Vue d’ensemble
- Créer une activité d’extraction basée sur des prompts.
- Configurer une connexion LLM.
- Rédiger des prompts d’extraction efficaces.
- Définir le format et la structure de sortie.
- Appliquer le niveau de rigueur et les Règles de validation.
- Tester et affiner votre extraction.
- Extraction d’informations Fournisseur à partir de factures
- Capture de données de document au niveau de l’en-tête
- Traitement de documents semi-structurés
- Documents avec des mises en page variables
Prérequis
- Un accès à ABBYY Vantage Advanced Designer.
- Une connexion LLM configurée. Voir Configurer les connexions LLM.
- Une Compétence de document avec des documents d’exemple chargés.
- Une compréhension de base de la structure JSON.
- Des définitions de champs pour les données que vous souhaitez extraire.
Ce guide est axé sur l’extraction au niveau de l’en-tête. Les capacités d’extraction de tableaux peuvent varier.
Comprendre l’extraction basée sur des prompts
Qu’est-ce que l’extraction basée sur des prompts ?
- Rôle : Le rôle que le LLM doit jouer (par exemple, « modèle d’extraction de données »).
- Instructions : Comment extraire et formater les données.
- Structure de sortie : Le format JSON exact des résultats.
- Règles : Les directives pour gérer les données ambiguës ou manquantes.
Avantages
- Aucune donnée d’entraînement requise : fonctionne simplement grâce au prompt engineering.
- Flexible : il est facile d’ajouter ou de modifier des champs.
- Gère les variations : les LLM peuvent comprendre différents formats de documents.
- Configuration rapide : plus rapide que l’entraînement de modèles de ML traditionnels.
- Langage naturel : rédigez les instructions en anglais courant.
Limitations
- Coût : chaque extraction requiert des appels à l’API LLM.
- Vitesse : plus lente que l’extraction traditionnelle pour les documents simples.
- Cohérence : les résultats peuvent légèrement varier d’une exécution à l’autre.
- Limites de contexte : les documents très volumineux peuvent nécessiter un traitement spécifique.
Étape 1 : Ajouter une activité basée sur un prompt
- Ouvrez votre Compétence de document dans ABBYY Vantage Advanced Designer.
- Dans le panneau de gauche, repérez EXTRACT FROM TEXT (NLP).
- Recherchez et cliquez sur Prompt-based.
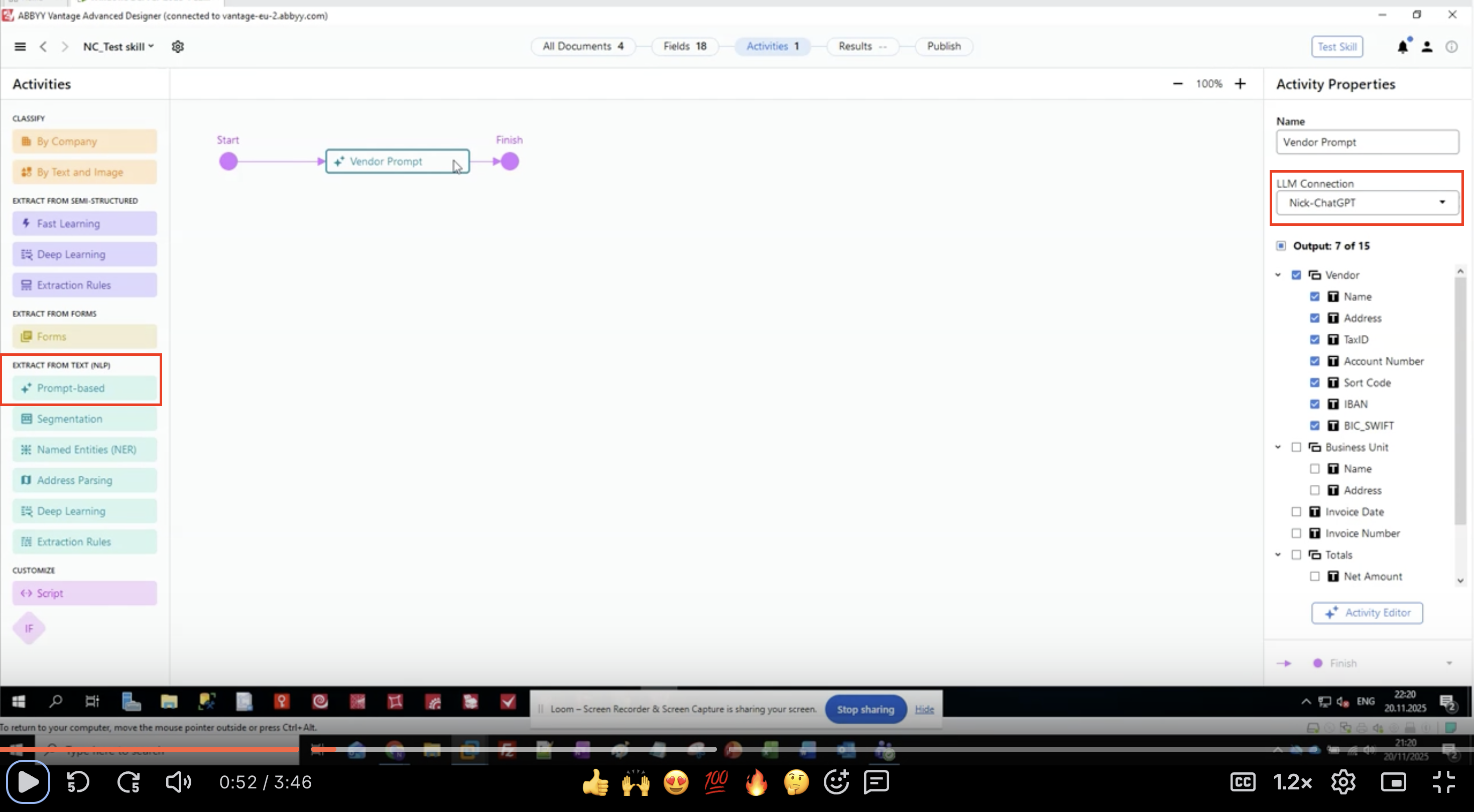
- L’activité apparaît dans votre canevas de flux de travail.
