Übersicht
- Erstellen einer promptbasierten Extraktionsaktivität
- Konfigurieren einer LLM-Verbindung
- Formulieren wirkungsvoller Extraktionsprompts
- Definieren von Ausgabeformat und -struktur
- Anwenden von Strenge und Validierungsregeln
- Testen und Verfeinern Ihrer Extraktion
- Extraktion von Vendor-Informationen aus Rechnungen
- Erfassung von Kopfdaten auf Dokumentebene
- Verarbeitung halbstrukturierter Dokumente
- Dokumente mit variablen Layouts
Voraussetzungen
- Zugriff auf ABBYY Vantage Advanced Designer
- Eine konfigurierte LLM-Verbindung (siehe Konfigurieren von LLM-Verbindungen)
- Einen Document-Skill mit geladenen Beispieldokumenten
- Grundlegendes Verständnis der JSON-Struktur
- Felddefinitionen für die Daten, die Sie extrahieren möchten
Grundlagen der promptbasierten Extraktion
Was ist Prompt-basierte Extraktion?
- Rolle: Welche Rolle das LLM einnehmen soll (z. B. „Datenextraktionsmodell“)
- Anweisungen: Wie Daten extrahiert und formatiert werden sollen
- Ausgabestruktur: Das genaue JSON-Format für die Ergebnisse
- Regeln: Richtlinien für den Umgang mit mehrdeutigen oder fehlenden Daten
Vorteile
- Keine Trainingsdaten erforderlich: Funktioniert allein durch Prompt-Engineering
- Flexibel: Felder lassen sich leicht hinzufügen oder ändern
- Kommt mit Varianten zurecht: LLMs können unterschiedliche Dokumentformate verstehen
- Schnelle Einrichtung: Schneller als das Trainieren herkömmlicher ML-Modelle
- Natürliche Sprache: Anweisungen in einfachem Englisch verfassen
Einschränkungen
- Kosten: Jede Extraktion führt LLM-API-Aufrufe aus
- Geschwindigkeit: Langsamer als die herkömmliche Extraktion bei einfachen Dokumenten
- Konsistenz: Ergebnisse können von Ausführung zu Ausführung leicht variieren
- Kontextgrenzen: Sehr lange Dokumente müssen möglicherweise speziell behandelt werden
Schritt 1: Prompt-basierte Activity hinzufügen
- Öffnen Sie Ihren Document-Skill in ABBYY Vantage Advanced Designer
- Suchen Sie im linken Bereich EXTRACT FROM TEXT (NLP)
- Suchen Sie Prompt-based und klicken Sie darauf
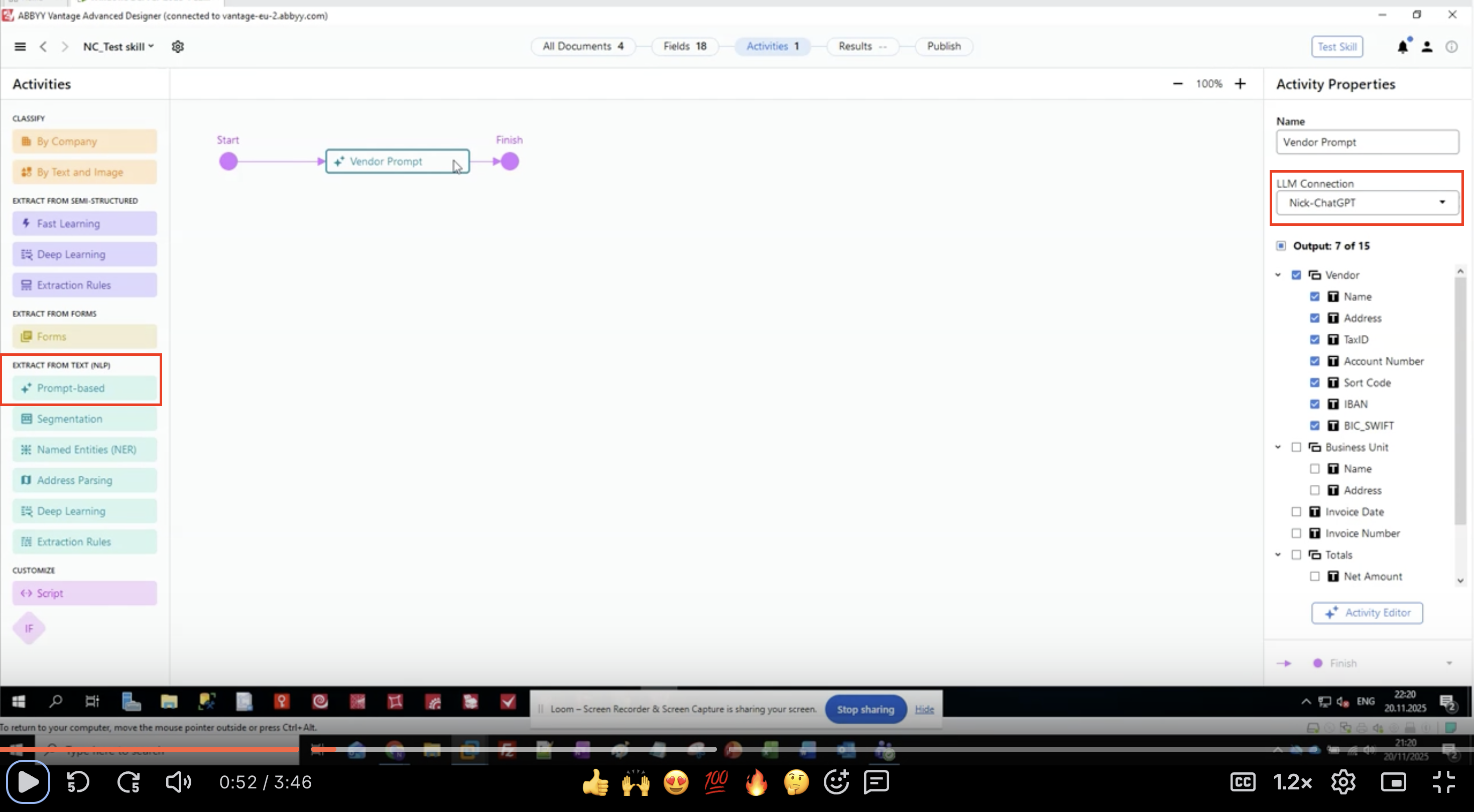
- Die Activity erscheint in Ihrem Workflow-Canvas
- Verbinden Sie sie zwischen Ihren Eingabe- und Ausgabe-Activities
Schritt 2: LLM-Verbindung konfigurieren
- Wählen Sie die prompt-basierte Aktivität in Ihrem Workflow aus
- Suchen Sie im Bereich Activity Properties auf der rechten Seite nach LLM Connection
- Klicken Sie auf das Dropdown-Menü
-
Wählen Sie Ihre konfigurierte LLM-Verbindung aus der Liste aus
- Beispiel:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Beispiel:
- Vergewissern Sie sich, dass die Verbindung ausgewählt ist
Schritt 3: Ausgabefelder definieren
- Suchen Sie im Bereich Activity Properties den Abschnitt Output.
