概览
- 创建一个基于提示的提取活动
- 配置一个 LLM 连接
- 编写有效的提取提示
- 定义输出格式和结构
- 设置严格级别并应用校验规则
- 测试并改进你的提取方案
- 从发票中提取 Vendor(供应商)信息
- 提取文档抬头级数据
- 处理半结构化文档
- 处理布局多变的文档
前提条件
- 访问 ABBYY Vantage Advanced Designer 的权限
- 已配置好的 LLM 连接(参见如何配置 LLM 连接)
- 一个已加载示例文档的 Document Skill
- 对 JSON 结构的基本了解
- 针对您希望提取的数据预先设置好的字段定义
了解基于提示的提取
什么是基于提示的提取?
- 角色(Role):LLM 应该扮演的角色(例如,“数据提取模型”)
- 指令(Instructions):如何提取和格式化数据
- 输出结构(Output Structure):结果所需的精确 JSON 格式
- 规则(Rules):用于处理含糊或缺失数据的指南
优点
- 无需训练数据:只需进行提示词设计(prompt engineering)即可使用
- 灵活:可轻松添加或修改 field
- 处理多样性:大语言模型(LLM)能够理解不同的文档格式
- 快速配置:比训练传统机器学习模型更快
- 自然语言:使用简明英语编写指令
限制
- 成本:每次提取都会触发 LLM API 调用
- 速度:对于简单文档,比传统提取方式更慢
- 一致性:多次运行之间的结果可能会略有差异
- 上下文限制:非常长的文档可能需要特殊处理
步骤 1:添加基于提示的 Activity
- 在 ABBYY Vantage Advanced Designer 中打开您的 Document Skill
- 在左侧面板中找到 EXTRACT FROM TEXT (NLP)
- 找到并单击 Prompt-based
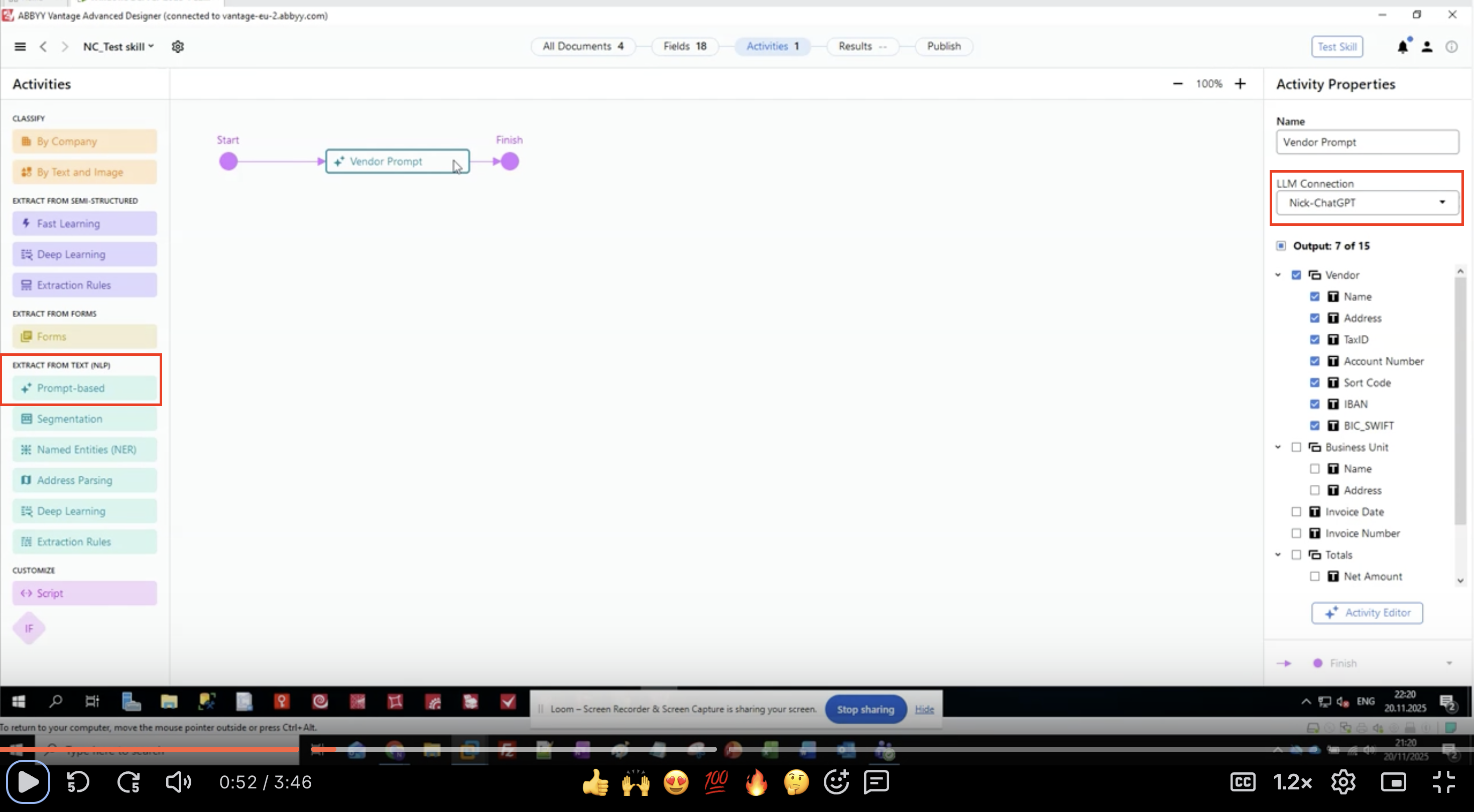
- 该 Activity 会出现在您的工作流画布中
