Descripción general
- Crear una actividad de extracción basada en prompts
- Configurar una conexión con un LLM
- Redactar prompts de extracción eficaces
- Definir el formato y la estructura de salida
- Definir el nivel de rigor y las Reglas de Validación
- Probar y perfeccionar su extracción
- Extracción de información del Proveedor a partir de facturas
- Captura de datos de documentos a nivel de encabezado
- Procesamiento de documentos semiestructurados
- Documentos con diseños variables
Requisitos previos
- Acceso a ABBYY Vantage Advanced Designer
- Una conexión LLM configurada (consulta Cómo configurar conexiones LLM)
- Una Skill de documento con documentos de ejemplo cargados
- Conocimientos básicos de la estructura JSON
- Definiciones de campos para los datos que deseas extraer
Comprender la extracción basada en prompts
¿Qué es la extracción basada en prompts?
- Rol: Cómo debe actuar el LLM (por ejemplo, “modelo de extracción de datos”)
- Instrucciones: Cómo extraer y formatear los datos
- Estructura de salida: El formato JSON exacto de los resultados
- Reglas: Directrices para manejar datos ambiguos o ausentes
Beneficios
- No se requieren datos de entrenamiento: Funciona únicamente con ingeniería de prompts
- Flexible: Es fácil agregar o modificar campos
- Maneja variaciones: Los LLM pueden comprender diferentes formatos de documentos