- Sie sehen eine hierarchische Liste von Feldgruppen und Feldern.
- In diesem Beispiel extrahieren wir Vendor-Informationen:
- Vendor
- Name
- Adresse
- TaxID
- Kontonummer
- Bankleitzahl
- IBAN
- BIC_SWIFT
- Geschäftseinheit
- Name
- Adresse
- Rechnungsdatum
- Rechnungsnummer
- Summen
- Nettobetrag
- Vendor
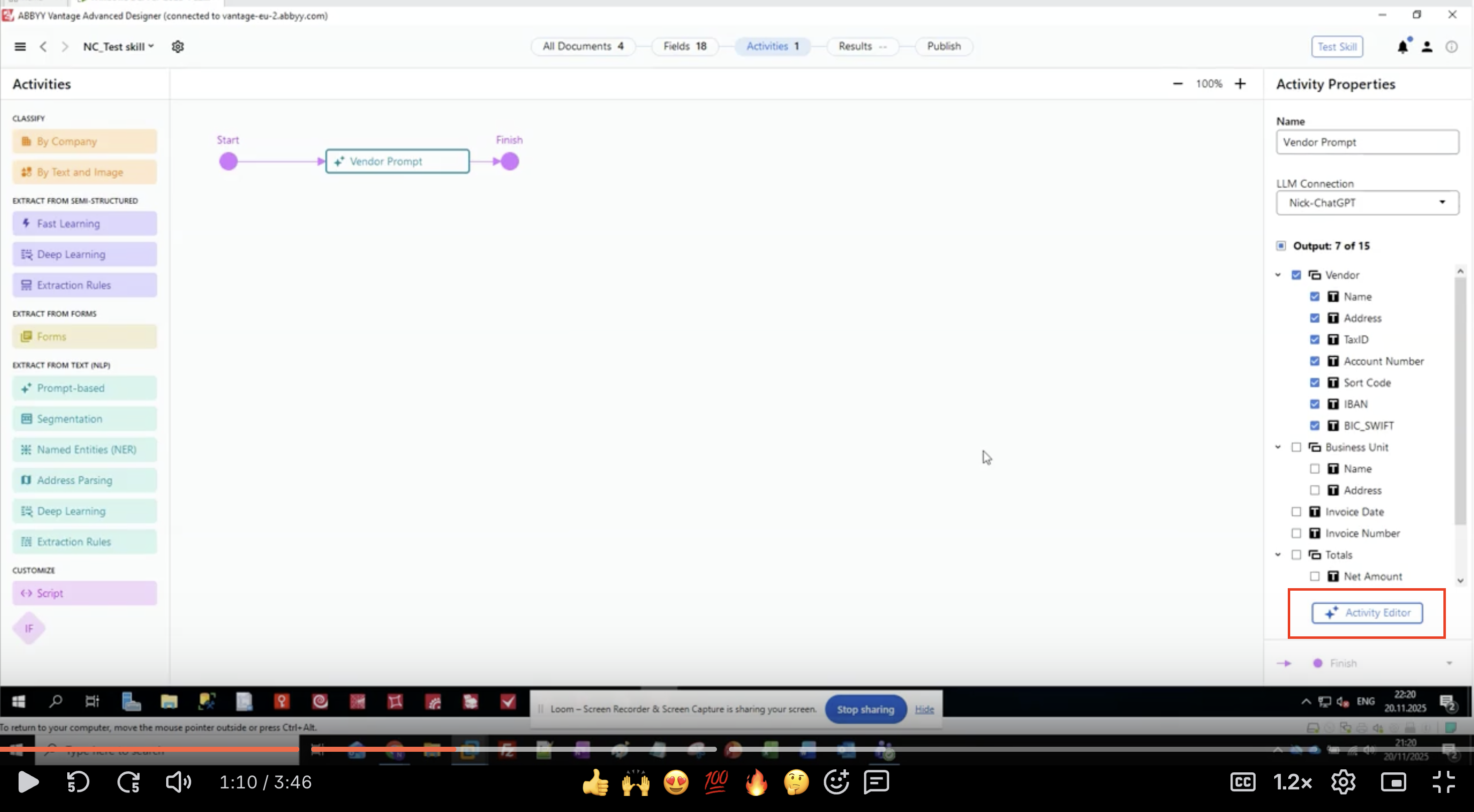
- Klicken Sie auf die Schaltfläche Activity Editor, um mit der Konfiguration Ihres Prompts zu beginnen.