- 将它连接在输入和输出 Activity 之间
注意: 基于提示的 Activity 位于 Activities 面板中的“EXTRACT FROM TEXT (NLP)”下,与 Named Entities (NER) 和 Deep Learning 等其他提取方法一起列出。
步骤 2:配置 LLM 连接
- 在你的工作流中选择基于提示的活动
- 在右侧的 Activity Properties 面板中,找到 LLM Connection
- 点击下拉菜单
-
从列表中选择你已配置好的 LLM 连接
- 示例:
Nick-ChatGPT、Microsoft Foundry、Production GPT-4
- 示例:
- 确认已选中该连接
步骤 3:定义输出字段
- 在 Activity Properties 面板中,找到 Output 部分
- 你将看到一个 field 组和 field 的分层列表
- 在此示例中,我们要提取 Vendor 信息:
- Vendor
- Name
- Address
- TaxID
- Account Number
- Sort Code
- IBAN
- BIC_SWIFT
- Business Unit
- Name
- Address
- Invoice Date
- Invoice Number
- Totals
- Net Amount
- Vendor
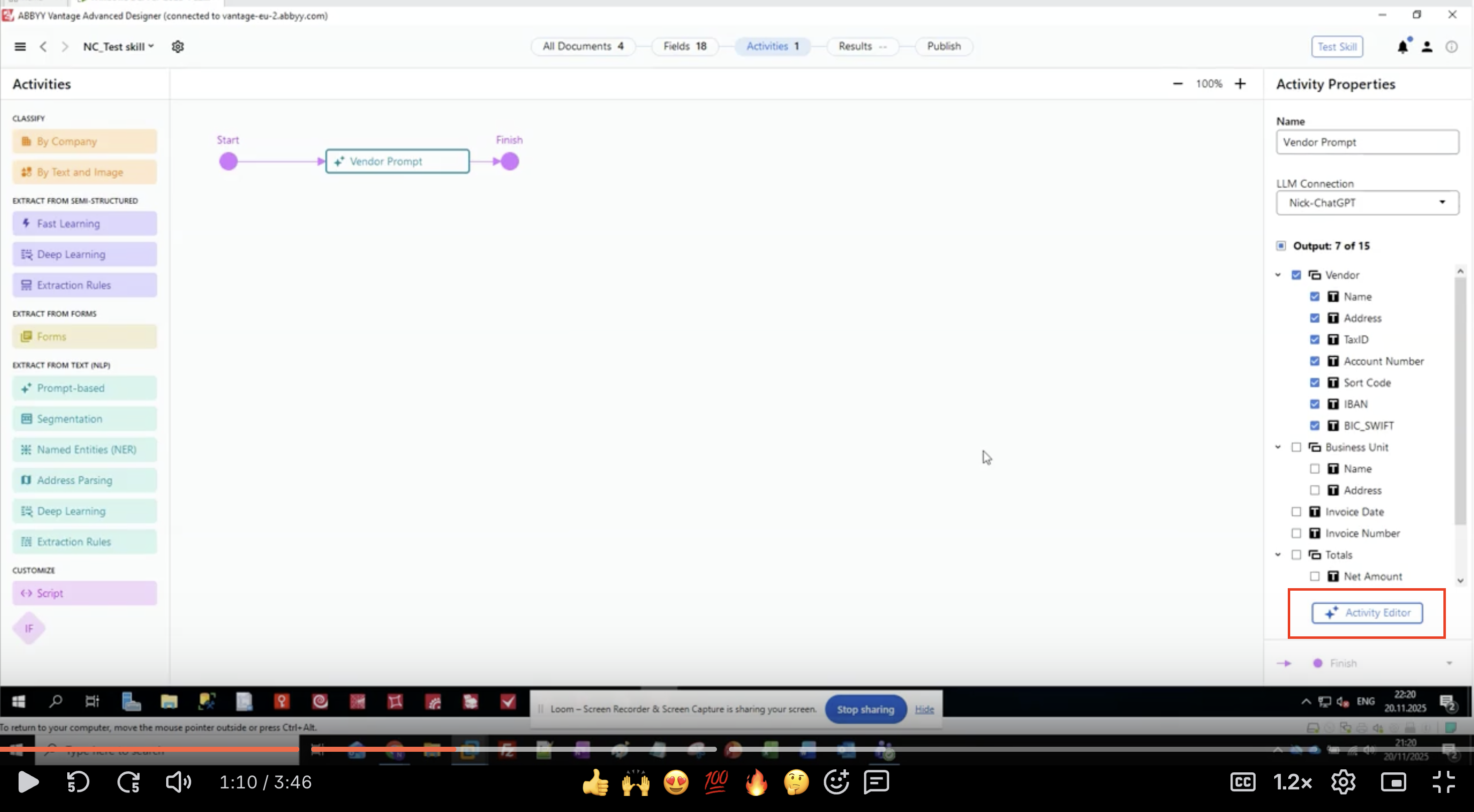
- 单击 Activity Editor 按钮,开始配置 prompt
步骤 4:编写角色定义
- 在 Activity Editor 中,您会看到 Prompt Text 界面。
- 从 ROLE 部分开始:
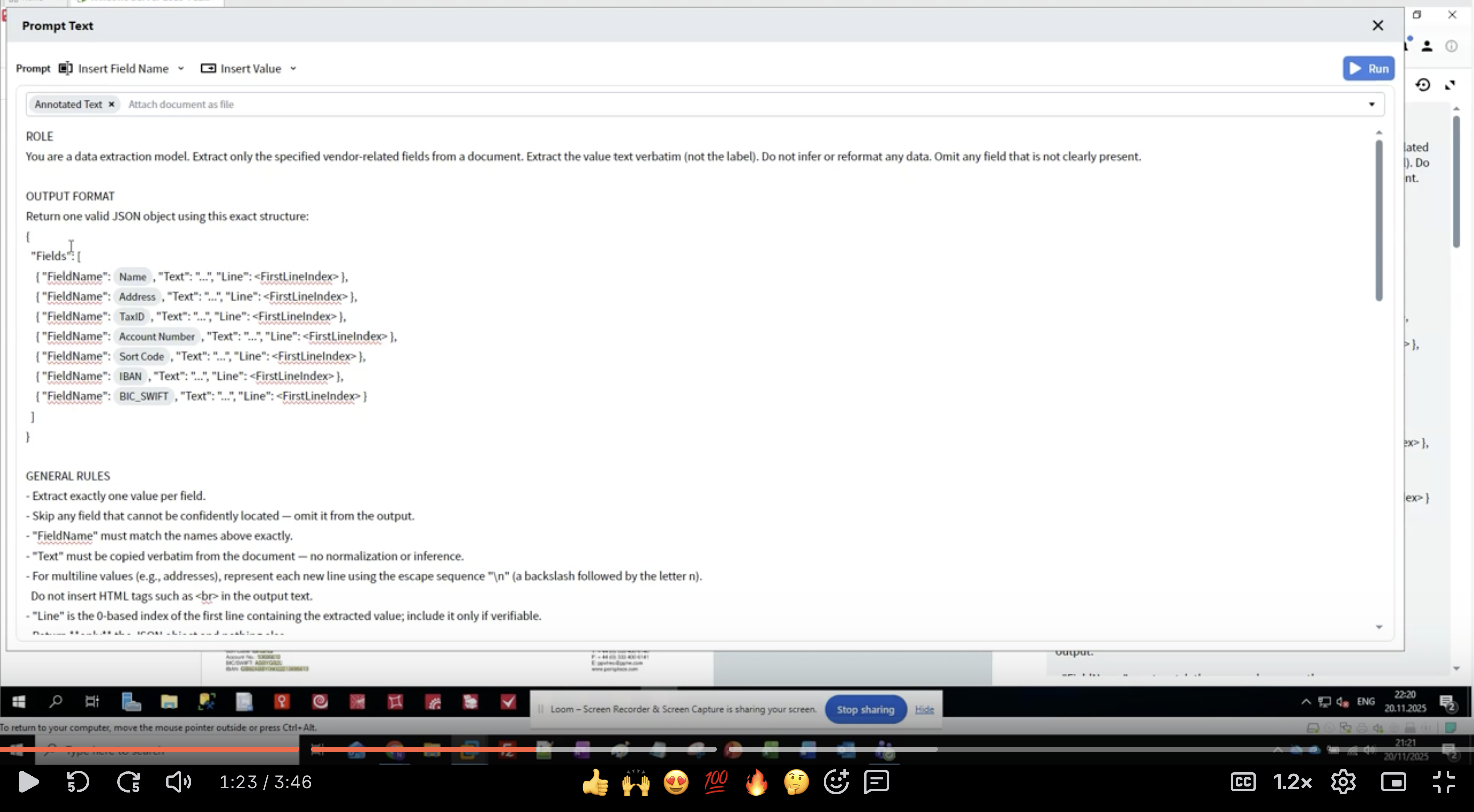
- 要具体:使用 “data extraction model” 告诉 LLM 它的目的
- 定义范围:使用 “vendor-related fields” 限定要提取的内容