- Configuración rápida: Más rápido que entrenar modelos tradicionales de aprendizaje automático (ML)
- Lenguaje natural: Escribe las instrucciones en inglés sencillo
Limitaciones
- Coste: Cada extracción utiliza llamadas a la API de LLM
- Velocidad: Más lenta que la extracción tradicional para documentos simples
- Consistencia: Los resultados pueden variar ligeramente entre distintas ejecuciones
- Límites de contexto: Los documentos muy largos pueden requerir un tratamiento especial
Paso 1: Agregar una actividad basada en prompts
- Abra su Skill de documento en ABBYY Vantage Advanced Designer
- En el panel izquierdo, localice EXTRACT FROM TEXT (NLP)
- Busque y haga clic en Prompt-based
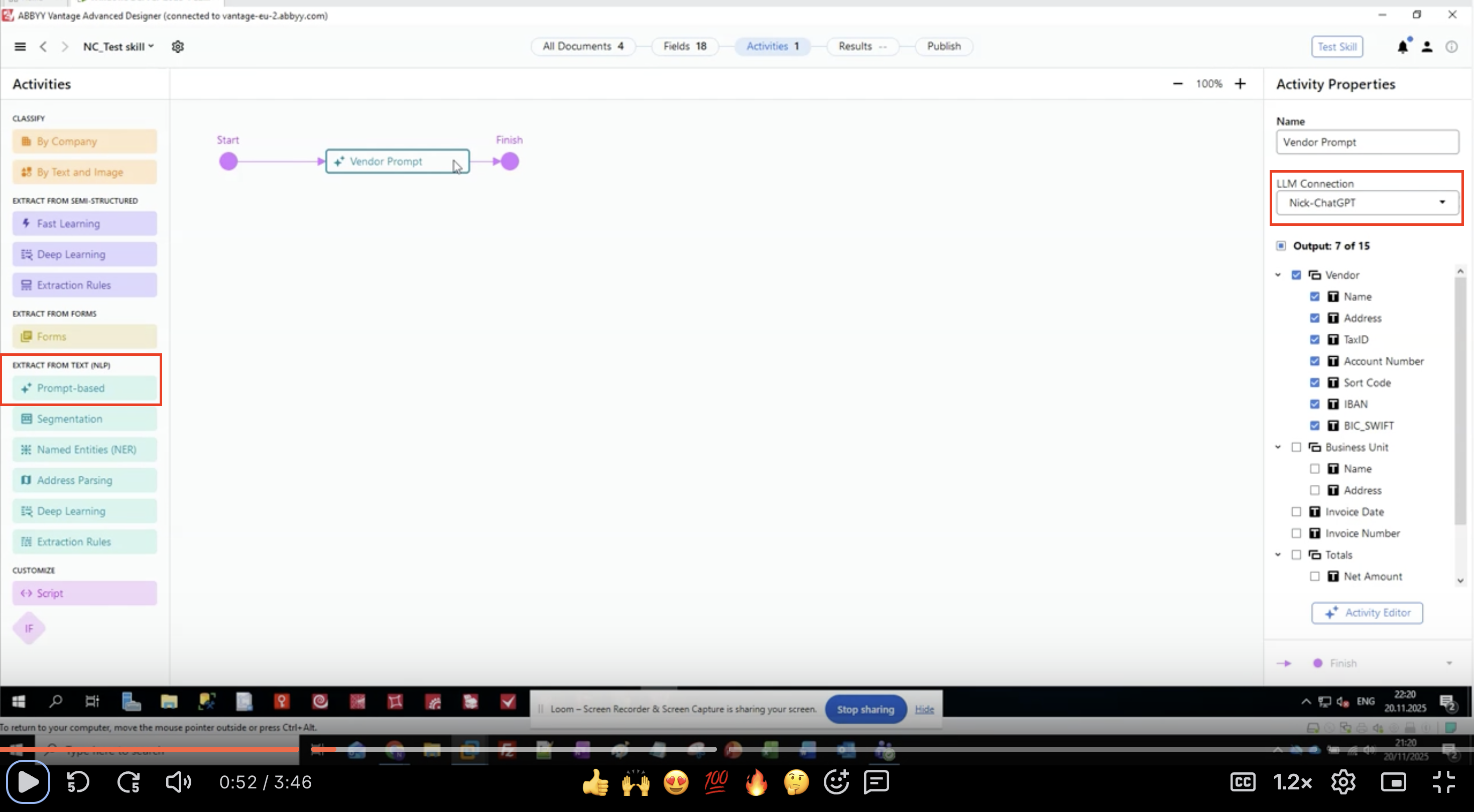
- La actividad aparecerá en el lienzo de su flujo de trabajo
- Conéctela entre las actividades de entrada y salida
Paso 2: Configurar la conexión LLM
- Seleccione la actividad basada en prompt en su flujo de trabajo
- En el panel Activity Properties a la derecha, localice LLM Connection
- Haga clic en el menú desplegable
-
Seleccione de la lista la conexión LLM que haya configurado
- Ejemplo:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- Ejemplo:
- Compruebe que la conexión esté seleccionada
Paso 3: Definir los campos de salida
- En el panel Activity Properties, busque la sección Output