Schritt 4: Rollendefinition verfassen
- Im Activity Editor sehen Sie die Oberfläche Prompt Text
- Beginnen Sie mit dem Abschnitt ROLE:
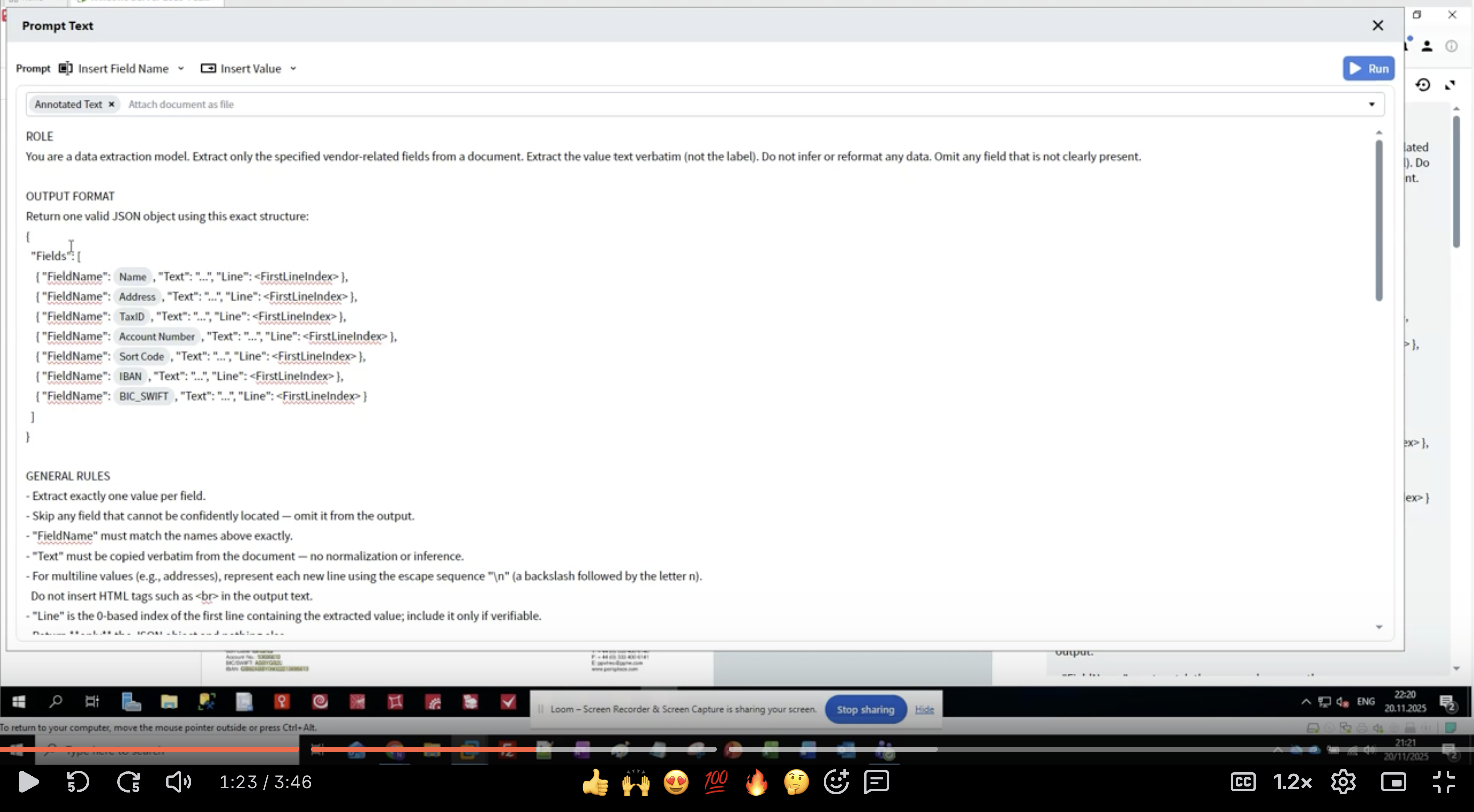
- Seien Sie konkret: “data extraction model” teilt dem LLM seinen Zweck mit
- Umfang festlegen: “vendor-related fields” begrenzt, was extrahiert werden soll
- Erwartungen festlegen: “value text verbatim” verhindert eine Neuformatierung
- Mit fehlenden Daten umgehen: “Omit any field that is not clearly present”
- Halten Sie die Rollenbeschreibung klar und prägnant
- Verwenden Sie Imperativsätze (“Extract”, “Do not infer”)
- Seien Sie ausdrücklich darin, was NICHT getan werden soll
- Legen Sie fest, wie Grenzfälle zu behandeln sind
Schritt 5: Ausgabeformat definieren
- Fügen Sie unterhalb des Abschnitts ROLE die Überschrift OUTPUT FORMAT hinzu.