- 设定预期:使用 “value text verbatim” 表示按原文保留文本值,避免重新格式化
- 处理缺失数据:使用 “Omit any field that is not clearly present” 表示省略任何未清晰出现的 field
- 保持角色指令清晰简洁
- 使用祈使句(“Extract”、“Do not infer”)
- 明确说明不应该做什么
- 定义如何处理边缘/极端情况
步骤 5:定义输出格式
- 在 ROLE 部分下方添加 OUTPUT FORMAT 标题
- 定义 JSON 结构:
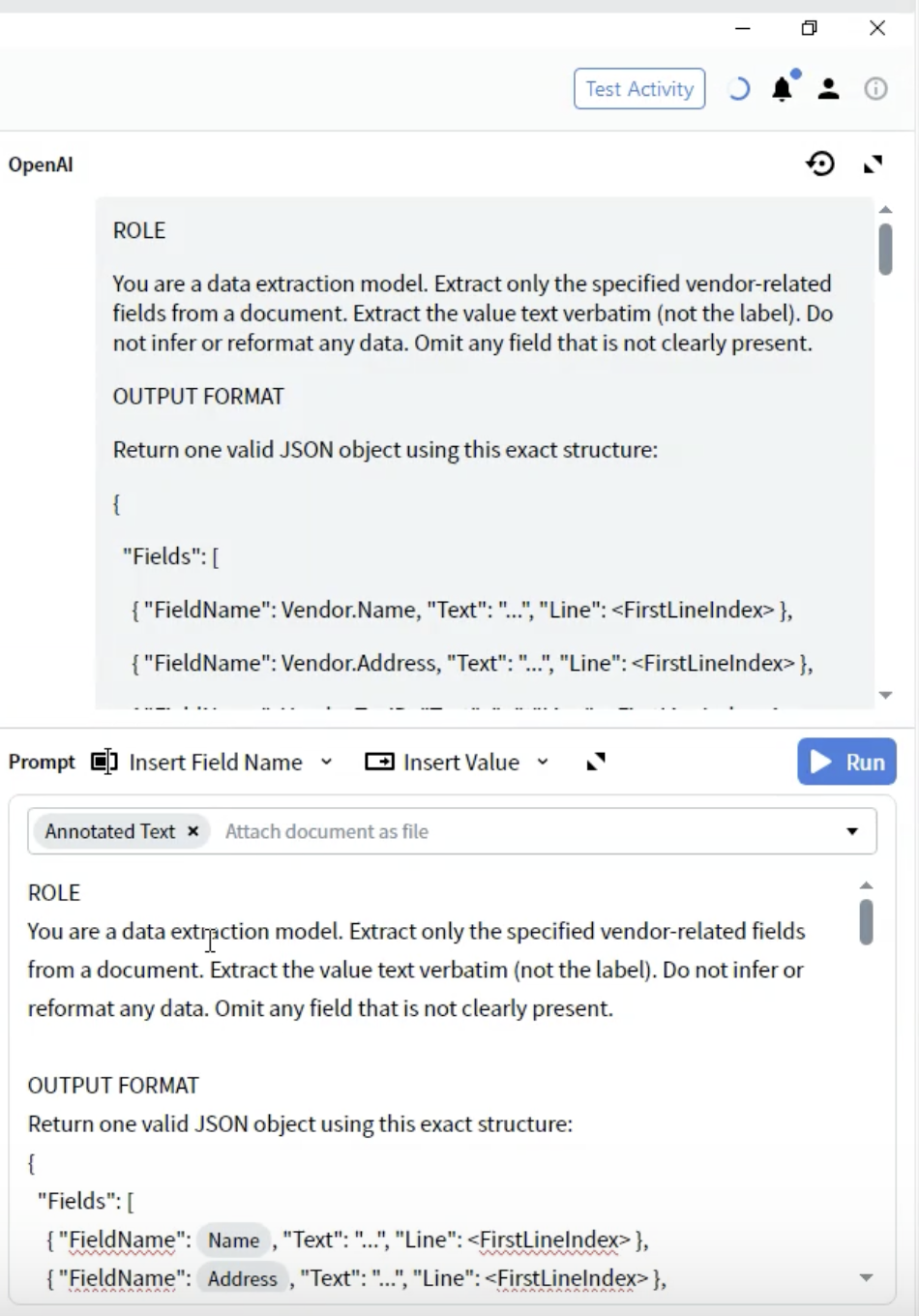
- FieldName:必须与您的 field 定义完全匹配(例如,
Vendor.Name) - Text:提取出的值,类型为 string
- Line:该值在文档中出现位置的从 0 开始的行索引
- 使用 Output 配置中定义的精确 field 名称
- 包含所有 field,即使其中某些可能为空
- 结构必须是有效的 JSON
- 行号有助于验证和排查问题
步骤 6:添加针对 field 的提取规则
- 识别模式:为每个 field 列出备选标签
- 格式规范:描述要抽取数据的精确格式
- 位置提示:通常可以在哪些位置找到该数据
- 排除项:明确不要抽取的内容
- 为规则编号以提高可读性
- 提供标签的多种变体
- 指明数据归属(Vendor 端 vs. 客户端)
- 在括号中包含格式示例
- 明确说明相关字段(例如:“忽略 IBAN——它有自己的 field”)
步骤 7:应用严格程度规则
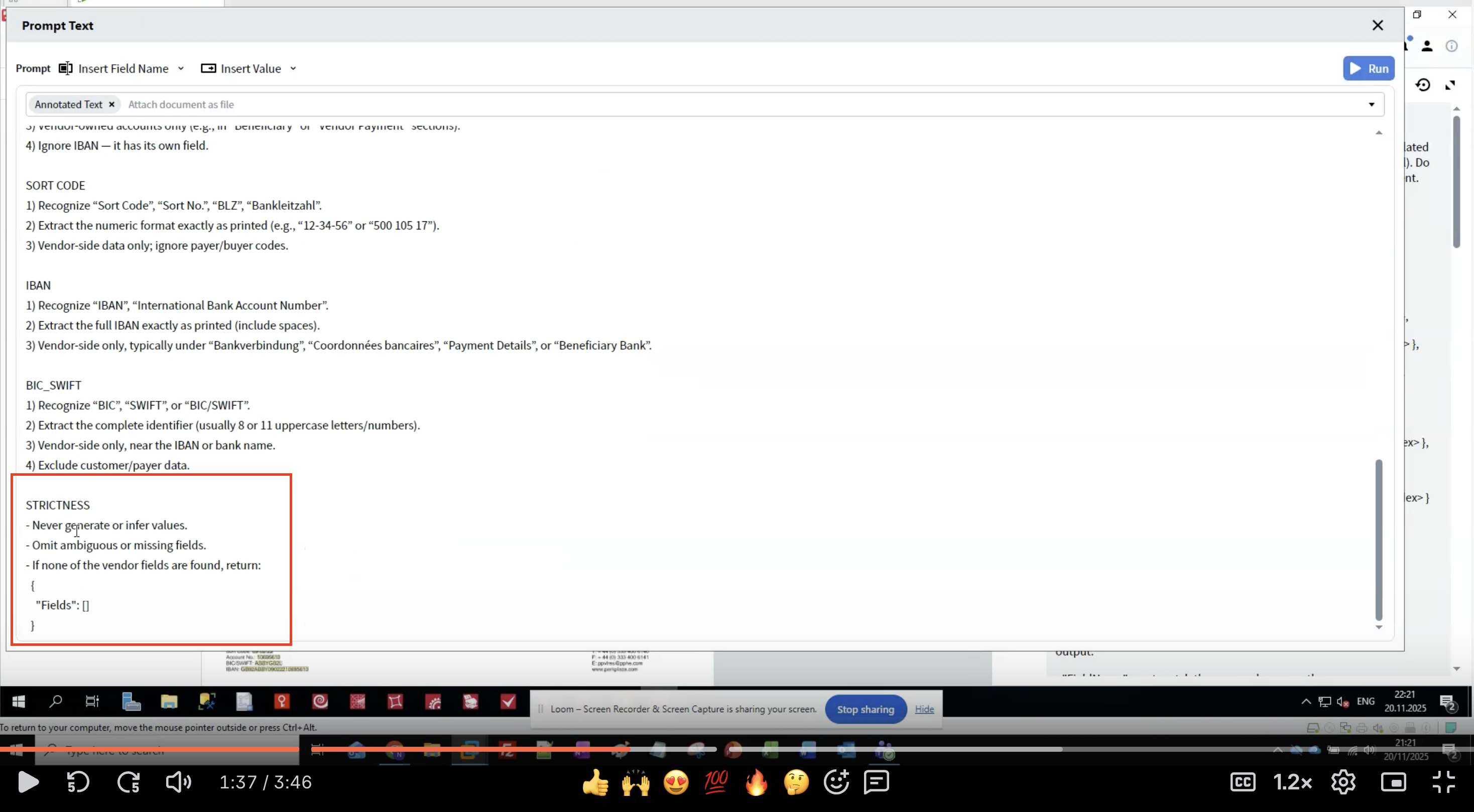
- 防止幻觉式生成:LLM 可能生成看似合理但不正确的数据
- 确保一致性:清晰的规则可减少不同运行之间的差异
- 处理缺失数据:明确在未找到 field 时该如何处理
- 维护数据完整性:逐字提取可保留原始格式
- 切勿生成文档中不存在的任何数据
- 对不确定的提取结果,应当省略而不是猜测