- Verá una lista jerárquica de grupos de campos y campos
- En este ejemplo, extraeremos información del proveedor:
- Proveedor
- Nombre
- Dirección
- TaxID
- Número de cuenta
- Sort Code
- IBAN
- BIC_SWIFT
- Unidad de negocio
- Nombre
- Dirección
- Fecha de la factura
- Número de factura
- Totales
- Monto neto
- Proveedor
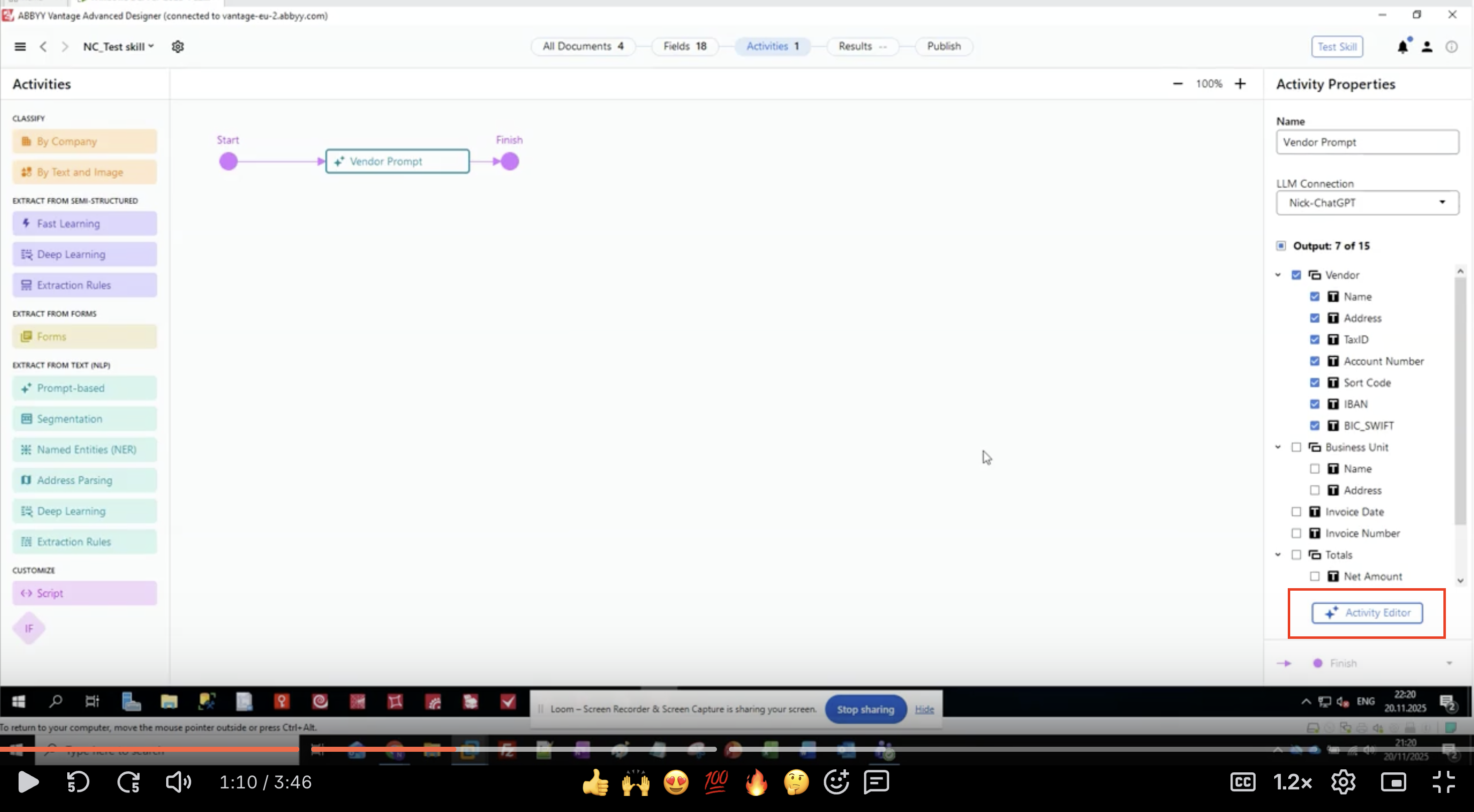
- Haga clic en el botón Activity Editor para empezar a configurar el prompt
Paso 4: Escribir la definición del rol
- En el Activity Editor, verá la interfaz Prompt Text
- Comience con la sección ROLE:
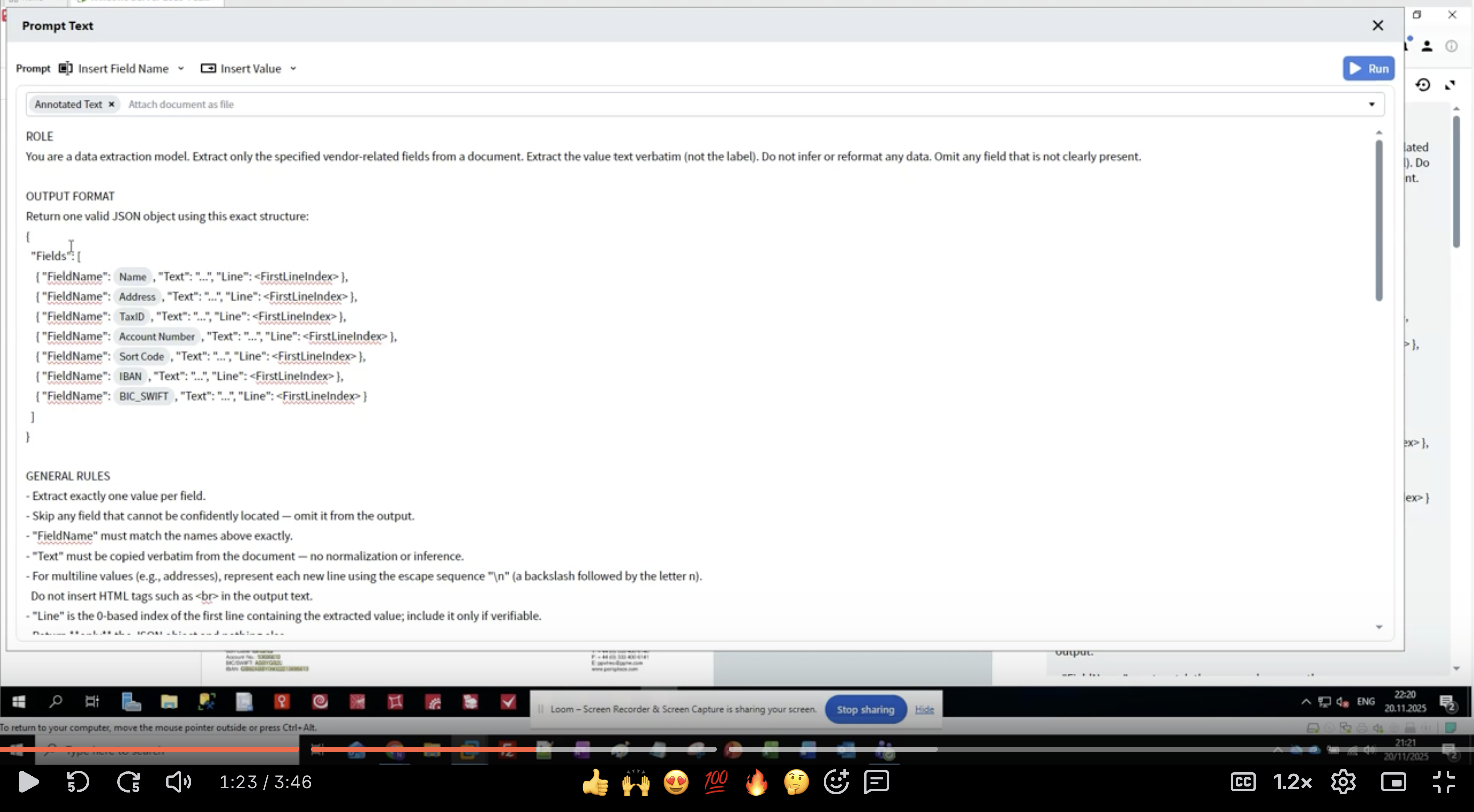
- Sea específico: “data extraction model” indica al LLM cuál es su propósito
- Defina el alcance: “vendor-related fields” limita qué se debe extraer
- Establezca expectativas: “value text verbatim” evita cambiar el formato
- Gestione los datos faltantes: “Omit any field that is not clearly present”
- Mantenga la definición del rol clara y concisa
- Use enunciados imperativos (“Extract”, “Do not infer”)
- Sea explícito sobre lo que NO se debe hacer
- Defina cómo manejar los casos límite
Paso 5: Definir el formato de salida
- Debajo de la sección ROLE, agregue el encabezado OUTPUT FORMAT
- Defina la estructura JSON:
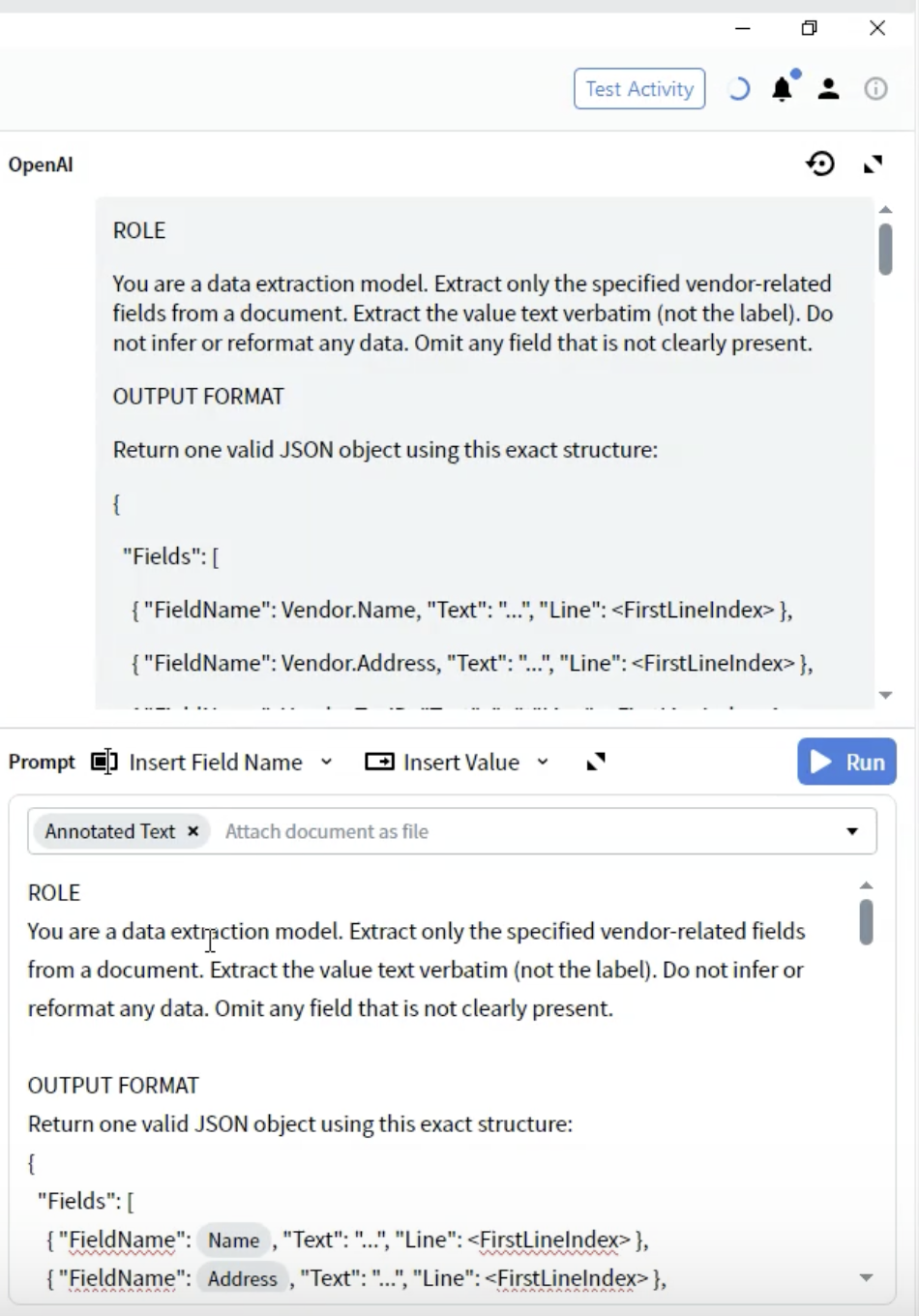
- FieldName: Debe coincidir exactamente con sus definiciones de campos (por ejemplo,
Vendor.Name) - Text: El valor extraído como una cadena