- Definieren Sie die JSON-Struktur:
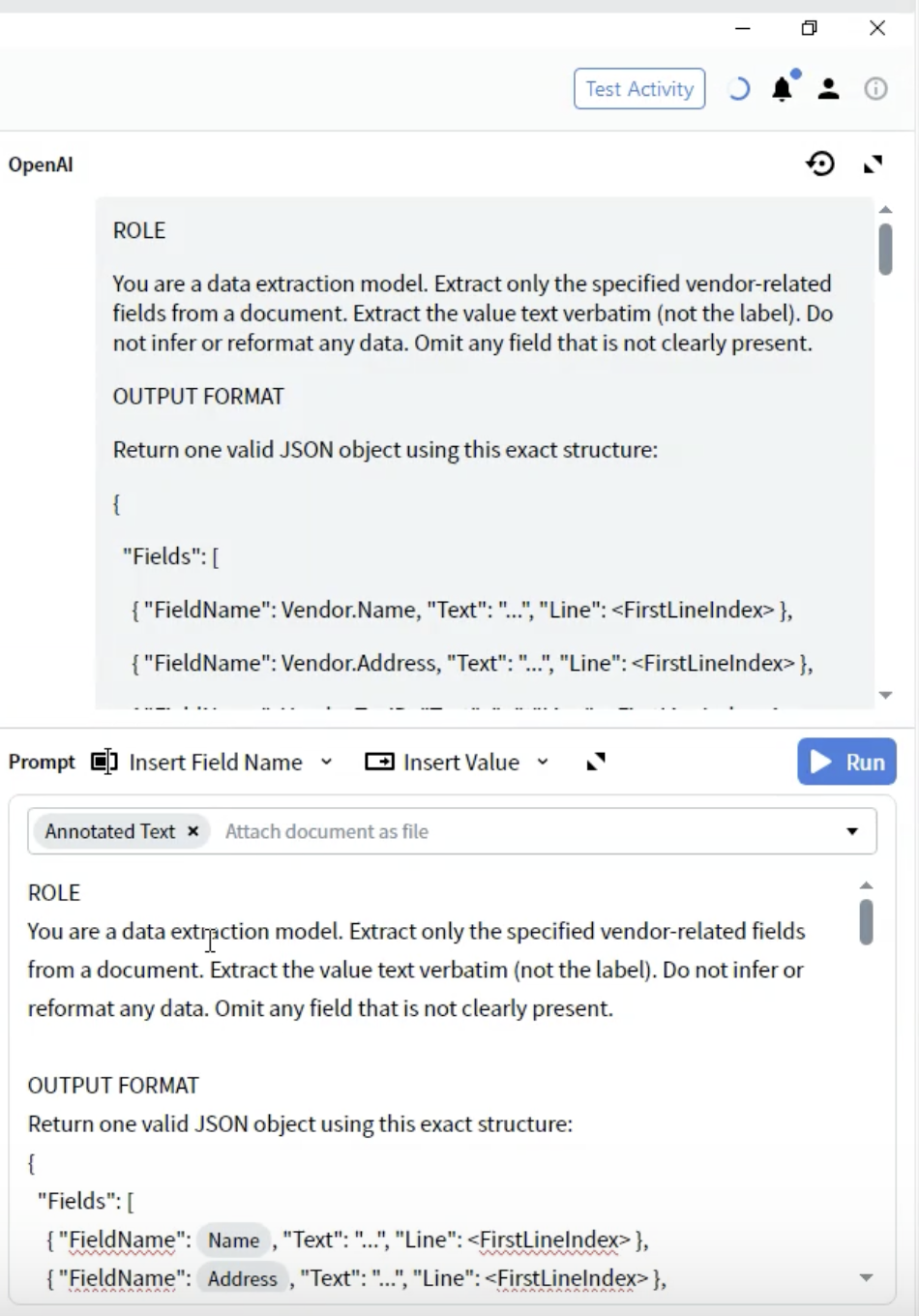
- FieldName: Muss exakt mit Ihren Felddefinitionen übereinstimmen (z. B.
Vendor.Name) - Text: Der extrahierte Wert als
string - Line: 0-basierter Zeilenindex, an dem der Wert im Dokument erscheint
- Verwenden Sie die exakten Feldnamen aus Ihrer Ausgabekonfiguration
- Schließen Sie alle Felder ein, selbst wenn einige leer sein können
- Die Struktur muss gültiges JSON sein
- Zeilennummern unterstützen die Verifizierung und Fehlersuche
Schritt 6: Feldspezifische Extraktionsregeln hinzufügen
- Erkennungsmuster: Führen Sie alternative Bezeichnungen für jedes Feld auf
- Formatvorgaben: Beschreiben Sie das genaue zu extrahierende Format
- Positionshinweise: Wo die Daten typischerweise zu finden sind
- Ausschlüsse: Was NICHT extrahiert werden soll
- Nummerieren Sie Ihre Regeln für bessere Übersicht
- Geben Sie mehrere Bezeichnungsvarianten an
- Geben Sie an, wem die Daten zugeordnet sind (auf Vendor-Seite vs. auf Kundenseite)
- Fügen Sie Formatbeispiele in Klammern hinzu
- Seien Sie explizit in Bezug auf zugehörige Felder (z. B. „IBAN ignorieren – sie hat ein eigenes Feld“)
Schritt 7: Strictness-Regeln anwenden
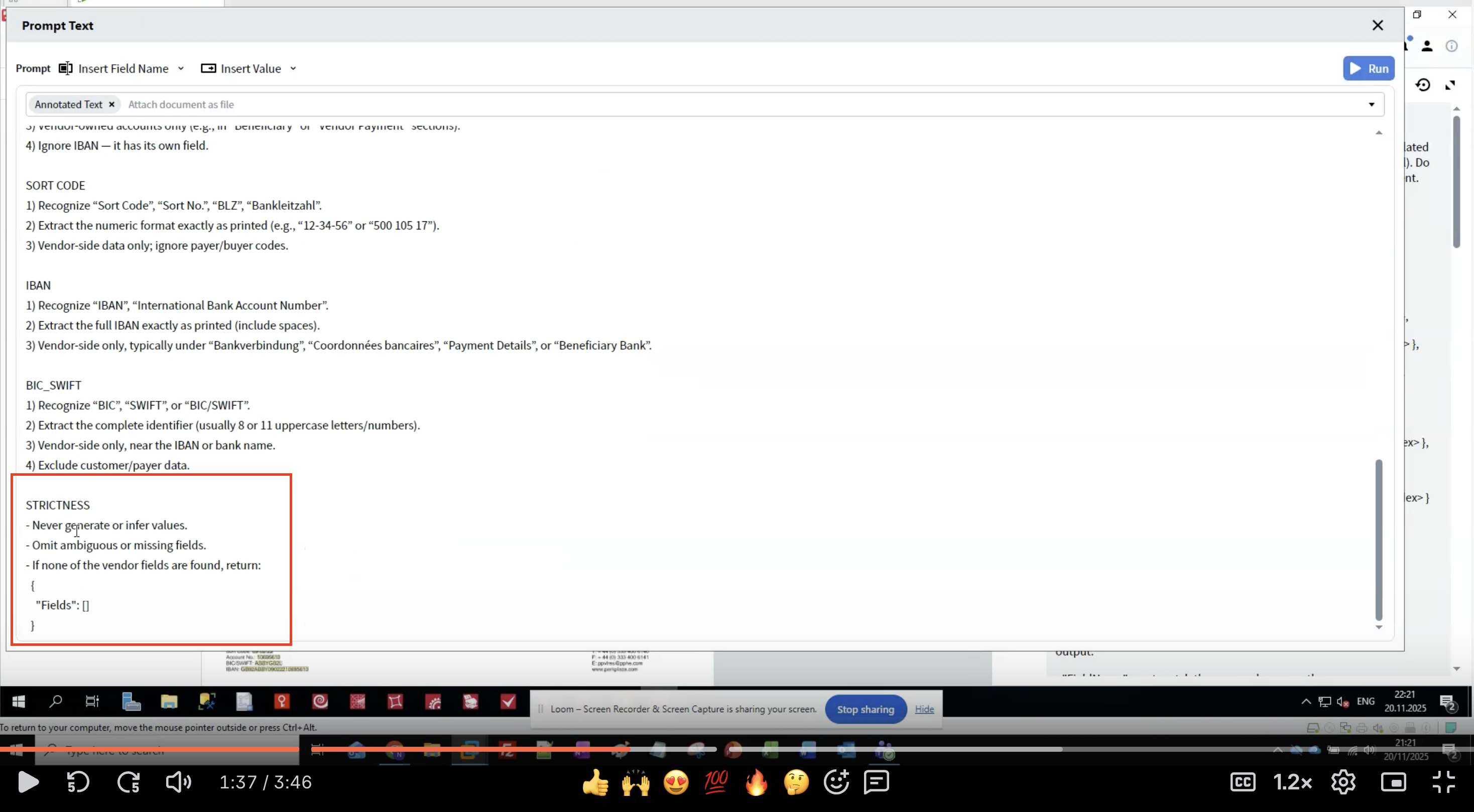
- Verhindert Halluzinationen: LLMs können plausibel wirkende, aber falsche Daten erzeugen
- Sorgt für Konsistenz: Klare Regeln verringern Schwankungen zwischen Ausführungen
- Regelt den Umgang mit fehlenden Daten: Definiert, was zu tun ist, wenn Felder nicht gefunden werden
- Erhält die Datenintegrität: Wortgetreue Extraktion bewahrt das ursprüngliche Format
- Niemals Daten generieren, die nicht im Dokument stehen
- Unsichere Extraktionen weglassen, statt zu raten
- Leere Struktur zurückgeben, wenn keine Felder gefunden werden
- Feldnamen exakt übernehmen
- Ursprüngliche Textformatierung beibehalten
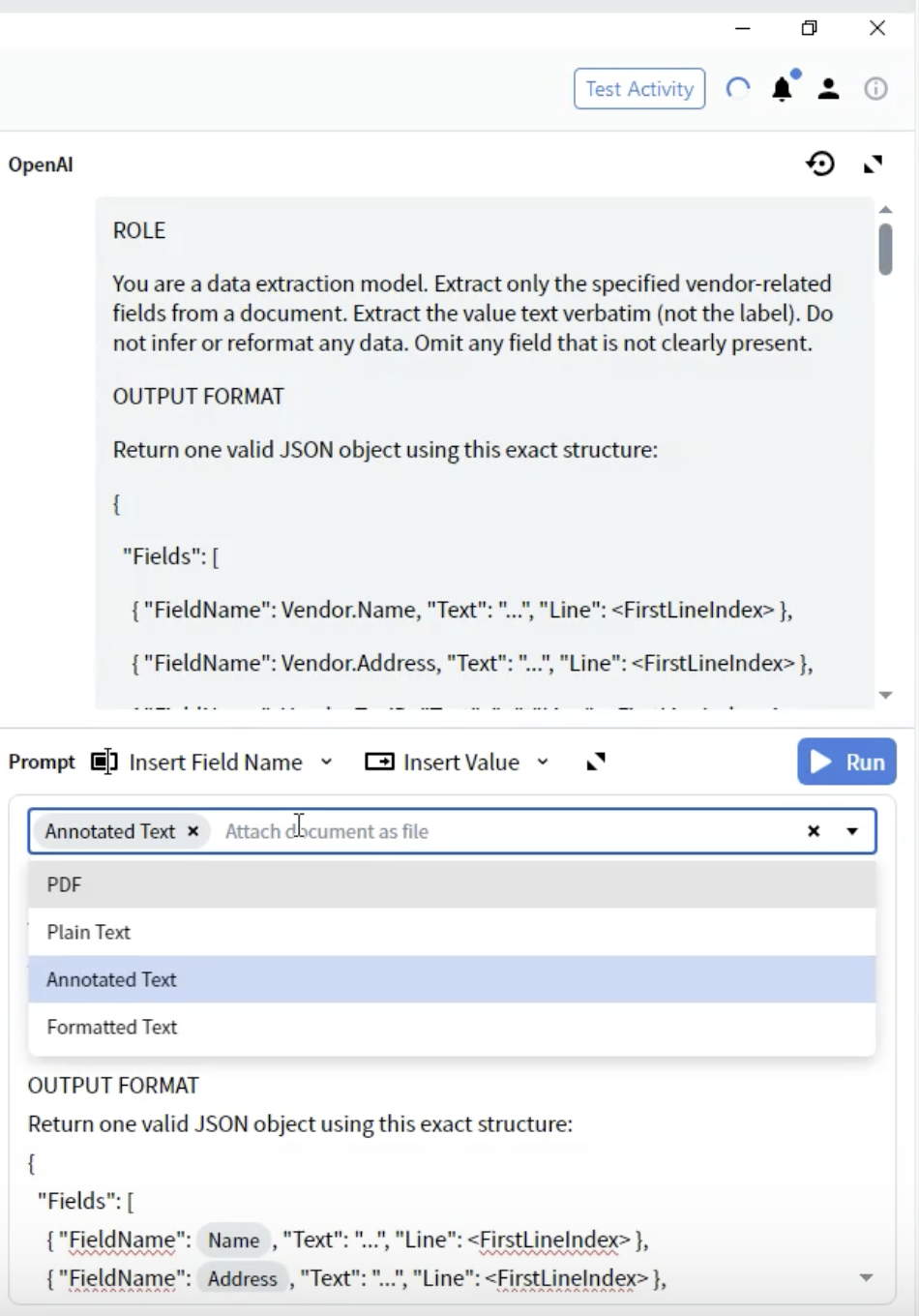
Schritt 8: Dokumentformat auswählen
- Suchen Sie im Activity Editor das Prompt-Dropdown-Menü.
- Sie sehen Optionen dafür, wie das Dokument dem LLM bereitgestellt wird.
-
PDF: Originale PDF-Datei
- Geeignet für: Dokumente, bei denen das Layout entscheidend ist
- Hinweise: Größere Dateigröße, einige LLMs haben eingeschränkte PDF-Unterstützung
-
Plain Text: Unformatierte Textextraktion
- Geeignet für: Einfache, reine Textdokumente
- Hinweise: Verliert sämtliche Informationen zu Formatierung und Layout
-
Annotated Text ⭐ (Empfohlen)
- Geeignet für: Die meisten Dokumenttypen
- Hinweise: Erhält die Struktur und bleibt gleichzeitig textbasiert
- Vorteile: Beste Balance zwischen Struktur und Performance
-
Formatted Text: Text mit grundlegender Formatierung
- Geeignet für: Dokumente, bei denen eine gewisse Formatierung wichtig ist
- Hinweise: Mittelweg zwischen Plain und Annotated