- Connectez-la entre vos activités d’entrée et de sortie.
les activités basées sur un prompt se trouvent sous « EXTRACT FROM TEXT (NLP) » dans le panneau Activities, à côté d’autres méthodes d’extraction comme Named Entities (NER) et Deep Learning.
Étape 2 : Configurer la connexion LLM
- Sélectionnez l’activité basée sur des prompts dans votre workflow.
- Dans le panneau Activity Properties à droite, repérez LLM Connection.
- Cliquez sur le menu déroulant.
- Sélectionnez dans la liste votre connexion LLM déjà configurée.
- Exemple :
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Exemple :
- Vérifiez que la connexion est bien sélectionnée.
Si aucune connexion n’apparaît dans la liste, vous devez d’abord configurer une connexion LLM via Configuration → Connections.
Lorsque vous publiez la compétence, la connexion que vous sélectionnez ici devient la valeur par défaut de cette compétence dans le Vantage Web Portal. Sous Skill Catalog → [your skill] → Parameters, la connexion apparaît préremplie. Les administrateurs du tenant peuvent la remplacer par une autre connexion (par exemple, pour faire pointer une compétence de production vers un autre point de terminaison LLM selon l’environnement) sans republier la compétence — voir paramètres de compétence de document.
Étape 3 : Définir les champs de sortie
- Dans le panneau Activity Properties, repérez la section Output.
- Vous verrez une liste hiérarchique de groupes de champs et de champs.
- Pour cet exemple, nous extrayons les informations du fournisseur :
- Fournisseur
- Nom
- Adresse
- TaxID
- Numéro de compte
- Code guichet
- IBAN
- BIC_SWIFT
- Unité opérationnelle
- Nom
- Adresse
- Date de la facture
- Numéro de facture
- Totaux
- Montant net
- Fournisseur
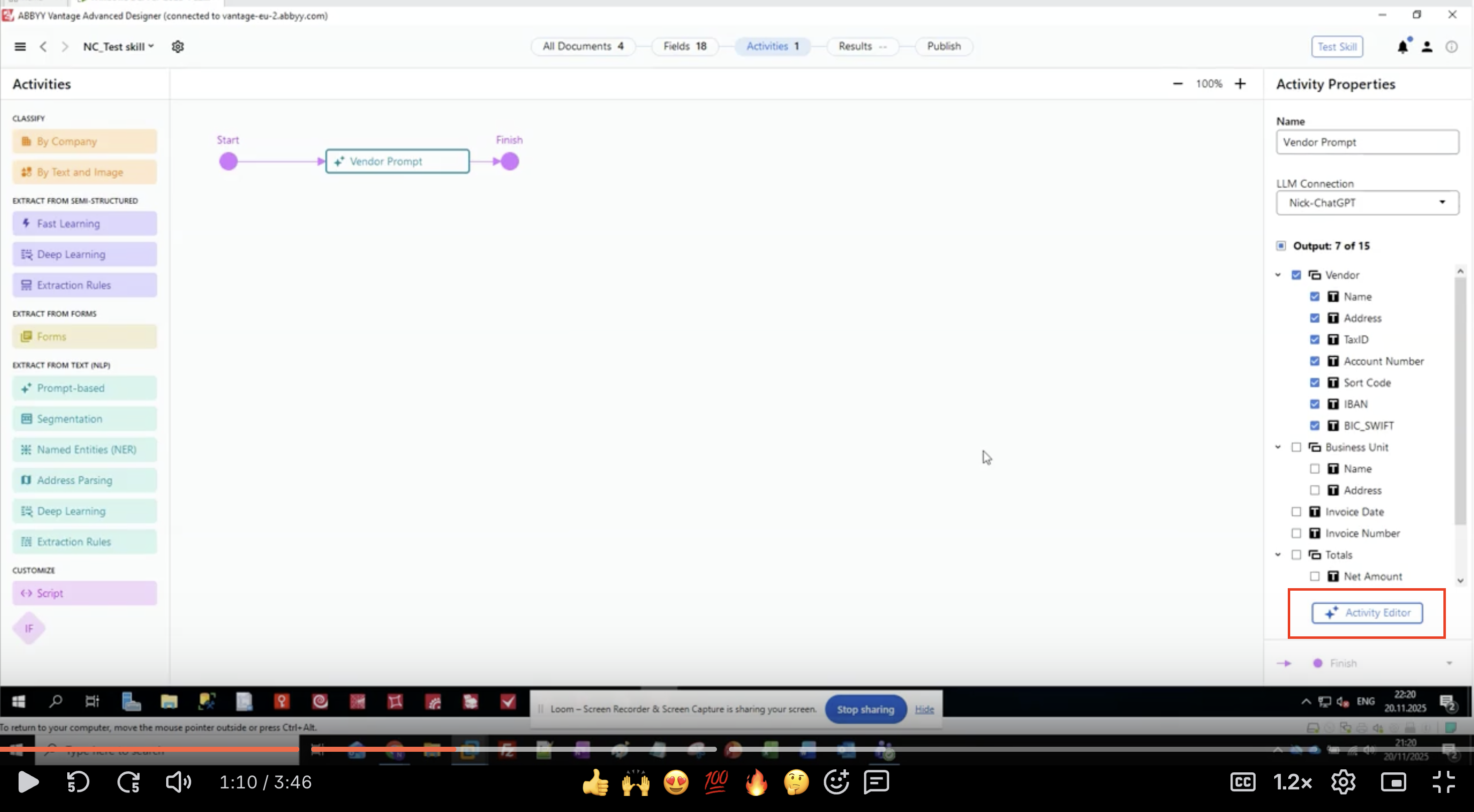
- Cliquez sur le bouton Activity Editor pour commencer à configurer le prompt.