- Line: Índice de línea con base 0 donde aparece el valor en el documento
- Use los nombres de campos exactos de su configuración de Output
- Incluya todos los campos incluso si algunos pueden estar vacíos
- La estructura debe ser JSON válido
- Los números de línea ayudan con la verificación y la resolución de problemas
Paso 6: Añadir reglas de extracción específicas para cada Field
- Patrones de reconocimiento: Enumera etiquetas alternativas para cada campo
- Especificaciones de formato: Describe el formato exacto que se debe extraer
- Indicaciones de ubicación: Dónde se suelen encontrar los datos
- Exclusiones: Qué NO se debe extraer
- Numera tus reglas para mayor claridad
- Proporciona múltiples variaciones de etiquetas
- Especifica la procedencia de los datos (lado del proveedor vs. lado del cliente)
- Incluye ejemplos de formato entre paréntesis
- Sé explícito sobre los campos relacionados (por ejemplo, “Ignora el IBAN — tiene su propio campo”)
Paso 7: Aplicar reglas de STRICTNESS
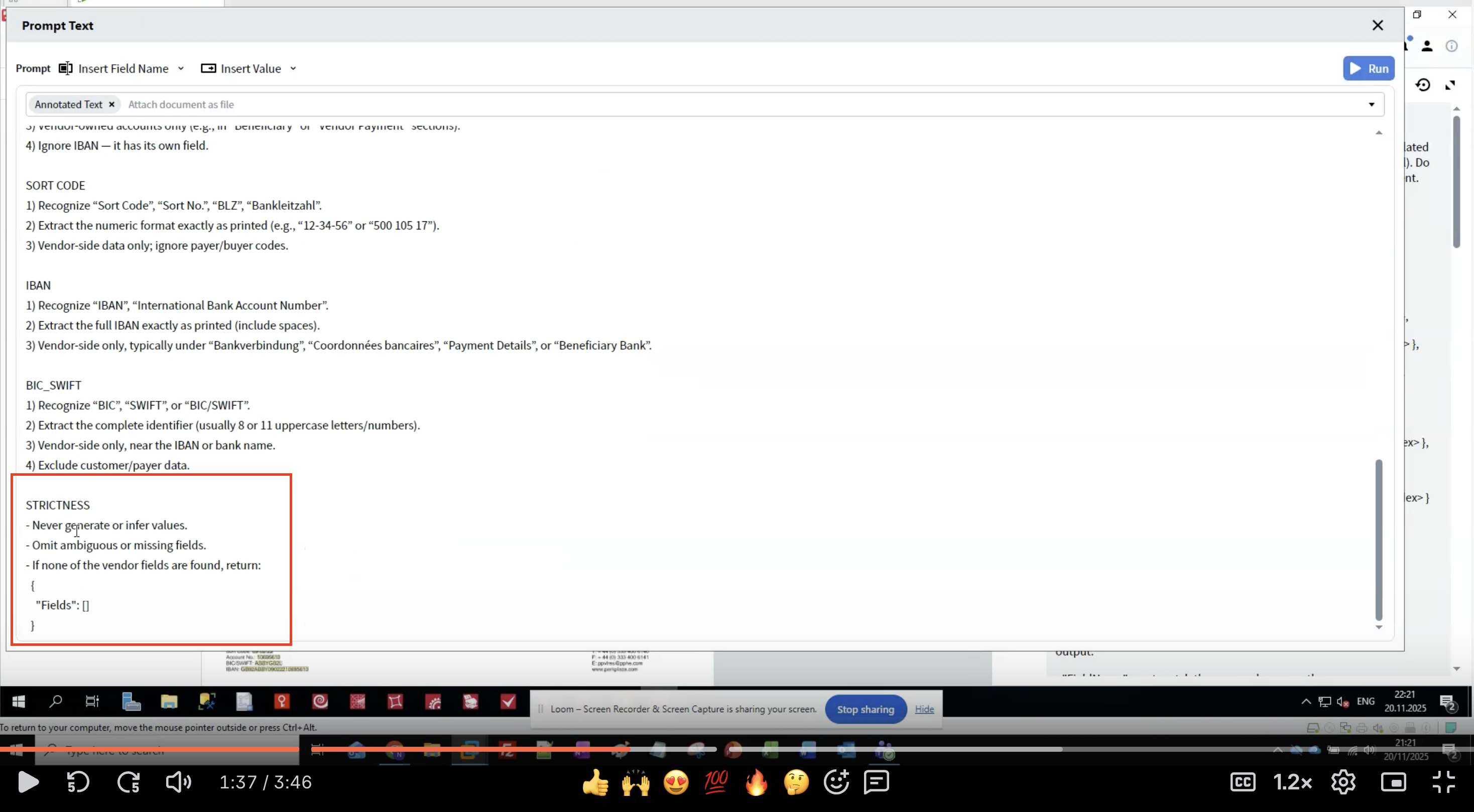
- Evita alucinaciones: los LLM pueden generar datos plausibles pero incorrectos
- Garantiza la coherencia: las reglas claras reducen la variabilidad entre ejecuciones
- Gestiona datos faltantes: define qué hacer cuando no se encuentran campos
- Mantiene la integridad de los datos: la extracción literal preserva el formato original