- Wählen Sie Annotated Text für bestmögliche Ergebnisse.
Schritt 9: Testen Sie Ihre Extraktion
Aktivität ausführen
- Schließen Sie den Activity Editor
- Navigieren Sie zum Reiter All Documents
- Wählen Sie ein Testdokument aus
- Klicken Sie auf Test Activity oder auf die Schaltfläche Run
- Warten Sie, bis das LLM das Dokument verarbeitet hat
- Verarbeitungszeit: in der Regel 5–30 Sekunden, abhängig von der Komplexität des Dokuments
- Während Sie auf die API-Antwort warten, wird ein Ladeindikator angezeigt
Ergebnisse überprüfen
- Wechselt die Oberfläche zur Predictive view
- Überprüfen Sie das Output-Panel mit den extrahierten Feldern
- Klicken Sie auf jedes Feld, um Folgendes zu sehen:
- Extrahierter Wert
- Confidence (falls vorhanden)
- Hervorgehobener Bereich im Dokumentbild
- ✅ Alle erwarteten Felder sind ausgefüllt
- ✅ Werte stimmen exakt mit dem Dokument überein
- ✅ Keine halluzinierten oder hergeleiteten Daten
- ✅ Korrekte Verarbeitung von mehrzeiligen Feldern
- ✅ Fehlende Felder werden ausgelassen (nicht mit falschen Daten befüllt)
Typische Ergebnismuster
Schritt 10: Verfeinern Sie Ihren Prompt
Häufige Probleme und Lösungen
- Lösung: Präzisere Positionshinweise hinzufügen
- Beispiel: „Nur auf der Vendor-Seite; Kunden-/Käuferadressen ausschließen“
- Lösung: Wortgetreue Extraktion hervorheben
- Beispiel: „Extrahiere das numerische Format exakt wie gedruckt (z. B. ‚12-34-56‘)“
- Lösung: Regeln für strikte Extraktion verschärfen
- Beispiel: „Niemals Werte generieren oder ableiten. Auslassen, wenn nicht vorhanden.“
- Lösung: Escape-Sequenzen spezifizieren
- Beispiel: „Für mehrzeilige Werte
\nfür Zeilenumbrüche verwenden“
- Lösung: Sicherstellen, dass Feldnamen exakt übereinstimmen
- Beispiel: „Verwende
Vendor.Account Numberund nichtAccountNumber“
Iterativer Verbesserungsprozess
- An mehreren Dokumenten testen: Nicht für ein einzelnes Beispiel optimieren
- Muster dokumentieren: Notieren, welche Regeln funktionieren und welche verfeinert werden müssen
- Konkrete Beispiele hinzufügen: Formatbeispiele in Klammern angeben
- Strengegrad verfeinern: Auf Basis von Mustern bei Über- bzw. Unterextraktion anpassen
- Randfälle testen: Dokumente mit fehlenden Feldern und ungewöhnlichen Layouts verwenden
Beispiele für Verfeinerungen
Grundlagen des Extraktionsprozesses
Funktionsweise der Prompt-basierten Extraktion
- Dokumentkonvertierung: Ihr Dokument wird in das ausgewählte Format umgewandelt (Format Annotated Text empfohlen)
- Prompt-Zusammenstellung: Ihre Rolle, das Ausgabeformat, Feldregeln und Regeln für die Strenge werden kombiniert
- API-Aufruf: Der Prompt und das Dokument werden über Ihre Verbindung an das LLM gesendet
- LLM-Verarbeitung: Das LLM liest das Dokument und extrahiert Daten gemäß Ihren Anweisungen