- 如果未找到任何 fields,则返回空结构
- 精确匹配 field 名称
- 保留原始文本格式
步骤 8:选择文档格式
- 在 Activity Editor 中,找到 Prompt 下拉列表
- 你会看到关于如何将文档提供给 LLM 的不同选项
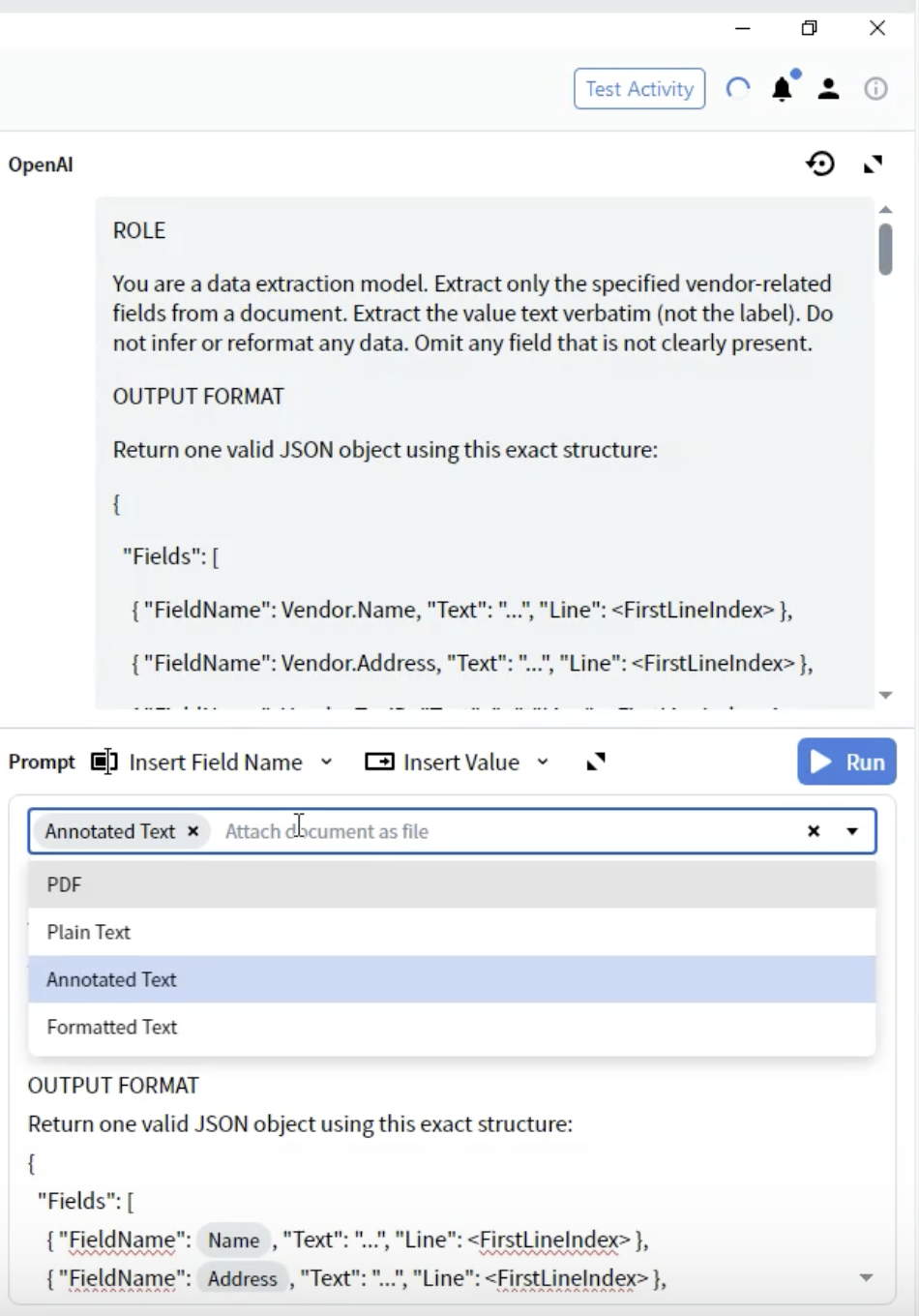
-
PDF:原始 PDF 文件
- 适用于:版式至关重要的文档
- 注意事项:文件体积较大,一些 LLM 对 PDF 的支持有限
-
Plain Text:未格式化的文本提取
- 适用于:简单的纯文本文档
- 注意事项:会丢失所有格式和版面信息
-
Annotated Text ⭐(推荐)
- 适用于:大多数文档类型
- 注意事项:在保持基于文本的同时保留结构
- 优点:在结构完整性与处理性能之间实现最佳平衡
-
Formatted Text:保留基本格式的文本
- 适用于:对部分格式有要求的文档
- 注意事项:在 Plain 和 Annotated 之间的折中方案
- 选择 Annotated Text 以获得最佳处理效果
步骤 9:测试提取结果
在示例文档上运行该活动以验证结果。运行 Activity
- 关闭 Activity Editor
- 转到 All Documents 选项卡
- 选择一个测试文档
- 单击 Test Activity 或 Run 按钮
- 等待 LLM 处理该文档
- 处理时间:通常为 5–30 秒,具体取决于文档的复杂度
- 在等待 API 响应时,您会看到加载指示器
查看结果
- 界面将切换到 Predictive view
- 查看显示已提取字段的 Output 面板
- 单击每个 field 查看:
- 提取的值
- 置信度(如果提供)
- 文档图像上的高亮区域
- ✅ 所有预期的 field 都已填充
- ✅ 值与文档完全匹配
- ✅ 没有幻觉或推断出来的数据
- ✅ 正确处理多行 field
- ✅ 缺失的 field 被省略(不会用不正确的数据填充)