- Nunca generar datos que no estén en el documento
- Omitir extracciones dudosas en lugar de adivinar
- Devolver una estructura vacía si no se encuentran campos
- Hacer coincidir exactamente los nombres de los campos
- Conservar el formato original del texto
Paso 8: Seleccionar el formato del documento
- En el Activity Editor, localice la lista desplegable Prompt
- Verá opciones sobre cómo se proporciona el documento al LLM
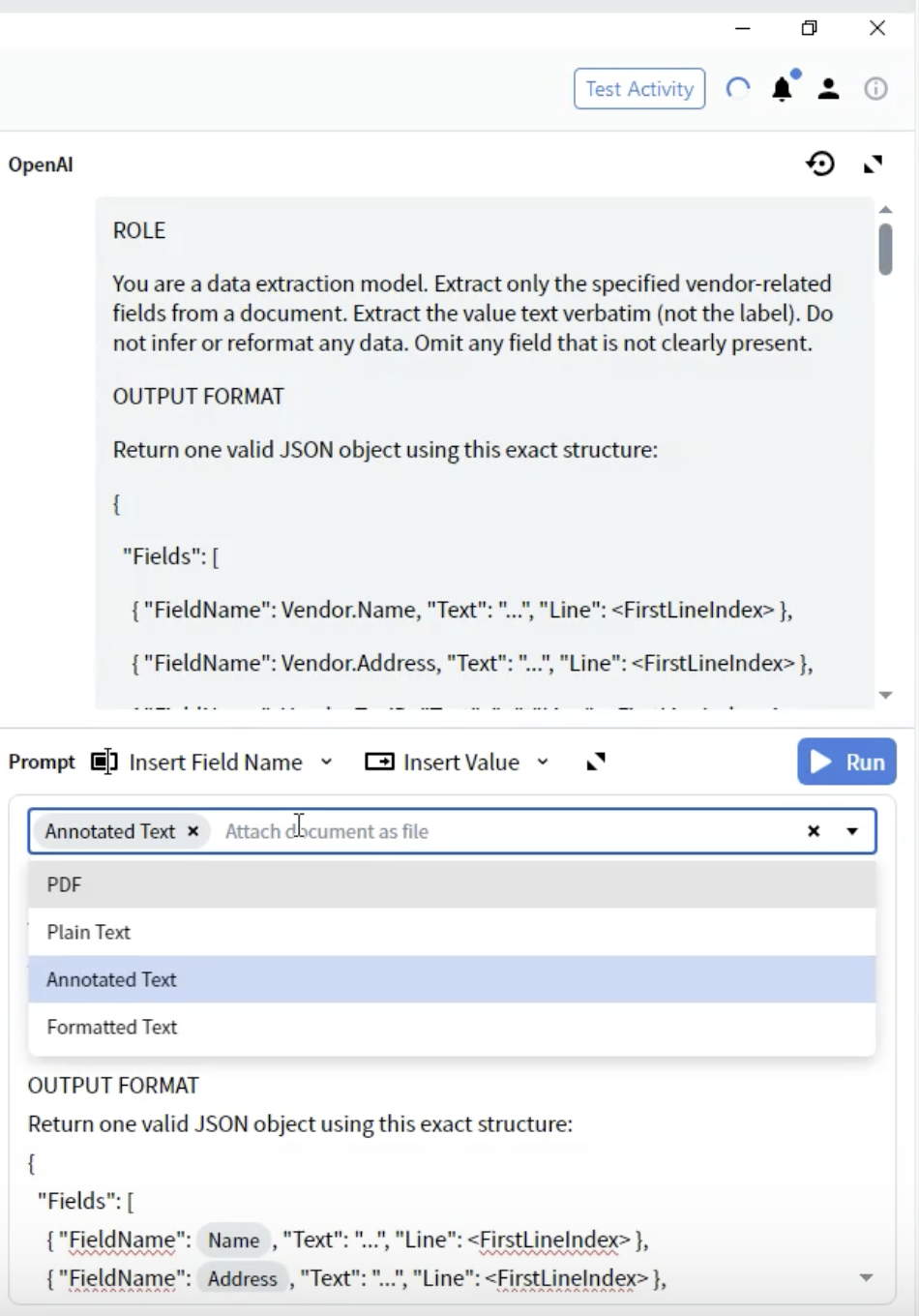
-
PDF: Archivo PDF original
- Úselo para: Documentos donde el diseño es fundamental
- Consideraciones: Tamaño de archivo mayor; algunos LLM tienen compatibilidad limitada con PDF
-
Plain Text: Extracción de texto sin formato
- Úselo para: Documentos sencillos solo de texto
- Consideraciones: Se pierde toda la información de formato y diseño
-
Annotated Text ⭐ (Recomendado)
- Úselo para: La mayoría de los tipos de documentos
- Consideraciones: Conserva la estructura aun siendo basado en texto
- Ventajas: Mejor equilibrio entre estructura y rendimiento
-
Formatted Text: Texto con formato básico conservado
- Úselo para: Documentos donde parte del formato es importante
- Consideraciones: Punto intermedio entre Plain Text y Annotated Text
- Seleccione Annotated Text para obtener los mejores resultados
Paso 9: Pruebe su extracción
Ejecutar la actividad
