Übersicht
- Erstellen einer promptbasierten Extraktionsaktivität.
- Konfigurieren einer LLM-Verbindung.
- Schreiben effektiver Extraktions-Prompts.
- Definieren von Ausgabeformat und -struktur.
- Anwenden von Striktheitsgrad und Validierungsregeln.
- Testen und Verfeinern Ihrer Extraktion.
- Extraktion von Vendor-Informationen aus Rechnungen
- Erfassung von Dokumentdaten auf Kopfzeilenebene
- Verarbeitung halbstrukturierter Dokumente
- Dokumente mit variablen Layouts
Voraussetzungen
- Zugriff auf ABBYY Vantage Advanced Designer.
- Eine konfigurierte LLM-Verbindung. Siehe Konfigurieren von LLM-Verbindungen.
- Ein Document-Skill mit geladenen Beispieldokumenten.
- Grundlegendes Verständnis der JSON-Struktur.
- Felddefinitionen für die Daten, die Sie extrahieren möchten.
Dieser Leitfaden konzentriert sich auf die Extraktion auf Kopfzeilenebene. Die Möglichkeiten zur Tabellenextraktion können variieren.
Grundlagen der promptbasierten Extraktion
Was ist promptbasierte Extraktion?
- Rolle: Welche Rolle das LLM einnehmen soll (z. B. „Datenextraktionsmodell“).
- Anweisungen: Wie Daten extrahiert und formatiert werden sollen.
- Ausgabestruktur: Das genaue JSON-Format für die Ergebnisse.
- Regeln: Richtlinien für den Umgang mit mehrdeutigen oder fehlenden Daten.
Vorteile
- Keine Trainingsdaten erforderlich: Kommt allein mit Prompt-Engineering aus.
- Flexibel: Felder lassen sich leicht hinzufügen oder ändern.
- Robust gegenüber Varianten: LLMs können unterschiedliche Dokumentformate verstehen.
- Schnelle Einrichtung: Schneller als das Trainieren herkömmlicher ML-Modelle.
- Natürliche Sprache: Formulieren Sie Anweisungen in einfachem Englisch.
Einschränkungen
- Kosten: Jede Extraktion nutzt LLM-API-Aufrufe.
- Geschwindigkeit: Langsamer als die herkömmliche Extraktion für einfache Dokumente.
- Konsistenz: Ergebnisse können zwischen einzelnen Durchläufen leicht variieren.
- Kontextbeschränkungen: Sehr lange Dokumente müssen möglicherweise speziell behandelt werden.
Schritt 1: Eine Prompt-basierte Aktivität hinzufügen
- Öffnen Sie Ihren Document-Skill in ABBYY Vantage Advanced Designer.
- Suchen Sie im linken Bereich EXTRACT FROM TEXT (NLP).
- Suchen Sie den Eintrag Prompt-based und klicken Sie darauf.
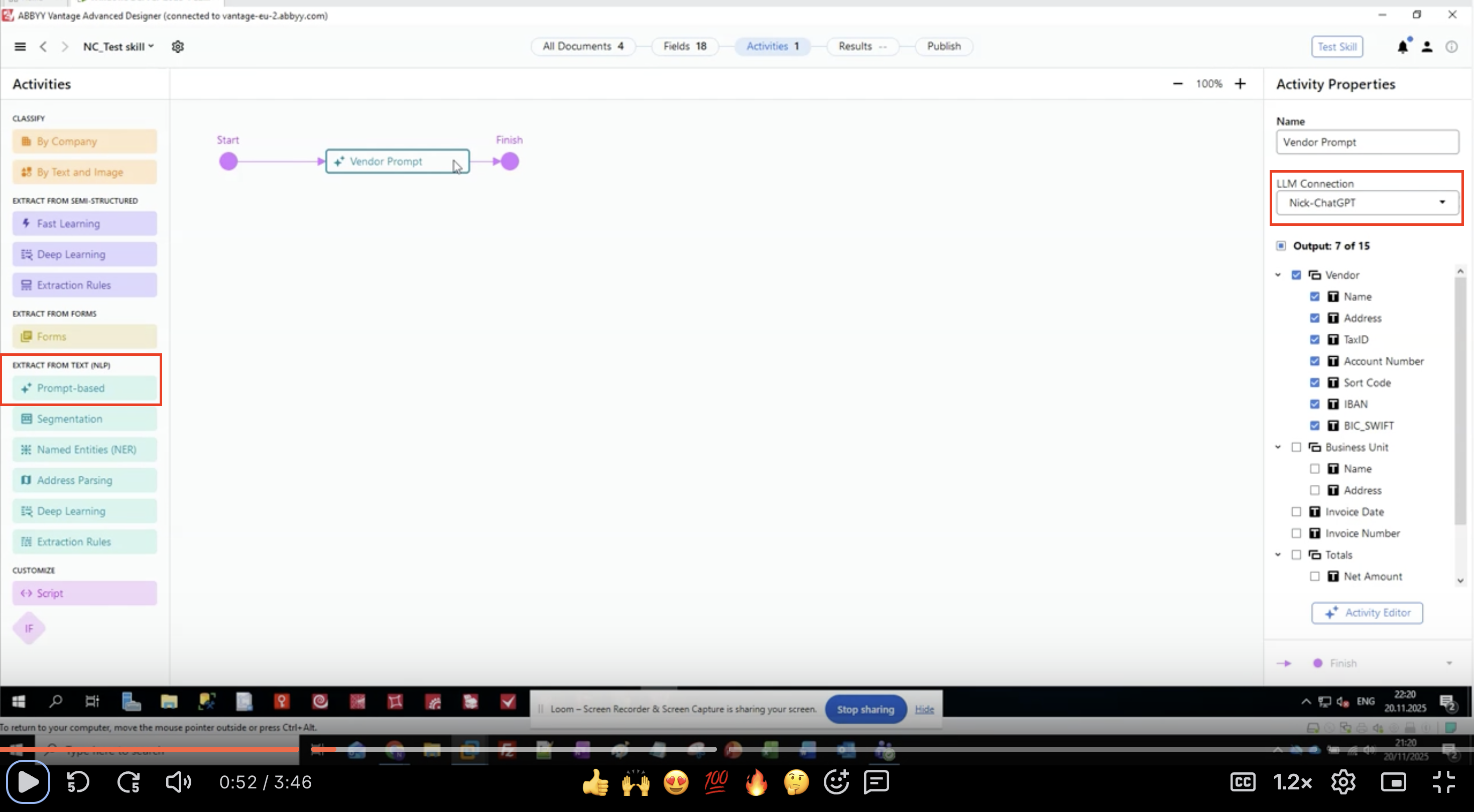
- Die Aktivität wird in Ihrem Workflow-Canvas angezeigt.