- JSON-Antwort: Das LLM gibt strukturierte Daten im angegebenen JSON-Format zurück
- Feldzuordnung: Vantage ordnet die JSON-Antwort Ihren definierten Ausgabefeldern zu
- Verifizierung: Zeilennummern und Konfidenzwerte (falls vorhanden) unterstützen Sie bei der Überprüfung der Genauigkeit
Tokenverbrauch und Kosten
- Dokumentenlänge: Längere Dokumente verbrauchen mehr Tokens
- Prompt-Komplexität: Detaillierte Prompts erhöhen die Anzahl der Tokens
- Formatwahl: Annotated Text ist in der Regel effizienter als PDF
- Anzahl der Felder: Mehr Felder = längere Prompts
- Verwenden Sie eine präzise, aber klare Sprache in Prompts
- Wiederholen Sie Anweisungen nicht
- Entfernen Sie unnötige Beispiele
- Ziehen Sie eine Gruppierung von Feldern für zusammengehörige Daten in Betracht
Bewährte Verfahren
Prompts formulieren
- ✅ Klare, imperative Anweisungen verwenden („Extract“, „Recognize“, „Omit“)
- ✅ Mehrere Beschriftungsvarianten für jedes Feld angeben
- ✅ Formatbeispiele in Klammern anführen
- ✅ Präzise angeben, was NICHT extrahiert werden soll (Ausschlüsse)
- ✅ Ihre Regeln zur einfachen Referenz nummerieren
- ✅ Durchgängig eine konsistente Terminologie verwenden
- ❌ Vage Anweisungen verwenden („get the name“)
- ❌ Voraussetzen, dass das LLM domänenspezifische Konventionen kennt
- ❌ Übermäßig lange, komplexe Sätze schreiben
- ❌ Sich in verschiedenen Abschnitten widersprechen
- ❌ Auf Vorgaben zur Strenge verzichten
Felddefinitionen
- Mit Erkennungsmustern (alternativen Bezeichnungen) beginnen
- Das exakt beizubehaltende Format angeben
- Positionierungshinweise bereitstellen (typische Platzierung)
- Datenverantwortung definieren (Vendor vs. Kunde)
- Umgang mit mehrzeiligen Werten beschreiben
- Verwandte Felder referenzieren, um Verwechslungen zu vermeiden
Teststrategie
- Mit einfachen Dokumenten beginnen: Zuerst die grundlegende Extraktion testen
- Auf Variationen ausweiten: Unterschiedliche Layouts und Formate ausprobieren
- Randfälle testen: Fehlende Felder, ungewöhnliche Positionen, mehrere Treffer
- Fehler dokumentieren: Beispiele aufbewahren, bei denen die Extraktion fehlschlägt
- Systematisch iterieren: Immer nur eine Sache auf einmal ändern
Leistungsoptimierung
- Halten Sie Prompts prägnant
- Verwenden Sie das Annotated-Text-Format
- Minimieren Sie die Anzahl der Felder pro Aktivität
- Ziehen Sie in Betracht, komplexe Dokumente aufzuteilen
- Stellen Sie umfassende Feldregeln bereit
- Fügen Sie Formatbeispiele hinzu
- Legen Sie strenge Striktheitsregeln fest
- Testen Sie mit vielfältigen Dokumentbeispielen
- Optimieren Sie die Promptlänge
- Verwenden Sie effiziente Dokumentformate
- Cachen Sie Ergebnisse, wenn angemessen
- Überwachen Sie den Tokenverbrauch über das Dashboard des LLM-Anbieters
Fehlerbehebung
Extraktionsprobleme
- Prüfen, ob die Schreibweise des Feldnamens exakt übereinstimmt