- Cierre el Activity Editor
- Vaya a la pestaña All Documents
- Seleccione un documento de prueba
- Haga clic en el botón Test Activity o Run
- Espere a que el LLM procese el documento
- Tiempo de procesamiento: normalmente entre 5 y 30 segundos, según la complejidad del documento
- Verá un indicador de carga mientras espera la respuesta de la API
Revisar los resultados
- La interfaz cambia a la vista predictiva
- Revise el panel de Output que muestra los campos extraídos
- Haga clic en cada campo para ver:
- Valor extraído
- Nivel de confianza (si se proporciona)
- Región resaltada en la imagen del documento
- ✅ Todos los campos esperados están completos
- ✅ Los valores coinciden exactamente con el documento
- ✅ No hay datos inventados ni inferidos
- ✅ Manejo correcto de campos de varias líneas
- ✅ Los campos faltantes se omiten (no se rellenan con datos incorrectos)
Patrones de resultados habituales
Paso 10: Refine su prompt
Problemas comunes y soluciones
- Solución: Añadir indicaciones de ubicación más específicas
- Ejemplo: “Solo información del Proveedor; excluir direcciones del cliente/comprador”
- Solución: Enfatizar la extracción literal
- Ejemplo: “Extrae el formato numérico exactamente como está impreso (p. ej., ‘12-34-56’)”
- Solución: Hacer más estrictas las reglas
- Ejemplo: “Nunca generes ni infieras valores. Omite si no está presente.”