- Verbinden Sie sie zwischen den Eingabe- und Ausgabeaktivitäten.
Prompt-basierte Aktivitäten finden Sie im Aktivitätenbereich unter „EXTRACT FROM TEXT (NLP)“, zusammen mit anderen Extraktionsmethoden wie Named Entities (NER) und Deep Learning.
Schritt 2: LLM-Verbindung konfigurieren
- Wählen Sie die promptbasierte Activity in Ihrem Workflow aus.
- Suchen Sie im Activity Properties-Panel auf der rechten Seite den Eintrag LLM Connection.
- Klicken Sie auf das Dropdown-Menü.
- Wählen Sie Ihre konfigurierte LLM-Verbindung aus der Liste aus.
- Beispiel:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Beispiel:
- Überprüfen Sie, ob die Verbindung ausgewählt ist.
Wenn keine Verbindungen angezeigt werden, müssen Sie zuerst eine LLM-Verbindung über Configuration → Connections konfigurieren.
Wenn Sie den Skill veröffentlichen, wird die hier ausgewählte Verbindung im Vantage Web Portal zur Standardverbindung für diesen Skill. Unter Skill Catalog → [your skill] → Parameters wird die Verbindung bereits vorausgefüllt angezeigt. Mandantenadministratoren können sie auf eine andere Verbindung umstellen (zum Beispiel, um einen Produktions-Skill je nach Umgebung auf einen anderen LLM-Endpunkt zu verweisen), ohne den Skill erneut zu veröffentlichen — siehe Document-Skill-Parameter.
Schritt 3: Ausgabefelder definieren
- Suchen Sie im Bereich Activity Properties den Abschnitt Output.
- Sie sehen eine hierarchische Liste von Feldgruppen und Feldern.
- In diesem Beispiel extrahieren wir Vendor-Informationen:
- Vendor
- Name
- Address
- TaxID
- Account Number
- Sort Code
- IBAN
- BIC_SWIFT
- Business Unit
- Name
- Address
- Invoice Date
- Invoice Number
- Totals
- Net Amount
- Vendor
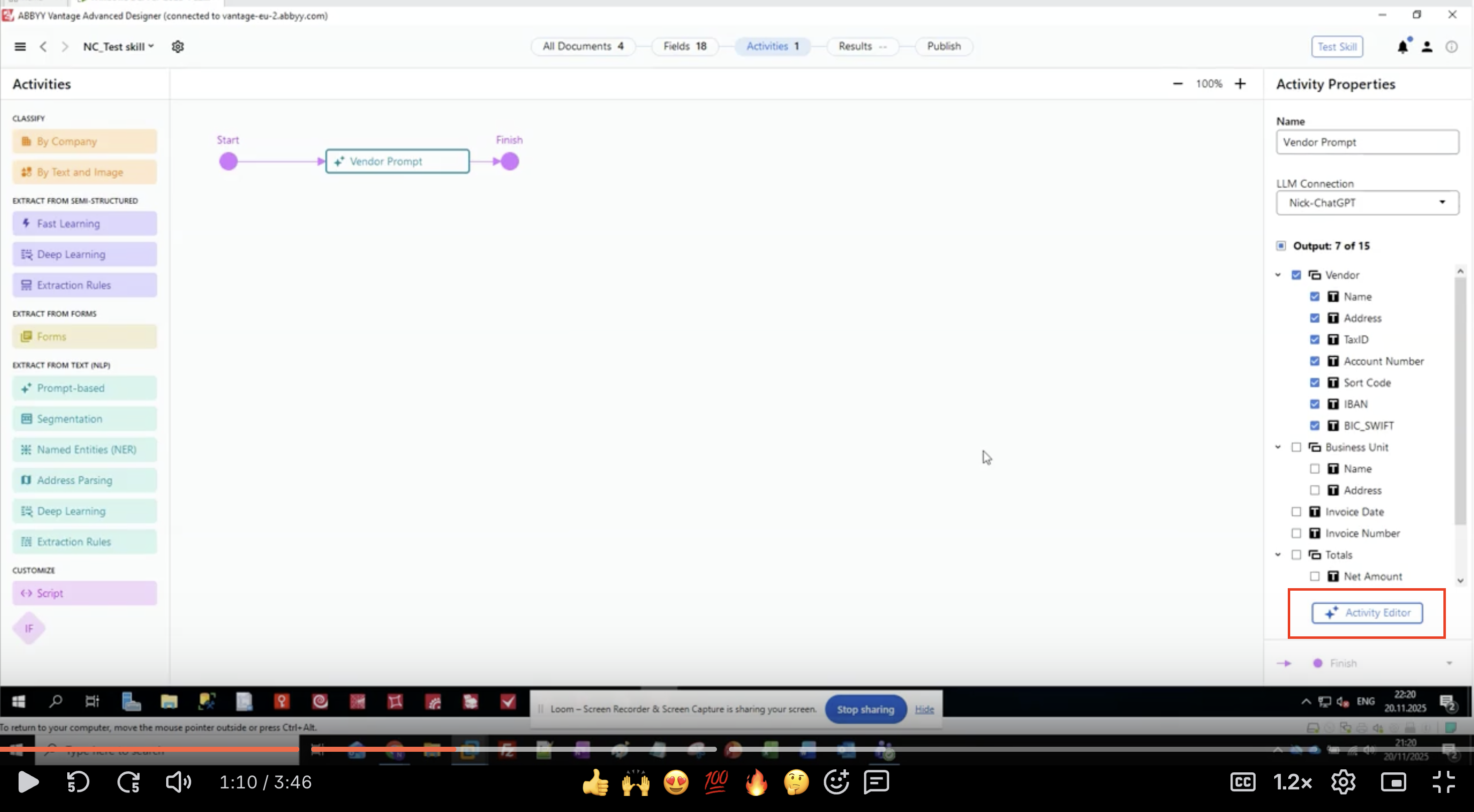
- Klicken Sie auf die Schaltfläche Activity Editor, um mit der Konfiguration des Prompts zu beginnen.