常见结果模式
提取成功:步骤 10:优化提示词
根据测试结果对提示词进行迭代和优化。常见问题与解决方案
- 解决方案:添加更具体的位置提示
- 示例:“仅限 Vendor 侧;排除客户/买方地址”
- 解决方案:强调按原样逐字提取
- 示例:“严格按打印内容原样提取数字格式(例如:‘12-34-56’)”
- 解决方案:收紧严格规则
- 示例:“严禁生成或推断任何取值。如不存在则留空/省略。”
- 解决方案:指定转义序列
- 示例:“对于多行取值,使用
\n表示换行”
- 解决方案:确认 field 名称完全一致
- 示例:使用
Vendor.Account Number而不是AccountNumber
迭代改进流程
- 在多个文档上测试:不要只针对单个示例进行优化
- 记录规律:标记哪些规则有效,哪些需要进一步优化
- 添加具体示例:在括号中给出格式示例
- 调整严格程度:根据抽取过多/抽取不足的情况进行调整
- 测试边缘情况:尝试处理缺少 field、版式异常的文档
示例改进
改进前:理解提取流程
基于提示的抽取工作原理
- 文档转换:将你的文档转换为所选格式(推荐使用 Annotated Text)
- 提示组装:将你的角色设定、输出格式、field 规则和严格性规则组合在一起
- API 调用:通过你的连接将提示和文档发送给 LLM
- LLM 处理:LLM 阅读文档并根据你的指令抽取数据
- JSON 响应:LLM 按指定的 JSON 格式返回结构化数据
- 字段映射:Vantage 将 JSON 响应映射到你定义的输出 fields
- 验证:行号和置信度分数(如果提供)有助于验证准确性
Token 使用量和成本
影响成本的因素:- Document 长度:Document 越长,消耗的 token 越多
- Prompt 复杂度:Prompt 越详细,token 数量越多
- 格式选择:Annotated Text 通常比 PDF 更高效
- fields 数量:fields 越多,prompt 越长
- 在 prompt 中使用简洁但清晰的语言
