbooks/11-DeployWorkers-k8s.yml
- 如果尚未安装 Vantage,GPU worker 会在安装过程中一并部署。
在人工校验中,如果操作员在某个打开的任务上 15 分钟内未执行任何操作,将触发超时。系统管理员可以通过 Consul 修改触发超时所需的空闲时长。
要配置超时时间:
- 运行以下命令访问 Consul Web 界面:
kubectl port-forward -n abbyy-infrastructure service/consul-ui 8500:80
http://localhost:8500/ui/dc1/kv/secret/。
- 使用 Key/Value 选项卡选择正确的 Vantage 环境。
- 修改以下键的值:
| Key | Description |
|---|
secret/abbyy-vantage/vantage/verification/interactiveJobsOptions/popTimeout | 用户保持不活动状态的最短时间段,超过该时间后,任务将被退回到交互式任务队列。任何交互操作(鼠标移动、键盘输入、补丁处理等)都会重置倒计时。默认值:00:15:00(15 分钟) |
secret/abbyy-vantage/vantage/verification/interactiveJobsOptions/processingPopTimeout | 在存在长时间运行操作(应用 Skill、翻页等)时,用户保持不活动状态的最短时间段,超过该时间后,任务将被退回到队列。当长时间运行操作开始时,此值会被设置为允许的不活动时长上限。操作完成后,不活动时长将重置为 popTimeout 的值。默认值:1.00:00:00(24 小时) |
- 点击 Save。
- 重启 verification 和 manualverification 服务:
kubectl -n abbyy-vantage rollout restart $(kubectl -n abbyy-vantage get deployments -l app.kubernetes.io/component=verification -o name)
kubectl -n abbyy-vantage rollout restart $(kubectl -n abbyy-vantage get deployments -l app.kubernetes.io/component=manualverification -o name)
- 转到 Config > Secrets,找到所有名为
platform-wildcard 的 secret。
- 对于每个 secret,找到 Data 子部分,单击 Show 图标,并更新其中的值:
- 在
tls.crt field 中输入新证书的值
- 在
tls.key field 中输入其密钥的值
证书和密钥必须是内容为 base64 ASCII 编码(PKCS#8)的 PEM 文件。证书应以 -----BEGIN CERTIFICATE----- 开头,密钥应以 -----BEGIN PRIVATE KEY----- 开头。
- 单击 Save。
- 确保您能够访问 Kubernetes 集群:
- 将证书和密钥以 PEM 格式放在当前文件夹中:
cert.pem、key.pem。
如有需要,将你的 CRT 文件转换为 PEM 格式:
-----BEGIN CERTIFICATE-----
[your certificate]
-----END CERTIFICATE-----
-----BEGIN PRIVATE KEY-----
[your key]
-----END PRIVATE KEY-----
- 运行以下命令:
for i in `kubectl get secret --field-selector metadata.name=platform-wildcard -o custom-columns=:metadata.namespace -A --no-headers 2>/dev/null`; do kubectl patch secret platform-wildcard -p "{\"data\":{\"tls.key\":\"$(base64 < "./key.pem" | tr -d '\n')\", \"tls.crt\":\"$(base64 < "./cert.pem" | tr -d '\n')\"}}" -n $i; done
kubectl rollout restart deployment -n abbyy-infrastructure $(kubectl get deployment -n abbyy-infrastructure -o custom-columns=NAME:metadata.name --no-headers 2>/dev/null | grep ingress-nginx-controller)