Definieren Sie alle Felder, bevor Sie den Prompt schreiben. Die Feldnamen werden in Ihrer Prompt-Struktur verwendet.
Schritt 4: Die Rollendefinition erstellen
- Im Activity Editor wird die Oberfläche Prompt Text angezeigt
- Beginnen Sie mit dem Abschnitt ROLE:
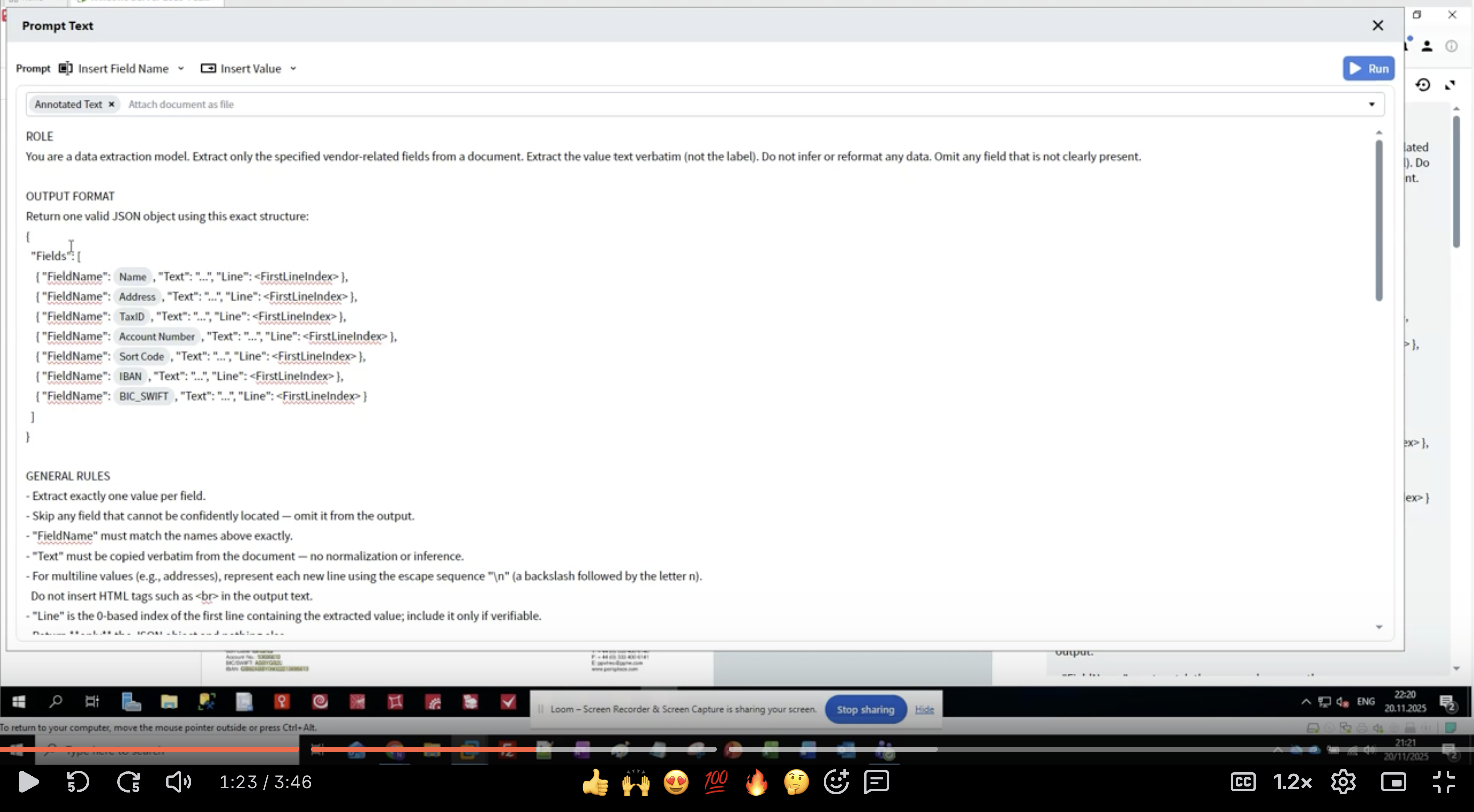
- Sei präzise: “data extraction model” teilt dem LLM seinen Zweck mit.
- Umfang definieren: “vendor-related fields” begrenzt, was extrahiert werden soll.
- Erwartungen festlegen: “value text verbatim” verhindert eine Umformatierung.
- Mit fehlenden Daten umgehen: “Omit any field that is not clearly present”.
- Halte die Rollenbeschreibung klar und prägnant.
- Verwende Imperativformen (“Extract”, “Do not infer”).
- Sei explizit darin, was NICHT getan werden soll.
- Lege fest, wie Sonderfälle zu behandeln sind.
Schritt 5: Ausgabeformat definieren
- Fügen Sie unterhalb des ROLE-Abschnitts die Überschrift OUTPUT FORMAT hinzu.