- 不要重复说明相同的指令
- 删除不必要的示例
- 考虑将相关数据的 field 进行分组处理
最佳实践
提示词编写
- ✅ 使用清晰的祈使句(如 “Extract”、“Recognize”、“Omit”)
- ✅ 为每个 field 提供多个标签变体
- ✅ 在括号中给出格式示例
- ✅ 明确说明不应提取的内容(排除项)
- ✅ 为规则编号,便于引用
- ✅ 全文保持术语一致
- ❌ 使用含糊的指令(如 “get the name”)
- ❌ 假设 LLM 熟悉特定领域/行业约定
- ❌ 使用过长、过于复杂的句子
- ❌ 在不同部分给出互相矛盾的说明
- ❌ 省略关于严格性的规则
Field 定义
- 先定义识别模式(替代标签)
- 明确需要保留的精确格式
- 提供位置提示(常见放置位置)
- 明确数据归属(Vendor 与客户)
- 说明多行值的处理方式
- 引用相关 fields 以避免混淆
测试策略
- 从简单的文档开始:先测试基本抽取
- 扩展到各种变体:尝试不同的版式和格式
- 测试边界情况:缺失的field、异常位置、多重匹配
- 记录失败案例:保留抽取失败的示例
- 有条理地迭代:每次只更改一个因素
性能优化
提升速度:- 保持提示词简洁
- 使用 Annotated Text 格式
- 将每个活动中的 field 数量降到最少
- 考虑拆分复杂文档
- 提供全面的 field 规则
- 包含格式示例
- 添加更严格的约束规则
- 使用多样化的文档样本进行测试
- 优化提示词长度
- 使用高效的文档格式
- 在合适的情况下缓存结果
- 通过 LLM 提供方的仪表板监控 token 使用量
故障排除
抽取问题
- 检查 field 名称拼写是否完全一致
- 验证数据是否符合所选的文档格式
- 为识别模式添加更多标签变体
- 暂时降低严格性以查看 LLM 是否能找到该数据
- 检查文档质量是否影响 OCR/文本抽取
- 加强对 Vendor 侧的规范说明
- 为客户/买方数据添加明确的排除规则