Définissez tous les champs avant de rédiger votre prompt. Les noms de champs seront utilisés dans la structure de votre prompt.
Étape 4 : Rédiger la définition du rôle
- Dans l’Activity Editor, l’interface Prompt Text s’affiche.
- Commencez par la section ROLE :
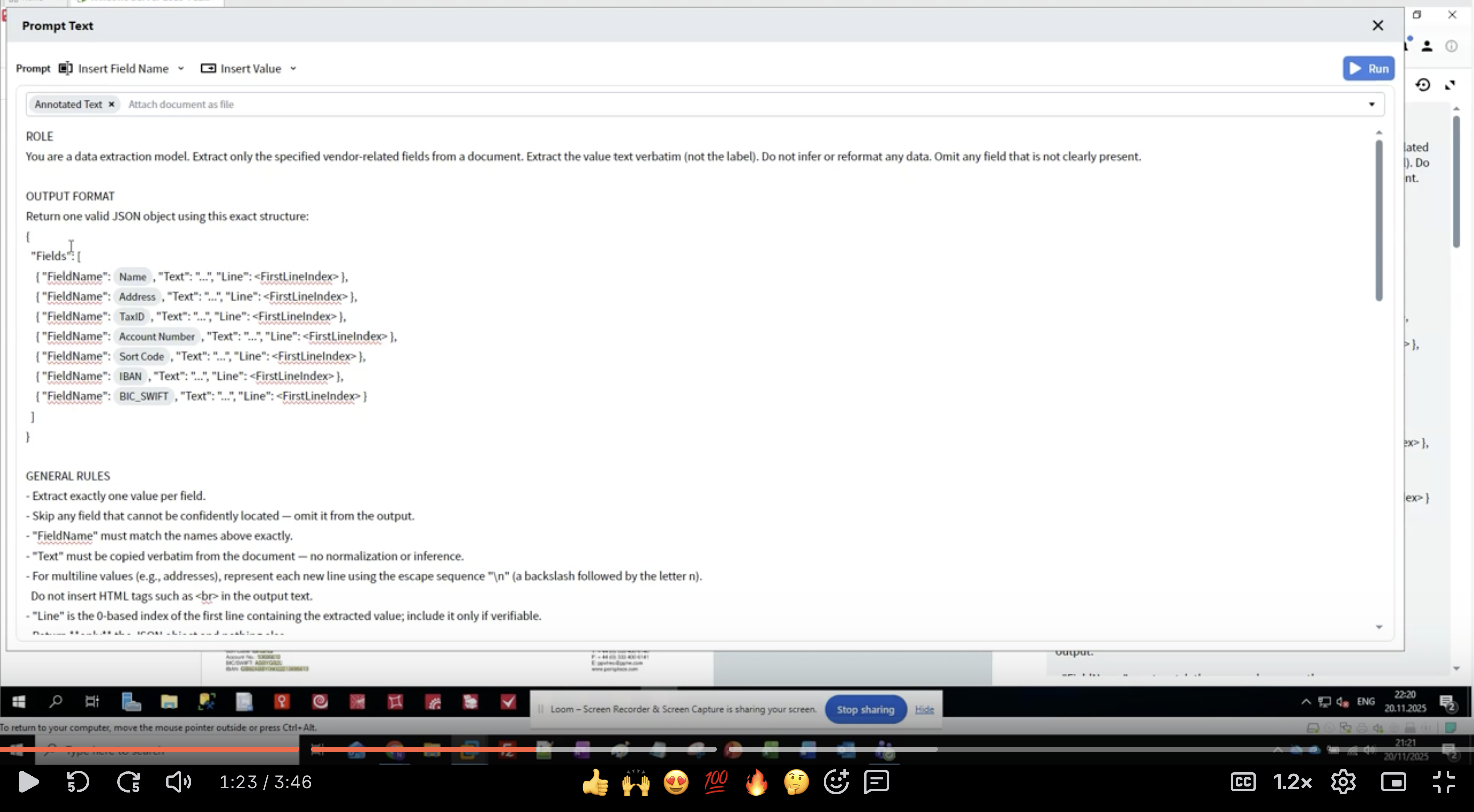
- Soyez spécifique : “data extraction model” indique au LLM son objectif.
- Définissez le périmètre : “vendor-related fields” limite ce qu’il faut extraire.
- Fixez les attentes : “value text verbatim” empêche tout reformatage.
- Gérez les données manquantes : “Omit any field that is not clairement présent”.