- Überprüfen, ob sich die Daten im ausgewählten Dokumentformat befinden
- Mehr Label-Varianten zu den Erkennungsmustern hinzufügen
- Striktheit vorübergehend reduzieren, um zu sehen, ob das LLM sie findet
- Prüfen, ob die Dokumentqualität die OCR-/Text-Extraktion beeinflusst
- Spezifikationen für den Vendor präzisieren
- Explizite Ausschlüsse für Kunden-/Käuferdaten hinzufügen
- Positionshinweise angeben (z. B. „oben im Dokument“, „Ausstellerbereich“)
- Beispiele für korrekte und inkorrekte Extraktion hinzufügen
- Escape-Sequenz-Format ausdrücklich angeben (
\n) - Beispiele für korrekte mehrzeilige Ausgabe bereitstellen
- Überprüfen, ob das Dokumentformat Zeilenumbrüche beibehält
- Anweisung hinzufügen: „Ursprüngliche Zeilenumbrüche mit
\nbeibehalten“
- „Wortgetreu“ und „genau wie gedruckt“ betonen
- Strikte Regel hinzufügen: „Keine Normalisierung oder Interpretation“
- Konkrete Beispiele bereitstellen, die die Beibehaltung der Formatierung zeigen
- Negative Beispiele einschließen: „Nicht ‚12-34-56‘, sondern ‚12 34 56‘ beibehalten“
Performanceprobleme
- Bei Verwendung von PDF auf das Format Annotated Text umstellen
- Prompt vereinfachen, ohne kritische Anweisungen zu verlieren
- Dokumentauflösung reduzieren, wenn Bilder sehr groß sind
- Status und Rate Limits des LLM-Providers prüfen
- Für einfache Dokumente ein schnelleres Modell in Betracht ziehen
- Striktheitsregeln verschärfen
- Anweisungen spezifischer und eindeutiger formulieren
- Mehr Formatbeispiele hinzufügen
- Promptkomplexität reduzieren, die zu Interpretationen führen kann
- Mit höheren Temperatureinstellungen testen (falls in der Anbindung verfügbar)
- Promptlänge optimieren
- Annotated Text anstelle von PDF verwenden
- Dokumente in Batches außerhalb der Spitzenzeiten verarbeiten
- Für einfache Dokumente kleinere/günstigere Modelle in Betracht ziehen
- Budgetwarnungen im Dashboard des LLM-Providers überwachen und einrichten
Erweiterte Techniken
Bedingte Extraktion
Unterstützung für mehrere Sprachen
Validierungsregeln
Feldbeziehungen
Einschränkungen und Hinweise
Aktuelle Funktionen
- ✅ Feldextraktion auf Header-Ebene
- ✅ Ein- und mehrzeilige Werte
- ✅ Mehrere Felder pro Dokument
- ✅ Bedingte Extraktionslogik
- ✅ Mehrsprachige Dokumente
- ✅ Variable Dokumentenlayouts
- ⚠️ Tabellenextraktion (variiert je nach Implementierung)
- ⚠️ Verschachtelte komplexe Strukturen
- ⚠️ Sehr große Dokumente (Token-Limits)
- ⚠️ Verarbeitung in Echtzeit (API-Latenz)
- ⚠️ Deterministische Ergebnisse mit Garantie
Wann Sie promptbasierte Extraktion verwenden sollten
- Dokumente mit variablen Layouts
- Teilstrukturierte Dokumente
- Schnelles Prototyping und Testen
- Kleines bis mittleres Dokumentenaufkommen
- Wenn keine Trainingsdaten verfügbar sind