- Definieren Sie die JSON-Struktur:
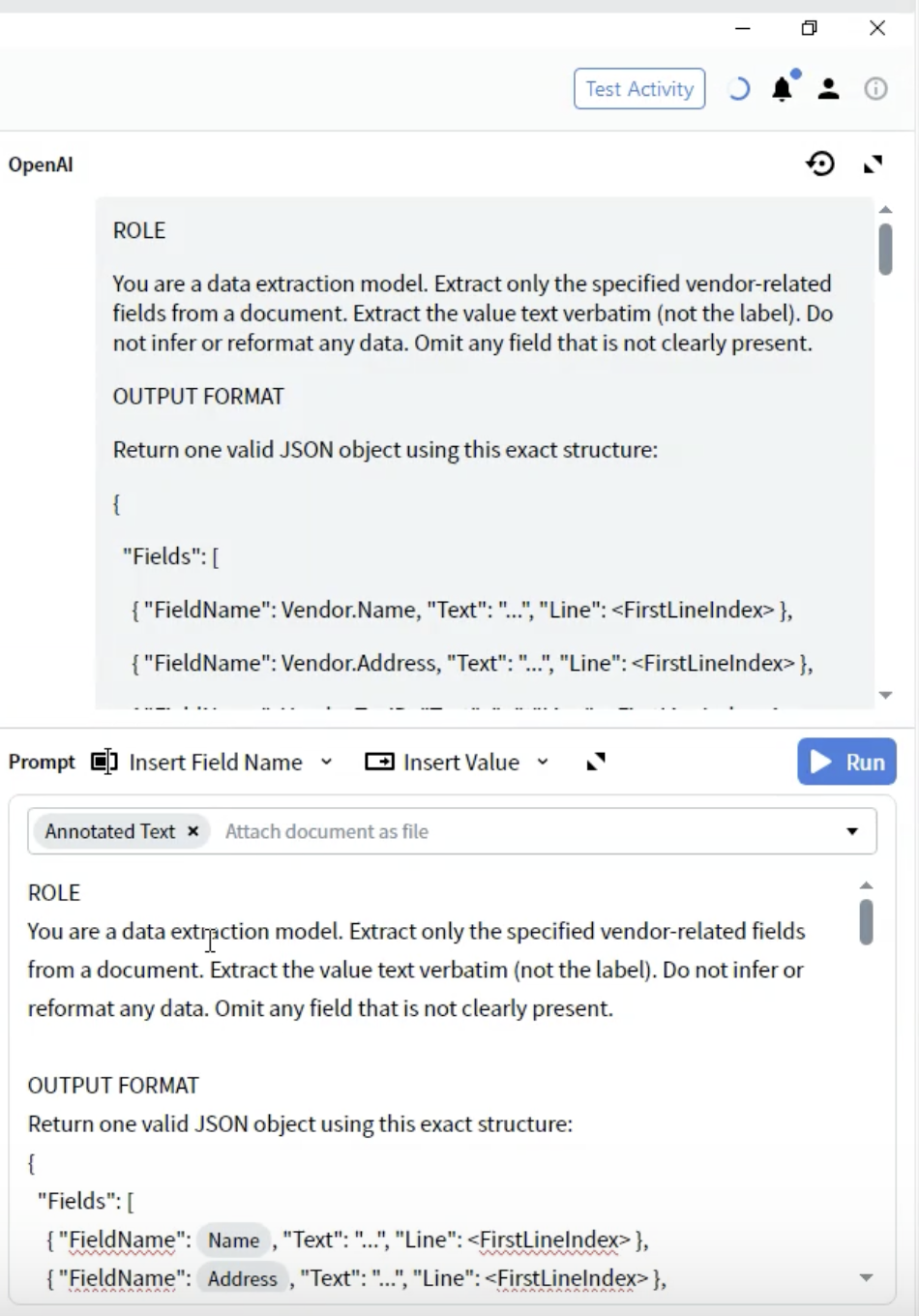
- FieldName: Muss exakt mit Ihren Felddefinitionen übereinstimmen (z. B.
Vendor.Name). - Text: Der extrahierte Wert als string.
- Line: 0-basierter Zeilenindex der Zeile, in der der Wert im Dokument erscheint.
- Verwenden Sie die exakten Feldnamen aus Ihrer Output-Konfiguration.
- Schließen Sie alle Felder ein, auch wenn einige leer sein können.
- Die Struktur muss gültiges JSON sein.
- Zeilennummern helfen bei der Verifizierung und Fehlersuche.
Schritt 6: Feldspezifische Extraktionsregeln hinzufügen
- Erkennungsmuster: Alternative Bezeichnungen für jedes Feld auflisten.
- Formatangaben: Exaktes zu extrahierendes Format beschreiben.
- Positionshinweise: Wo die Daten typischerweise zu finden sind.
- Ausschlüsse: Was NICHT extrahiert werden soll.
- Nummerieren Sie Ihre Regeln für bessere Übersichtlichkeit.
- Geben Sie mehrere Bezeichnungsvarianten an.
- Geben Sie an, wem die Daten gehören (auf Vendor-Seite vs. kundenseitig).
- Fügen Sie Formatbeispiele in Klammern hinzu.
- Seien Sie explizit bei zugehörigen Feldern (z. B. “IBAN ignorieren — sie hat ihr eigenes Feld”).