- Gardez le rôle clair et concis.
- Utilisez des formulations à l’impératif (“Extract”, “Do not infer”).
- Soyez explicite sur ce qu’il NE faut PAS faire.
- Définissez comment gérer les cas limites.
Étape 5 : Définir le format de sortie
- Sous la section ROLE, ajoutez l’en-tête OUTPUT FORMAT.
- Définissez la structure JSON :
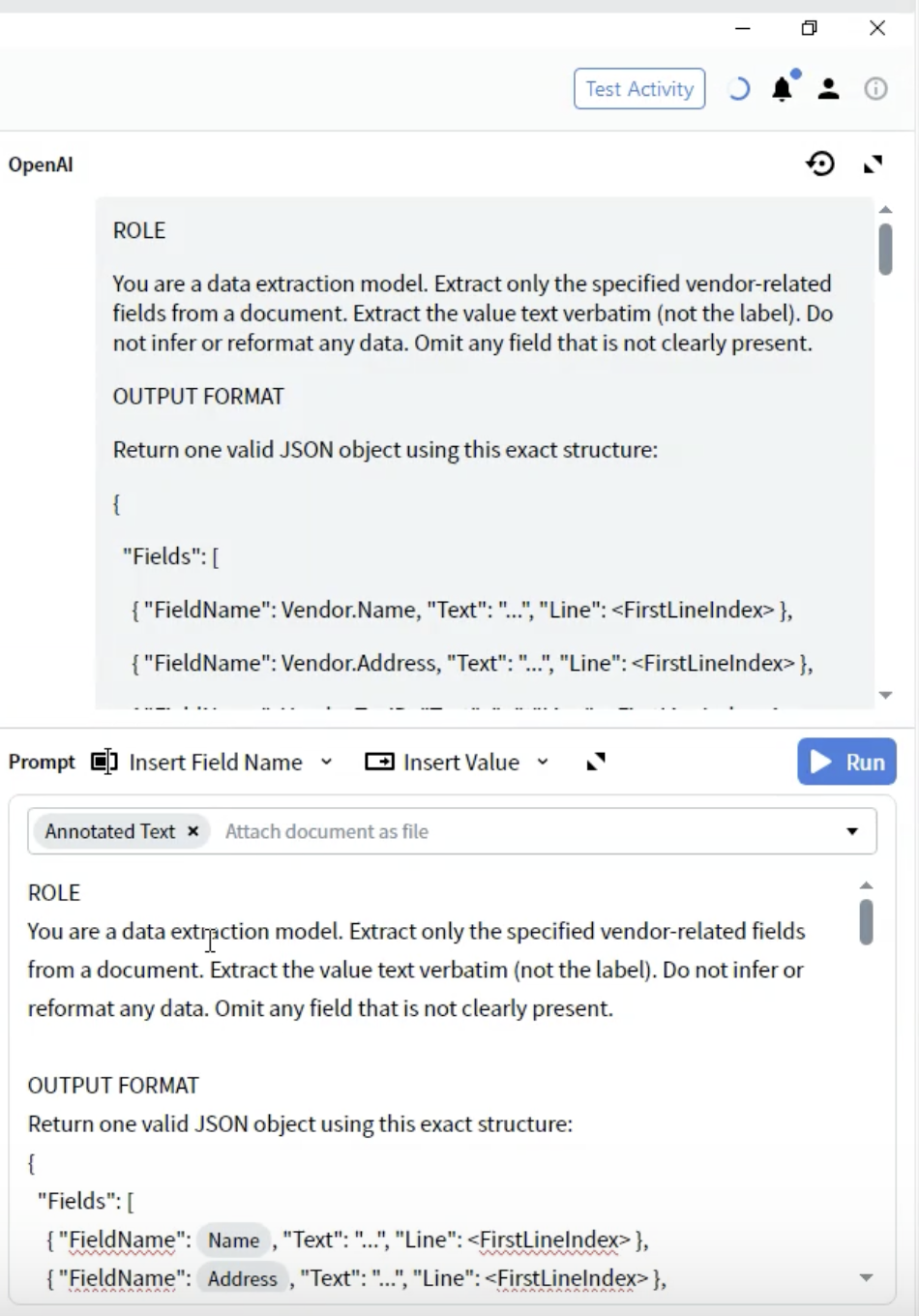
- FieldName: Doit correspondre exactement à vos définitions de champs (par exemple,
Vendor.Name). - Text: La valeur extraite sous forme de string.
- Line: Index de ligne commençant à 0 où la valeur apparaît dans le document.
- Utilisez les noms de champs exacts de votre configuration Output.
- Incluez tous les champs, même si certains peuvent être vides.
- La structure doit être un JSON valide.
- Les numéros de ligne facilitent la vérification et le dépannage.
Étape 6 : Ajouter des règles d’extraction spécifiques à chaque champ
- Modèles de reconnaissance : Lister des libellés alternatifs pour chaque champ.
- Spécifications de format : Décrire le format exact à extraire.
- Indications de localisation : Où trouver généralement les données.
- Exclusions : Ce qu’il NE FAUT PAS extraire.
- Numérotez vos règles pour plus de clarté.
- Fournissez plusieurs variantes de libellés.
- Indiquez à qui appartiennent les données (côté fournisseur vs. côté client).
- Incluez des exemples de format entre parenthèses.
- Soyez explicite à propos des champs associés (par ex. : “Ignorer l’IBAN — il possède son propre champ”).