- Mehrsprachige Dokumentverarbeitung
- Produktionsumgebungen mit hohem Volumen (traditionelles ML kann schneller sein)
- Stark strukturierte Formulare (vorlagenbasierte Extraktion)
- Kostenempfindliche Anwendungen (traditionelle Methoden können günstiger sein)
- Latenzkritische Anwendungen (LLM-APIs verursachen Netzwerklatenz)
- Anforderungen an Offline-Verarbeitung (für traditionelle Methoden ist keine Internetverbindung erforderlich)
Integration mit Document-Skills
Verwendung der extrahierten Daten
- Validierungsaktivitäten: Wenden Sie Geschäftsregeln auf die extrahierten Werte an
- Skriptaktivitäten: Verarbeiten oder transformieren Sie die extrahierten Daten
- Exportaktivitäten: Exportieren Sie Daten in externe Systeme
- Überprüfungsoberfläche: Manuelle Prüfung der extrahierten Felder
Kombination mit anderen Aktivitäten
Feldzuordnung
"FieldName": "Vendor.Name"→ wird dem AusgabefeldVendor.Namezugeordnet- Die Feldhierarchie bleibt in der Ausgabestruktur erhalten
- Zeilennummern unterstützen die Überprüfung und Fehlerbehebung
Zusammenfassung
- ✅ Eine promptbasierte Extraktionsaktivität erstellt
- ✅ Eine LLM-Verbindung konfiguriert
- ✅ Einen umfassenden Extraktionsprompt mit Rolle, Format und Regeln verfasst
- ✅ Das optimale Dokumentformat (Annotated Text) ausgewählt
- ✅ Striktheitsrichtlinien für die Datenqualität angewendet
- ✅ Die Extraktion getestet und die Ergebnisse überprüft
- ✅ Best Practices für Prompt-Engineering gelernt
- Promptbasierte Extraktion verwendet Anweisungen in natürlicher Sprache
- Das Format Annotated Text liefert die besten Ergebnisse
- Klare, spezifische Prompts führen zu konsistenter Extraktion
- Striktheitsrichtlinien verhindern Halluzinationen und sichern die Datenqualität
- Iteratives Testen und Verfeinern verbessert die Genauigkeit
Nächste Schritte
- Mit unterschiedlichen Dokumenten testen: Überprüfen Sie die Verarbeitung bei verschiedenen Layouts und Varianten.
- Prompts verfeinern: Verbessern Sie diese kontinuierlich auf Basis der erzielten Ergebnisse.
- Kosten überwachen: Verfolgen Sie die Token-Nutzung im Dashboard Ihres LLM-Anbieters.
- Performance optimieren: Stimmen Sie die Prompts auf Geschwindigkeit und Genauigkeit ab.
- Tabellenextraktion erkunden: Experimentieren Sie mit der Extraktion von Positionen (wiederholte Gruppe) (falls unterstützt).
- In Workflows integrieren: Kombinieren Sie dies mit anderen Aktivitäten, um eine vollständige Verarbeitung zu erreichen.
Zusätzliche Ressourcen
- Dokumentation zu ABBYY Vantage Advanced Designer: https://docs.abbyy.com
- Anleitung zur Einrichtung von LLM-Verbindungen: LLM-Verbindungen konfigurieren
- Best Practices für Prompt Engineering: Siehe die Dokumentation Ihres LLM-Anbieters
- Support: Kontaktieren Sie den ABBYY-Support für technische Unterstützung