Schritt 7: Strictness-Regeln anwenden
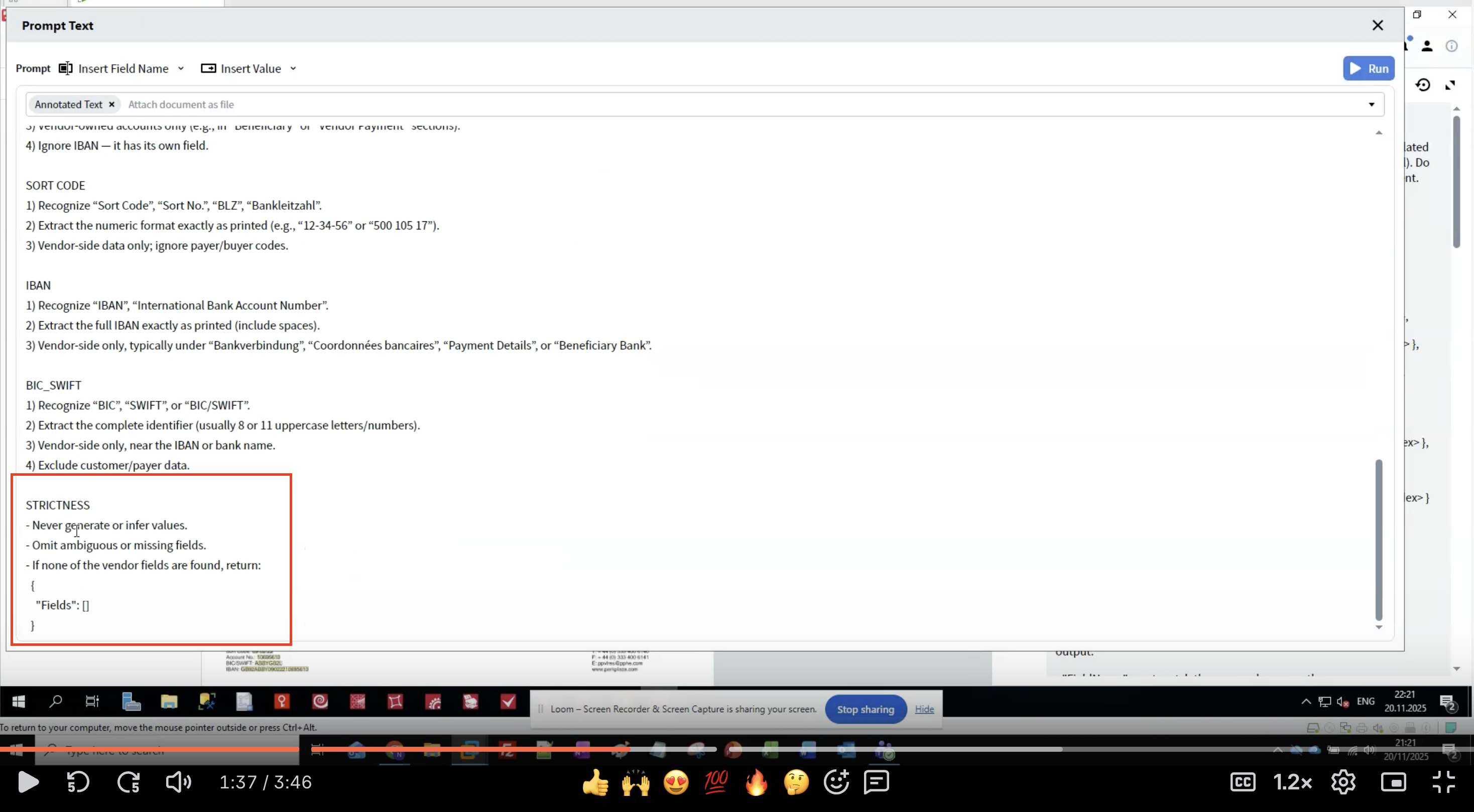
- Verhindert Halluzinationen: LLMs können plausibel wirkende, aber falsche Daten erzeugen.
- Stellt Konsistenz sicher: Klare Regeln verringern die Unterschiede zwischen Durchläufen.
- Geht mit fehlenden Daten um: Definiert, was zu tun ist, wenn Felder nicht gefunden werden.
- Erhält die Datenintegrität: 1:1-Extraktion im Originalwortlaut bewahrt das ursprüngliche Format.
- Niemals Daten erzeugen, die nicht im Dokument vorhanden sind.
- Unsichere Extraktionen lieber auslassen, als zu raten.
- Eine leere Struktur zurückgeben, wenn keine Felder gefunden werden.
- Feldnamen exakt einhalten.
- Ursprüngliche Textformatierung beibehalten.
Schritt 8: Dokumentformat auswählen
- Suchen Sie im Activity Editor die Dropdown-Liste Prompt.
- Sie sehen Optionen, wie das Dokument dem LLM bereitgestellt wird.
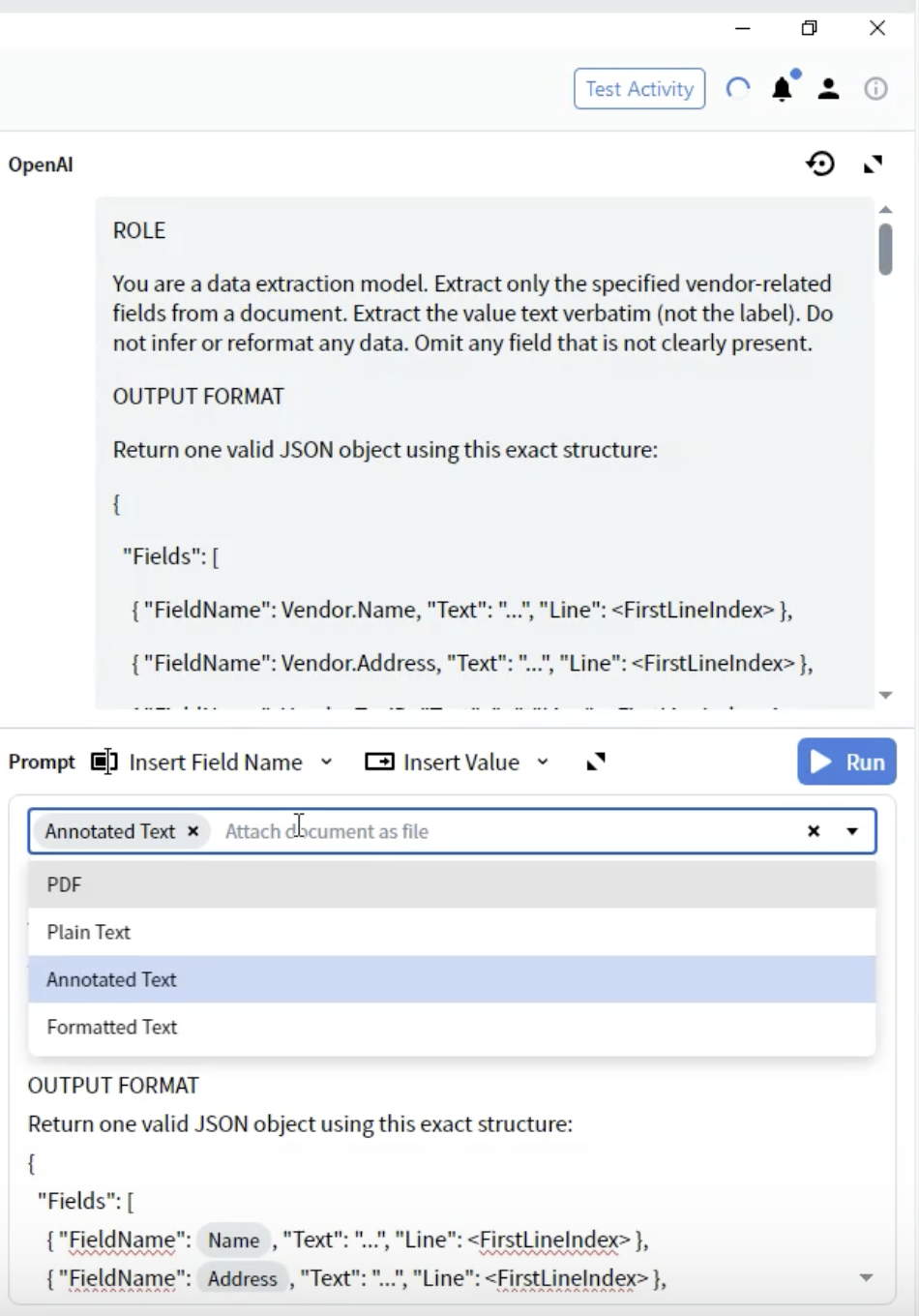
-
PDF: Ursprüngliche PDF-Datei
- Einsatz für: Dokumente, bei denen das Layout entscheidend ist
- Hinweise: Größere Dateigröße, einige LLMs haben nur eingeschränkte PDF-Unterstützung
-
Plain Text: Unformatierte Textextraktion
- Einsatz für: Einfache Dokumente, die nur Text enthalten
- Hinweise: Verliert sämtliche Formatierungs- und Layoutinformationen
-
Annotated Text ⭐ (Empfohlen)
- Einsatz für: Die meisten Dokumenttypen
- Hinweise: Bewahrt die Struktur, bleibt aber textbasiert
- Vorteile: Bestes Gleichgewicht zwischen Struktur und Performance
-
Formatted Text: Text mit grundlegender Formatierung
- Einsatz für: Dokumente, bei denen eine gewisse Formatierung wichtig ist
- Hinweise: Mittelweg zwischen Plain und Annotated
- Wählen Sie Annotated Text für die besten Ergebnisse
In Tests wurde festgestellt, dass Annotated Text die konsistentesten und zuverlässigsten Ergebnisse für Extraktionsaufgaben liefert. Es bewahrt die Dokumentstruktur und kann dennoch effizient von LLMs verarbeitet werden.
Schritt 9: Testen Sie Ihre Extraktion
Aktivität ausführen
- Schließen Sie den Activity Editor.