Étape 7 : Appliquer des règles de rigueur
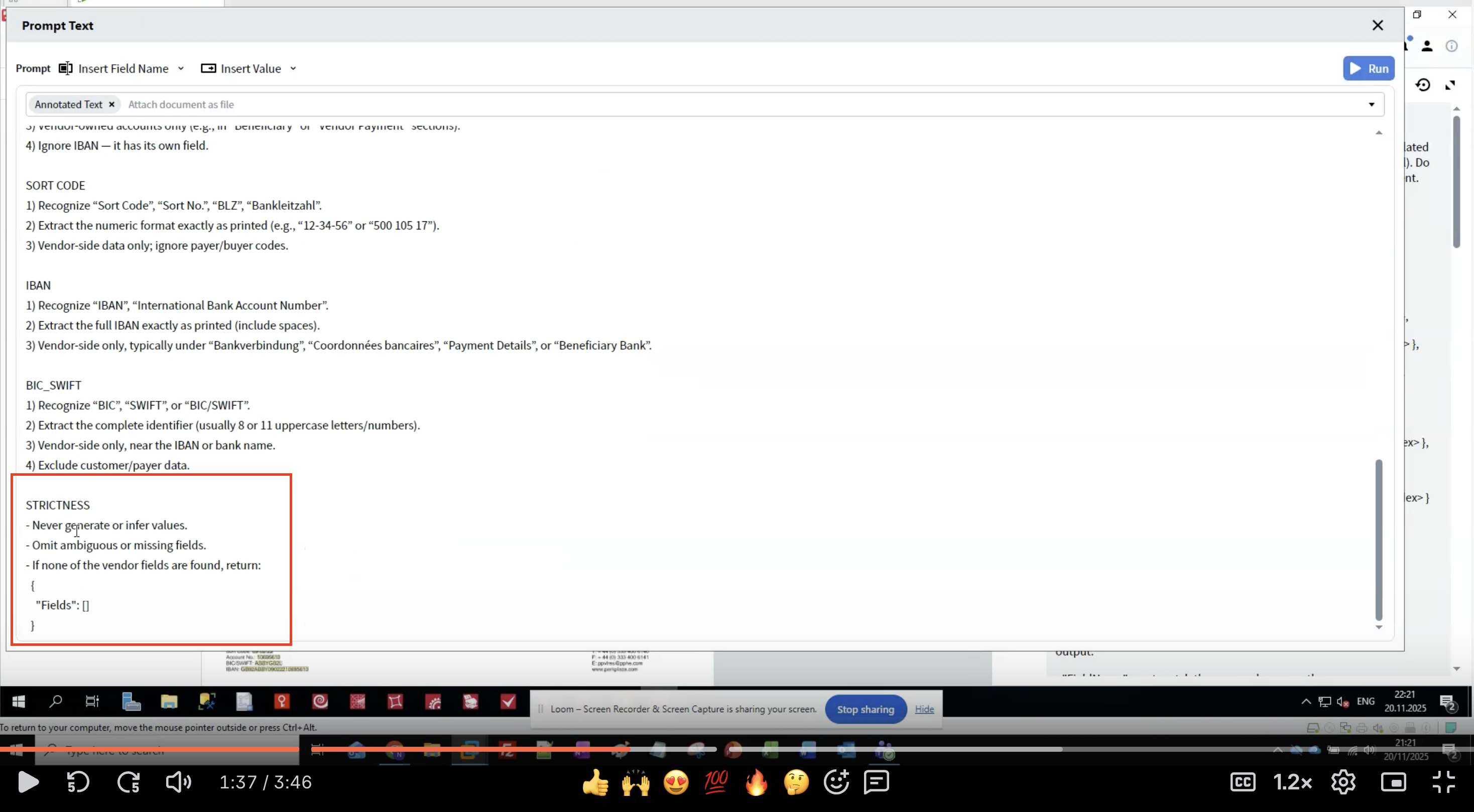
- Empêche les hallucinations : les LLM peuvent générer des données plausibles mais incorrectes.
- Garantit la cohérence : des règles claires réduisent les variations entre exécutions.
- Gère les données manquantes : définit quoi faire lorsque des champs ne sont pas trouvés.
- Maintient l’intégrité des données : une extraction à l’identique préserve le formatage d’origine.
- Ne jamais générer de données qui ne figurent pas dans le document.
- Omettre les extractions incertaines plutôt que de deviner.
- Renvoyer une structure vide si aucun champ n’est trouvé.
- Respecter exactement les noms de champ.
- Préserver le formatage du texte original.
Étape 8 : Sélectionner le format de document
- Dans l’Activity Editor, repérez la liste déroulante Prompt.
- Vous verrez des options indiquant comment le document est fourni au LLM.