- 提供位置提示(例如:“文档顶部”、“发行方区域”)
- 提供正确与错误抽取的示例
- 明确指定换行转义序列格式(
\n) - 提供正确多行输出的示例
- 验证文档格式是否保留换行
- 添加指令:“使用
\n保留原始换行”
- 强调“逐字输出”(verbatim)及“与打印内容完全一致”
- 添加严格规则:“禁止规范化或推断”
- 提供保留原始格式的具体示例
- 包含反面示例:“不要改成 ‘12-34-56’,保持为 ‘12 34 56’”
性能问题
问题: 提取速度过慢 解决方案:- 如果使用 PDF,切换为 Annotated Text 格式
- 在不丢失关键指令的前提下简化提示词
- 如果图像非常大,降低文档分辨率
- 检查 LLM 提供商的服务状态和速率限制
- 针对简单文档考虑使用更快的模型
- 提高严格性相关设置
- 使指令更加具体且不含歧义
- 添加更多格式示例
- 降低提示词复杂度,避免产生多重解释
- 在更高的 temperature 设置下进行测试(如果当前连接支持)
- 优化提示词长度
- 使用 Annotated Text 而不是 PDF
- 在非高峰时段批量处理文档
- 针对简单文档考虑使用更小/更便宜的模型
- 在 LLM 提供商控制台中监控并设置预算预警
高级技巧
条件提取
多语言支持
校验规则
字段关系
指定 field 之间的相互关系:限制和注意事项
当前功能
- ✅ 抬头级 field 提取
- ✅ 单行和多行值
- ✅ 每个文档包含多个 field
- ✅ 条件提取逻辑
- ✅ 多语言文档
- ✅ 可变文档版式
- ⚠️ 表格提取(支持情况因具体实现而异)
- ⚠️ 嵌套的复杂结构
- ⚠️ 超大文档(受 token 限制)
- ⚠️ 实时处理(API 延迟)
- ⚠️ 结果确定性的保证
何时使用基于 Prompt 的抽取
最适用于:- 布局多变的文档
- 半结构化文档
- 快速原型设计与测试
- 小到中等规模的文档处理量
- 无法获得训练数据的场景
- 多语言文档处理
- 大规模生产环境(传统机器学习可能更快)