- Navigieren Sie zur Registerkarte All Documents.
- Wählen Sie ein Testdokument aus.
- Klicken Sie auf Test Activity oder Run.
- Warten Sie, bis das LLM das Dokument verarbeitet hat
- Verarbeitungszeit: in der Regel 5–30 Sekunden, abhängig von der Komplexität des Dokuments.
- Während Sie auf die API-Antwort warten, wird eine Ladeanzeige angezeigt.
Ergebnisse überprüfen
- Die Oberfläche wechselt zur Predictive view.
- Überprüfen Sie das Output-Panel mit den extrahierten Feldern.
- Klicken Sie auf jedes Feld, um Folgendes zu sehen:
- Extrahierter Wert
- Konfidenzwert (falls verfügbar)
- Hervorgehobener Bereich im Dokumentbild
- ✅ Alle erwarteten Felder sind ausgefüllt
- ✅ Werte stimmen exakt mit dem Dokument überein
- ✅ Keine halluzinierten oder abgeleiteten Daten
- ✅ Korrekte Verarbeitung von mehrzeiligen Feldern
- ✅ Fehlende Felder werden ausgelassen (nicht mit falschen Daten aufgefüllt)
Häufige Ergebnismuster
Schritt 10: Verfeinern Sie Ihren Prompt
Häufige Probleme und Lösungen
- Lösung: Fügen Sie genauere Positionshinweise hinzu.
- Beispiel: „Nur Vendor-Seite; Kunden-/Käuferadressen ausschließen“
- Lösung: Betonen Sie die wortgetreue Extraktion.
- Beispiel: „Extrahieren Sie das numerische Format exakt wie gedruckt (z. B. ‚12-34-56‘)“
- Lösung: Verschärfen Sie die Regeln zur Striktheit.
- Beispiel: „Werte niemals generieren oder ableiten. Auslassen, wenn nicht vorhanden.“
- Lösung: Geben Sie Escape-Sequenzen an.
- Beispiel: „Für mehrzeilige Werte
\nfür Zeilenumbrüche verwenden“
- Lösung: Stellen Sie sicher, dass Feldnamen exakt übereinstimmen.
- Beispiel: Verwenden Sie
Vendor.Account Numberund nichtAccountNumber
Iterativer Verbesserungsprozess
- Mit mehreren Dokumenten testen: Nicht für ein einzelnes Beispiel optimieren.
- Muster dokumentieren: Notieren, welche Regeln funktionieren und welche verfeinert werden müssen.
- Konkrete Beispiele hinzufügen: Formatbeispiele in Klammern angeben.
- Strenge verfeinern: Auf Basis von Über- bzw. Unterextraktion anpassen.