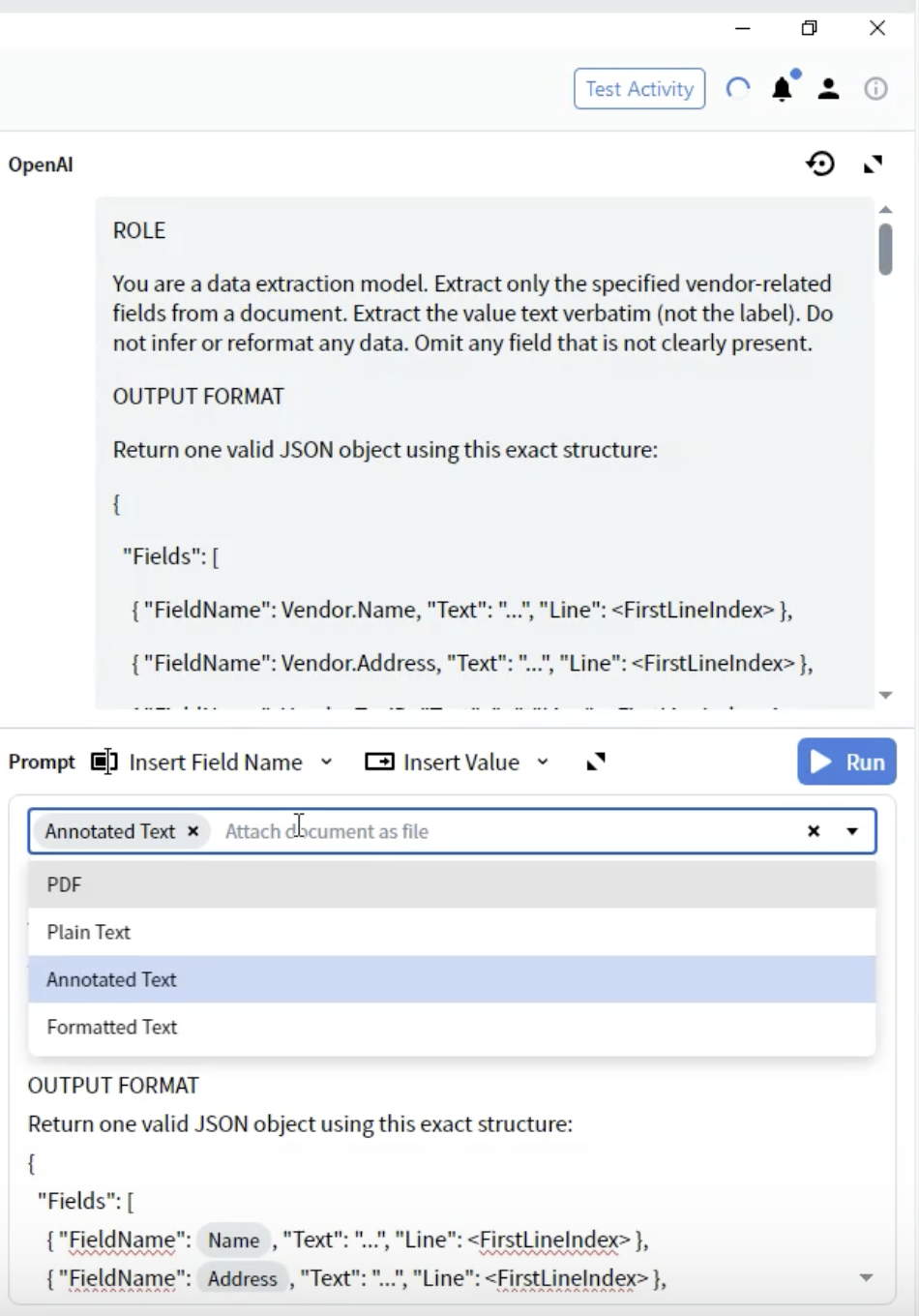
-
PDF : Fichier PDF d’origine
- À utiliser pour : Documents dont la mise en page est critique
- Points à prendre en compte : Taille de fichier plus importante, certains LLM offrent une prise en charge du PDF limitée
-
Texte brut : Extraction de texte non formaté
- À utiliser pour : Documents simples contenant uniquement du texte
- Points à prendre en compte : Perte de toute mise en forme et de toutes les informations de disposition
-
Annotated Text ⭐ (Recommandé)
- À utiliser pour : La plupart des types de documents
- Points à prendre en compte : Préserve la structure tout en restant basé sur du texte
- Avantages : Meilleur compromis entre structure et performances
-
Texte mis en forme : Texte avec une mise en forme de base préservée
- À utiliser pour : Documents pour lesquels une partie de la mise en forme est importante
- Points à prendre en compte : Solution intermédiaire entre Texte brut et Annotated Text
- Sélectionnez Annotated Text pour obtenir les meilleurs résultats
D’après les tests, le format Annotated Text fournit les résultats les plus cohérents et fiables pour les tâches d’extraction. Il préserve la structure du document tout en étant traité efficacement par les LLM.
Étape 9 : Testez votre extraction
Exécuter l’Activity
- Fermez l’Activity Editor.
- Accédez à l’onglet All Documents.
- Sélectionnez un document de test.
- Cliquez sur le bouton Test Activity ou sur Run.
- Attendez que le LLM traite le document.
- Temps de traitement : généralement de 5 à 30 secondes selon la complexité du document.
- Un indicateur de chargement s’affiche en attendant la réponse de l’API.
Examiner les résultats
- L’interface bascule en Predictive view.
- Examinez le panneau Output affichant les champs extraits.
- Cliquez sur chaque champ pour voir :
- Valeur extraite
- Niveau de confiance (si disponible)
- Zone surlignée sur l’image du document
- ✅ Tous les champs attendus sont renseignés
- ✅ Les valeurs correspondent exactement au document
- ✅ Aucune donnée hallucinée ou déduite
- ✅ Gestion correcte des champs multilignes
- ✅ Les champs manquants sont omis (et non remplis avec des données incorrectes)
Schémas de résultats courants
Étape 10 : Affiner votre prompt
Problèmes courants et solutions
- Solution : Ajoutez des indications de position plus précises.
- Exemple : “Côté Fournisseur uniquement ; exclure les adresses client/acheteur”
- Solution : Insistez sur l’extraction à l’identique.