- Solución: Especificar secuencias de escape
- Ejemplo: “Para valores multilínea, usa
\npara los saltos de línea”
- Solución: Verificar que los nombres de campo coincidan exactamente
- Ejemplo: Usa
Vendor.Account Numbery noAccountNumber
Proceso de mejora iterativo
- Prueba con varios documentos: No lo optimices para un único ejemplo
- Documenta los patrones: Registra qué reglas funcionan y cuáles necesitan ajustes
- Añade ejemplos concretos: Incluye ejemplos de formatos entre paréntesis
- Ajusta el nivel de rigor: Modifícalo según los patrones de sobreextracción o subextracción
- Prueba casos límite: Usa documentos con campos faltantes y diseños inusuales
Ejemplos de mejoras
Descripción del proceso de extracción
Cómo funciona la extracción basada en prompts
- Conversión del documento: Tu documento se convierte al formato seleccionado (se recomienda Annotated Text)
- Ensamblado del prompt: Se combinan tu rol, el formato de salida, las reglas de campo y las reglas de estrictitud
- Llamada a la API: El prompt y el documento se envían al LLM a través de tu conexión
- Procesamiento del LLM: El LLM lee el documento y extrae datos de acuerdo con tus instrucciones
- Respuesta JSON: El LLM devuelve datos estructurados en el formato JSON especificado
- Asignación de campos: Vantage asigna la respuesta JSON a tus campos de salida definidos
- Verificación: Los números de línea y los niveles de confianza (si se proporcionan) ayudan a verificar la precisión
Uso de tokens y costos
- Longitud del documento: Los documentos más largos consumen más tokens
- Complejidad del prompt: Los prompts detallados incrementan la cantidad de tokens
- Elección de formato: Annotated Text suele ser más eficiente que PDF
- Cantidad de campos: Más campos = prompts más largos
- Usa un lenguaje conciso pero claro en los prompts
- No dupliques instrucciones
- Elimina ejemplos innecesarios
- Considera agrupar campos para datos relacionados
Mejores prácticas
Redacción de prompts
- ✅ Usa enunciados claros e imperativos (“Extract”, “Recognize”, “Omit”)
- ✅ Proporciona varias alternativas de etiqueta para cada campo
- ✅ Incluye ejemplos de formato entre paréntesis
- ✅ Especifica qué NO se debe extraer (exclusiones)
- ✅ Numera tus reglas para que sea fácil consultarlas
- ✅ Usa una terminología coherente en todo el documento
- ❌ No uses instrucciones vagas (“get the name”)
- ❌ No supongas que el LLM conoce convenciones específicas del dominio
- ❌ No escribas oraciones excesivamente largas y complejas
- ❌ No te contradigas en diferentes secciones
- ❌ No omitas las reglas de rigor
Definiciones de campos
- Comience con patrones de reconocimiento (etiquetas alternativas)
- Especifique el formato exacto que se debe conservar
- Proporcione indicaciones de ubicación (ubicación habitual)
- Defina la propiedad de los datos (proveedor vs. cliente)
- Incluya el tratamiento de valores en varias líneas
- Haga referencia a campos relacionados para evitar confusiones
Estrategia de pruebas
- Comience con documentos simples: Pruebe primero la extracción básica
- Amplíe a más variaciones: Pruebe diferentes diseños y formatos
- Pruebe casos límite: Campos faltantes, posiciones inusuales, múltiples coincidencias
- Documente los fallos: Guarde ejemplos de los casos en que falla la extracción
- Itere de forma sistemática: Cambie una sola cosa a la vez
Optimización del rendimiento
- Mantén los prompts concisos
- Usa el formato Annotated Text
- Minimiza el número de campos por actividad
- Considera dividir los documentos complejos
- Proporciona reglas de campos completas
- Incluye ejemplos de formato
- Agrega reglas de validación estrictas
- Prueba con muestras de documentos diversas
- Optimiza la longitud del prompt
- Usa formatos de documento eficientes
- Guarda en caché los resultados cuando sea apropiado
- Supervisa el uso de tokens mediante el panel de control del proveedor de LLM
Solución de problemas
Problemas de extracción
- Compruebe que la ortografía del nombre del campo coincida exactamente
- Verifique que los datos estén en el formato de documento seleccionado
- Agregue más variaciones de etiquetas a los patrones de reconocimiento
- Reduzca el nivel de rigor temporalmente para ver si el LLM los encuentra
- Compruebe si la calidad del documento afecta a la extracción de texto mediante OCR
- Refuerce las especificaciones del lado del proveedor