- Randfälle testen: Dokumente mit fehlenden Feldern oder ungewöhnlichen Layouts ausprobieren.
Beispiele für Verfeinerungen
Extraktionsprozess verstehen
Funktionsweise der promptbasierten Extraktion
- Dokumentkonvertierung: Ihr Dokument wird in das ausgewählte Format umgewandelt (Format Annotated Text empfohlen).
- Prompt-Erstellung: Ihre Rolle, das Ausgabeformat, Feldregeln und Regeln zur Strenge werden zu einem Prompt zusammengeführt.
- API-Aufruf: Der Prompt und das Dokument werden über Ihre Verbindung an das LLM gesendet.
- LLM-Verarbeitung: Das LLM liest das Dokument und extrahiert Daten gemäß Ihren Anweisungen.
- JSON-Antwort: Das LLM gibt strukturierte Daten im angegebenen JSON-Format zurück.
- Feldzuordnung: Vantage ordnet die JSON-Antwort den von Ihnen definierten Ausgabefeldern zu.
- Verifizierung: Zeilennummern und Konfidenzwerte (falls bereitgestellt) unterstützen die Überprüfung der Genauigkeit.
Tokenverbrauch und Kosten
- Dokumentenlänge: Längere Dokumente verwenden mehr Token.
- Komplexität des Prompts: Detaillierte Prompts erhöhen den Tokenverbrauch.
- Formatwahl: Annotated Text ist in der Regel effizienter als PDF.
- Anzahl der Felder: Mehr Felder = längere Prompts.
- Verwenden Sie prägnante, aber klare Formulierungen in Prompts.
- Wiederholen Sie Anweisungen nicht.
- Entfernen Sie unnötige Beispiele.
- Erwägen Sie, verwandte Felder zu gruppieren.
Bewährte Vorgehensweisen
Prompt-Erstellung
- ✅ Klare, imperative Anweisungen verwenden („Extract“, „Recognize“, „Omit“).
- ✅ Mehrere Bezeichnungsvarianten für jedes Feld angeben.
- ✅ Formatbeispiele in Klammern hinzufügen.
- ✅ Angeben, was NICHT extrahiert werden soll (Ausschlüsse).
- ✅ Regeln nummerieren, um das Nachschlagen zu erleichtern.
- ✅ Einheitliche Terminologie durchgängig verwenden.
- ❌ Unklare Anweisungen verwenden („get the name“).
- ❌ Davon ausgehen, dass das LLM domainspezifische Konventionen kennt.
- ❌ Übermäßig lange, komplexe Sätze schreiben.
- ❌ Sich in verschiedenen Abschnitten widersprechen.
- ❌ Regeln zur Strenge nicht weglassen.
Felddefinitionen
- Beginnen Sie mit Erkennungsmustern (alternativen Bezeichnungen).
- Geben Sie das exakt beizubehaltende Format an.
- Geben Sie Positionierungshinweise an (typische Platzierung).
- Definieren Sie die Datenverantwortung (Vendor vs. Kunde).
- Beschreiben Sie den Umgang mit mehrzeiligen Werten.
- Verweisen Sie auf verwandte Felder, um Verwechslungen zu vermeiden.
Teststrategie
- Mit einfachen Dokumenten beginnen: Zuerst die grundlegende Extraktion testen.
- Auf Varianten erweitern: Verschiedene Layouts und Formate ausprobieren.
- Randfälle testen: Fehlende Felder, ungewöhnliche Positionen, mehrfache Treffer.
- Fehler dokumentieren: Beispiele aufbewahren, in denen die Extraktion fehlschlägt.
- Systematisch iterieren: Immer nur eine Sache auf einmal ändern.
Leistungsoptimierung
- Halten Sie Prompts prägnant.
- Verwenden Sie das Annotated Text-Format.
- Minimieren Sie die Anzahl der Felder pro Aktivität.
- Erwägen Sie das Aufteilen komplexer Dokumente.
- Definieren Sie umfassende Feldregeln.
- Fügen Sie Formatbeispiele hinzu.
- Ergänzen Sie strikte Validierungsregeln.
- Testen Sie mit unterschiedlichen Dokumentbeispielen.
- Optimieren Sie die Prompt-Länge.
- Verwenden Sie effiziente Dokumentformate.
- Speichern Sie Ergebnisse bei Bedarf zwischen.
- Überwachen Sie den Token-Verbrauch über das Dashboard des LLM-Anbieters.
Fehlerbehebung
Extraktionsprobleme
- Prüfen Sie, ob die Schreibweise des Feldnamens exakt übereinstimmt.
- Stellen Sie sicher, dass sich die Daten im ausgewählten Dokumentformat befinden.
- Fügen Sie weitere Label-Varianten zu den Erkennungsmustern hinzu.
- Verringern Sie den Strengegrad vorübergehend, um zu prüfen, ob das LLM die Daten findet.
- Prüfen Sie, ob die Dokumentqualität die OCR/Text-Extraktion beeinflusst.
- Schärfen Sie die Spezifikationen für die Vendor-Seite.
- Fügen Sie explizite Ausschlüsse für Kunden-/Käuferdaten hinzu.
- Geben Sie Positionshinweise an (z. B. „oben im Dokument“, „Ausstellerbereich“).
- Fügen Sie Beispiele für korrekte vs. inkorrekte Extraktion hinzu.
- Geben Sie das Format der Escape-Sequenz explizit an (
\n). - Stellen Sie Beispiele für eine korrekte mehrzeilige Ausgabe bereit.
- Stellen Sie sicher, dass das Dokumentformat Zeilenumbrüche beibehält.
- Fügen Sie die Anweisung hinzu: „Ursprüngliche Zeilenumbrüche mit
\nbeibehalten“.
- Betonen Sie „wortgetreu“ und „genau wie gedruckt“.
- Fügen Sie eine Strenge-Regel hinzu: „Keine Normalisierung oder Ableitung“.
- Geben Sie konkrete Beispiele an, die die Beibehaltung der Formatierung zeigen.