- Exemple : “Extrayez le format numérique exactement tel qu’imprimé (par ex. ‘12-34-56’)”
- Solution : Renforcez les règles de stricte rigueur.
- Exemple : “Ne générez ni ne déduisez jamais de valeurs. Omettez-les si elles ne sont pas présentes.”
- Solution : Spécifiez les séquences d’échappement.
- Exemple : “Pour les valeurs multilignes, utilisez
\npour les retours à la ligne”
- Solution : Vérifiez que les noms de champs correspondent exactement.
- Exemple : Utilisez
Vendor.Account Numberet nonAccountNumber
Processus d’amélioration itératif
- Tester sur plusieurs documents : ne pas optimiser pour un seul exemple.
- Documenter les schémas : noter quelles règles fonctionnent et lesquelles doivent être affinées.
- Ajouter des exemples spécifiques : inclure des exemples de formats entre parenthèses.
- Ajuster le niveau de strictité : modifier en fonction des schémas de sur‑ ou de sous‑extraction.
- Tester les cas limites : essayer des documents avec des champs manquants, des mises en page inhabituelles.
Exemples d’optimisation
Comprendre le processus d’extraction
Fonctionnement de l’extraction basée sur des prompts
- Conversion du document : Votre document est converti dans le format sélectionné (Annotated Text recommandé).
- Assemblage du prompt : Votre rôle, le format de sortie, les règles de champ et les règles de strictité sont combinés.
- Appel à l’API : Le prompt et le document sont envoyés au LLM via votre connexion.
- Traitement par le LLM : Le LLM lit le document et extrait les données conformément à vos instructions.
- Réponse JSON : Le LLM renvoie des données structurées dans le format JSON spécifié.
- Correspondance des champs : Vantage associe la réponse JSON aux champs de sortie que vous avez définis.
- Vérification : Les numéros de ligne et les scores de confiance (s’ils sont fournis) aident à vérifier la précision.
Utilisation des jetons et coûts associés
- Longueur du document : les documents plus longs consomment plus de jetons.
- Complexité du prompt : des prompts détaillés augmentent le nombre de jetons.
- Choix du format : le format Annotated Text est généralement plus efficace que le PDF.
- Nombre de champs : plus de champs = prompts plus longs.
- Utilisez un langage concis mais clair dans les prompts.
- Évitez de dupliquer les instructions.
- Supprimez les exemples non essentiels.
- Envisagez de regrouper les champs pour les données connexes.
Bonnes pratiques
Rédaction de prompts
- ✅ Utiliser des énoncés clairs et impératifs (“Extraire”, “Reconnaître”, “Omettre”).
- ✅ Fournir plusieurs variantes de libellés pour chaque champ.
- ✅ Inclure des exemples de format entre parenthèses.
- ✅ Préciser ce qu’il ne faut PAS extraire (exclusions).
- ✅ Numéroter vos règles pour y faire référence facilement.
- ✅ Utiliser une terminologie cohérente dans tout le document.
- ❌ Utiliser des instructions vagues (“récupérer le nom”).
- ❌ Supposer que le LLM connaît les conventions spécifiques au domaine.
- ❌ Rédiger des phrases trop longues et complexes.
- ❌ Vous contredire dans différentes sections.
- ❌ Ignorer les règles de rigueur.
Définitions de champs
- Commencez par les modèles de reconnaissance (libellés alternatifs).
- Précisez le format exact à conserver.
- Fournissez des indications de position (emplacement habituel).
- Définissez l’appartenance des données (Fournisseur vs client).
- Prévoyez la gestion des valeurs sur plusieurs lignes.
- Faites référence aux champs associés pour éviter toute confusion.
Stratégie de test
- Commencez par des documents simples : Testez d’abord l’extraction de base.
- Étendez ensuite aux variantes : Essayez différentes mises en page et différents formats.
- Testez les cas limites : champs manquants, positions inhabituelles, correspondances multiples.
- Documentez les échecs : Conservez des exemples des cas où l’extraction échoue.
- Itérez de manière systématique : Ne modifiez qu’un seul paramètre à la fois.
Optimisation des performances
- Gardez les prompts concis.
- Utilisez le format Annotated Text.
- Réduisez au minimum le nombre de champs par activité.
- Envisagez de scinder les documents complexes.
- Fournissez des règles de champ exhaustives.
- Incluez des exemples de format.
- Ajoutez des règles de validation strictes.
- Testez avec un large éventail d’exemples de documents.
- Optimisez la longueur des prompts.
- Utilisez des formats de documents efficaces.
- Mettez en cache les résultats lorsque c’est approprié.
- Surveillez l’utilisation des tokens via le tableau de bord du fournisseur LLM.
Résolution des problèmes
Problèmes d’extraction
- Vérifiez que l’orthographe du nom du champ correspond exactement.
- Vérifiez que les données sont dans le format de document sélectionné.
- Ajoutez davantage de variantes de libellés aux modèles de reconnaissance.
- Réduisez temporairement le niveau de strictité pour voir si le LLM les trouve.
- Vérifiez si la qualité du document affecte la Reconnaissance optique de caractères (OCR) / l’extraction de texte.
- Renforcez les spécifications du côté fournisseur.
- Ajoutez des exclusions explicites pour les données du client/acheteur.
- Fournissez des indications de localisation (par exemple, “haut du document”, “section émetteur”).
- Incluez des exemples d’extraction correcte vs. incorrecte.