- 高度结构化的表单(基于模板的抽取)
- 对成本高度敏感的应用(传统方法可能更便宜)
- 对时延极为敏感的应用(LLM API 存在网络延迟)
- 需要离线处理的场景(传统方法不需要互联网连接)
与 Document Skills 的集成
使用已提取数据
- 验证活动:对已提取的值应用业务规则
- 脚本活动:处理或转换已提取的数据
- 导出活动:将数据发送到外部系统
- 审核界面:对已提取字段进行人工验证
与其他 Activity 组合使用
字段映射
提取的 JSON 字段会自动映射到您定义的输出字段:"FieldName": "Vendor.Name"→ 映射到输出字段Vendor.Name- 字段层级在输出结构中会保留
- 行号有助于验证和故障排查
总结
- ✅ 创建了一个基于提示的提取活动
- ✅ 配置了一个 LLM 连接
- ✅ 编写了包含角色、格式和规则的全面提取提示
- ✅ 选择了最佳文档格式(Annotated Text)
- ✅ 应用了严格规则以确保数据质量
- ✅ 对提取进行了测试并审查了结果
- ✅ 学习了提示工程的最佳实践
- 基于提示的提取使用自然语言指令
- Annotated Text 格式能提供最佳结果
- 清晰、具体的提示能带来一致的提取效果
- 严格规则可防止幻觉并保持数据质量
- 迭代测试和优化可以提升准确性
后续步骤
- 使用多种类型的文档进行测试:在不同版式和变体上进行验证
- 优化你的提示词:根据结果持续改进
- 监控成本:在 LLM 提供商的控制台中跟踪 token 使用量
- 优化性能:为速度和准确性微调提示词
- 探索表格提取:尝试提取明细行(如果支持)
- 集成到工作流中:与其他步骤组合以实现完整处理
其他资源
- ABBYY Vantage Advanced Designer 文档: https://docs.abbyy.com
- LLM 连接配置指南: 如何配置 LLM 连接
- 提示工程最佳实践: 请参阅您的 LLM 服务提供商的相关文档
- 支持: 如需技术支持,请联系 ABBYY 支持团队