- Fügen Sie Negativbeispiele ein: „Nicht ‚12-34-56‘, beibehalten als ‚12 34 56‘“.
Leistungsprobleme
- Wechseln Sie zum Annotated Text-Format, wenn Sie PDFs verwenden.
- Vereinfachen Sie den Prompt, ohne wichtige Anweisungen zu verlieren.
- Reduzieren Sie die Dokumentauflösung, wenn Bilder sehr groß sind.
- Überprüfen Sie den Status und die Rate-Limits des LLM-Anbieters.
- Ziehen Sie ein schnelleres Modell für einfache Dokumente in Betracht.
- Verschärfen Sie die Strengevorgaben.
- Formulieren Sie die Anweisungen genauer und eindeutiger.
- Fügen Sie mehr Formatbeispiele hinzu.
- Reduzieren Sie die Prompt-Komplexität, die zu Interpretationen führen könnte.
- Testen Sie mit höheren Temperatureinstellungen (falls in der Verbindung verfügbar).
- Optimieren Sie die Prompt-Länge.
- Verwenden Sie Annotated Text anstelle von PDF.
- Verarbeiten Sie Dokumente in Batches außerhalb der Spitzenzeiten.
- Ziehen Sie kleinere/günstigere Modelle für einfache Dokumente in Betracht.
- Überwachen Sie das Budget und richten Sie Budgetwarnungen im Dashboard des LLM-Anbieters ein.
Fortgeschrittene Techniken
Bedingte Extraktion
Unterstützung mehrerer Sprachen
Validierungsregeln
Feldbeziehungen
Einschränkungen und Überlegungen
Aktuelle Funktionen
- ✅ Feldextraktion auf Header-Ebene
- ✅ Ein- und mehrzeilige Werte
- ✅ Mehrere Felder pro Dokument
- ✅ Bedingte Extraktionslogik
- ✅ Mehrsprachige Dokumente
- ✅ Variable Dokumentlayouts
- ⚠️ Tabellenextraktion (unterscheidet sich je nach Implementierung)
- ⚠️ Verschachtelte komplexe Strukturen
- ⚠️ Sehr große Dokumente (Token-Limits)
- ⚠️ Echtzeitverarbeitung (API-Latenz)
- ⚠️ Garantiert deterministische Ergebnisse
Wann Sie die promptbasierte Extraktion verwenden sollten
- Dokumente mit variablen Layouts
- Teilstrukturierte Dokumente
- Schnelles Prototyping und Testen
- Kleine bis mittlere Dokumentvolumina
- Wenn keine Trainingsdaten verfügbar sind
- Mehrsprachige Dokumentverarbeitung
- Produktivbetrieb mit hohem Volumen (traditionelles ML kann schneller sein)
- Stark strukturierte Formulare (vorlagenbasierte Extraktion)
- Kostenkritische Anwendungen (traditionelle Methoden können günstiger sein)
- Latenzkritische Anwendungen (LLM-APIs haben Netzwerklatenz)
- Anforderungen an Offline-Verarbeitung (für traditionelle Methoden ist kein Internet erforderlich)
Integration mit Document-Skills
Verwendung extrahierter Daten
- Validierungsaktivitäten: Geschäftsregeln auf extrahierte Werte anwenden.
- Skriptaktivitäten: Extrahierte Daten verarbeiten oder transformieren.
- Exportaktivitäten: Daten an externe Systeme senden.
- Review-Oberfläche: Manuelle Überprüfung der extrahierten Felder.
Kombinieren mit anderen Activities
Feldzuordnung
"FieldName": "Vendor.Name"→ wird dem AusgabefeldVendor.Namezugeordnet.- Die Feldhierarchie bleibt in der Ausgabestruktur erhalten.
- Zeilennummern helfen bei der Überprüfung und Fehlerbehebung.
Zusammenfassung
- ✅ Eine promptbasierte Extraktionsaktivität erstellt.
- ✅ Eine LLM-Verbindung konfiguriert.
- ✅ Einen umfassenden Extraktions-Prompt mit Rolle, Format und Regeln geschrieben.
- ✅ Das optimale Dokumentformat (Annotated Text) ausgewählt.
- ✅ Strenge Regeln zur Sicherstellung der Datenqualität angewendet.
- ✅ Die Extraktion getestet und die Ergebnisse überprüft.
- ✅ Best Practices für Prompt-Engineering gelernt.
- Promptbasierte Extraktion verwendet Anweisungen in natürlicher Sprache.
- Das Annotated-Text-Format liefert die besten Ergebnisse.
- Klare, spezifische Prompts führen zu einer konsistenten Extraktion.
- Strenge Regeln verhindern Halluzinationen und sichern die Datenqualität.
- Iteratives Testen und Verfeinern verbessert die Genauigkeit.
Weitere Schritte
- Mit unterschiedlichen Dokumenten testen: Validieren Sie Ihre Lösung mit verschiedenen Layouts und Varianten.
- Prompts verfeinern: Verbessern Sie diese kontinuierlich auf Basis der Ergebnisse.
- Kosten überwachen: Verfolgen Sie die Token-Nutzung im Dashboard Ihres LLM-Anbieters.
- Performance optimieren: Stimmen Sie Prompts auf Geschwindigkeit und Genauigkeit ab.
- Tabellenextraktion erkunden: Experimentieren Sie mit dem Extrahieren von Positionen (wiederholte Gruppe) (falls unterstützt).
- In Workflows integrieren: Kombinieren Sie dies mit anderen Aktivitäten für eine vollständige Verarbeitung.
Zusätzliche Ressourcen
- ABBYY Vantage Advanced Designer-Dokumentation: https://docs.abbyy.com
- Leitfaden zur Einrichtung von LLM-Verbindungen: LLM-Verbindungen konfigurieren.
- Best Practices für Prompt-Engineering: Konsultieren Sie die Dokumentation Ihres LLM-Anbieters.
- Support: Wenden Sie sich für technische Unterstützung an den ABBYY-Support.