- Indiquez explicitement le format de la séquence d’échappement (
\n). - Fournissez des exemples de sortie correcte sur plusieurs lignes.
- Vérifiez que le format du document préserve les sauts de ligne.
- Ajoutez l’instruction : “Conservez les sauts de ligne d’origine en utilisant
\n”.
- Mettez l’accent sur “textuellement” et “exactement comme imprimé”.
- Ajoutez une règle de strictité : “Aucune normalisation ni inférence”.
- Fournissez des exemples spécifiques montrant la préservation du formatage.
- Incluez des exemples négatifs : “Pas ‘12-34-56’, conservez ‘12 34 56’”.
Problèmes de performance
- Passer au format Annotated Text si vous utilisez un PDF.
- Simplifier le prompt sans perdre les instructions critiques.
- Réduire la résolution du document si les images sont très grandes.
- Vérifier l’état du fournisseur LLM et les limites de taux.
- Envisager d’utiliser un modèle plus rapide pour les documents simples.
- Renforcer les règles de stricte conformité.
- Rendre les instructions plus spécifiques et non ambiguës.
- Ajouter davantage d’exemples de format.
- Réduire la complexité du prompt qui pourrait laisser place à l’interprétation.
- Tester avec des paramètres de température plus élevés (si disponibles dans la connexion).
- Optimiser la longueur du prompt.
- Utiliser Annotated Text au lieu de PDF.
- Traiter les documents par lots en heures creuses.
- Envisager d’utiliser des modèles plus petits/moins coûteux pour les documents simples.
- Surveiller et définir des alertes de budget dans le tableau de bord du fournisseur LLM.
Techniques avancées
Extraction conditionnelle
Prise en charge multilingue
Règles de validation
Relations entre champs
Limitations et points à prendre en compte
Fonctionnalités actuelles
- ✅ Extraction de champs au niveau de l’en-tête
- ✅ Valeurs sur une ou plusieurs lignes
- ✅ Champs multiples par document
- ✅ Logique d’extraction conditionnelle
- ✅ Documents multilingues
- ✅ Mises en page de documents variables
- ⚠️ Extraction de tableaux (varie selon l’implémentation)
- ⚠️ Structures complexes imbriquées
- ⚠️ Documents très volumineux (limites de jetons)
- ⚠️ Traitement en temps réel (latence de l’API)
- ⚠️ Résultats entièrement déterministes garantis
Quand utiliser l’extraction basée sur des prompts
- Documents avec des mises en page variables
- Documents semi-structurés
- Prototypage et tests rapides
- Volumes de documents faibles à moyens
- Lorsque les données d’entraînement ne sont pas disponibles
- Traitement de documents en plusieurs langues
- Production à hauts volumes (le machine learning traditionnel peut être plus rapide)
- Formulaires fortement structurés (extraction basée sur des modèles)
- Applications sensibles aux coûts (les méthodes traditionnelles peuvent être moins chères)
- Applications sensibles à la latence (les API LLM introduisent une latence réseau)
- Besoins de traitement hors ligne (aucune connexion Internet nécessaire pour les méthodes traditionnelles)
Intégration avec les Compétences de document
Utilisation des données extraites
- Activités de validation : Appliquer des règles métier aux valeurs extraites.
- Activités de script : Traiter ou transformer les données extraites.
- Activités d’export : Envoyer les données vers des systèmes externes.
- Interface de révision : Vérification manuelle des champs extraits.
Combiner avec d’autres activités
Mappage des Fields
"FieldName": "Vendor.Name"→ Est mappé sur le champ de sortieVendor.Name.- La hiérarchie des champs est préservée dans la structure de sortie.
- Les numéros de ligne facilitent la vérification et le dépannage.
Récapitulatif
- ✅ Créer une activité d’extraction basée sur des prompts.
- ✅ Configurer une connexion à un LLM.
- ✅ Rédiger un prompt d’extraction complet avec rôle, format et règles.
- ✅ Sélectionner le format de document optimal (Annotated Text).
- ✅ Appliquer des règles de stricteté pour garantir la qualité des données.
- ✅ Tester l’extraction et examiner les résultats.
- ✅ Apprendre les meilleures pratiques pour l’ingénierie de prompts.
- L’extraction basée sur des prompts utilise des instructions en langage naturel.
- Le format Annotated Text fournit les meilleurs résultats.
- Des prompts clairs et spécifiques produisent une extraction cohérente.
- Les règles de stricteté empêchent les hallucinations et maintiennent la qualité des données.
- Des tests itératifs et un raffinement continu améliorent la précision.
Prochaines étapes
- Testez avec des documents variés : Validez-les sur différentes mises en page et variantes.
- Affinez vos prompts : Améliorez-les en continu en fonction des résultats.
- Surveillez les coûts : Suivez l’utilisation de jetons dans le tableau de bord de votre fournisseur de LLM.
- Optimisez les performances : Ajustez finement vos prompts pour la rapidité et la précision.
- Explorez l’extraction de tableaux : Expérimentez l’extraction de Lignes d’articles (si pris en charge).
- Intégrez-les à vos workflows : Combinez-les avec d’autres activités pour un traitement complet.
Ressources supplémentaires
- Documentation d’ABBYY Vantage Advanced Designer : https://docs.abbyy.com
- Guide de configuration des connexions LLM : Configurer les connexions LLM.
- Bonnes pratiques d’ingénierie de prompts : consultez la documentation de votre fournisseur de LLM.
- Assistance : contactez l’assistance ABBYY pour obtenir une aide technique.