- Agregue exclusiones explícitas para datos de cliente/comprador
- Proporcione indicios de ubicación (p. ej., “parte superior del documento”, “sección del emisor”)
- Incluya ejemplos de extracción correcta frente a incorrecta
- Especifique explícitamente el formato de la secuencia de escape (
\n) - Proporcione ejemplos de salida multilínea correcta
- Verifique que el formato del documento preserve los saltos de línea
- Agregue la instrucción: “Conserve los saltos de línea originales usando
\n”
- Haga hincapié en “literal” y “exactamente como está impreso”
- Agregue una regla de rigor: “Sin normalización ni inferencia”
- Proporcione ejemplos específicos que muestren la preservación del formato
- Incluya ejemplos negativos: “No ‘12-34-56’, conservar como ‘12 34 56‘“
Problemas de rendimiento
- Cambia al formato Annotated Text si trabajas con PDF
- Simplifica el prompt sin perder instrucciones críticas
- Reduce la resolución del documento si las imágenes son muy grandes
- Verifica el estado del servicio del proveedor de LLM y los límites de tasa de uso
- Considera usar un modelo más rápido para documentos sencillos
- Refuerza las reglas de rigurosidad
- Haz las instrucciones más específicas e inequívocas
- Añade más ejemplos de formato
- Reduce la complejidad del prompt que pueda dar lugar a interpretaciones
- Prueba con valores de temperatura más altos (si están disponibles en la conexión)
- Optimiza la longitud del prompt
- Usa Annotated Text en lugar de PDF
- Procesa documentos en lotes durante periodos de baja demanda
- Considera usar modelos más pequeños o más económicos para documentos sencillos
- Supervisa y configura alertas de presupuesto en el panel del proveedor de LLM
Técnicas avanzadas
Extracción condicional
Compatibilidad multilingüe
Reglas de Validación
Relaciones entre campos
Limitaciones y aspectos a considerar
Capacidades actuales
- ✅ Extracción de campos a nivel de encabezado
- ✅ Valores de una o varias líneas
- ✅ Múltiples campos por documento
- ✅ Lógica de extracción condicional
- ✅ Documentos multilingües
- ✅ Diseños de documentos variables
- ⚠️ Extracción de tablas (varía según la implementación)
- ⚠️ Estructuras complejas anidadas
- ⚠️ Documentos muy grandes (límites de tokens)
- ⚠️ Procesamiento en tiempo real (latencia de la API)
- ⚠️ Garantía de resultados deterministas
Cuándo utilizar la extracción basada en prompts
- Documentos con diseños variables
- Documentos semiestructurados
- Prototipado y pruebas rápidas
- Volúmenes de documentos de pequeños a medianos
- Cuando no se dispone de datos de entrenamiento
- Procesamiento de documentos en varios idiomas
- Producción de alto volumen (el ML tradicional puede ser más rápido)
- Formularios altamente estructurados (extracción basada en plantillas)
- Aplicaciones sensibles al costo (los métodos tradicionales pueden ser más económicos)
- Aplicaciones con requisitos estrictos de latencia (las API de LLM tienen latencia de red)
- Requisitos de procesamiento sin conexión (no se necesita internet con métodos tradicionales)
Integración con Skills de documento
Uso de los datos extraídos
- Actividades de validación: Aplicar reglas de negocio a los valores extraídos
- Actividades de script: Procesar o transformar los datos extraídos
- Actividades de exportación: Enviar datos a sistemas externos
- Interfaz de revisión: Verificación manual de los campos extraídos
Uso en combinación con otras actividades
Asignación de campos
"FieldName": "Vendor.Name"→ se asigna al campo de salidaVendor.Name- La jerarquía de campos se conserva en la estructura de salida
- Los números de línea ayudan con la verificación y la resolución de problemas
Resumen
- ✅ Creado una actividad de extracción basada en prompts
- ✅ Configurado una conexión con un LLM
- ✅ Redactado un prompt de extracción completo con rol, formato y reglas
- ✅ Seleccionado el formato de documento óptimo (Annotated Text)
- ✅ Aplicado reglas de estrictitud para la calidad de los datos
- ✅ Probado la extracción y revisado los resultados
- ✅ Aprendido buenas prácticas de ingeniería de prompts
- La extracción basada en prompts utiliza instrucciones en lenguaje natural
- El formato Annotated Text proporciona los mejores resultados
- Prompts claros y específicos proporcionan una extracción coherente
- Las reglas de estrictitud evitan alucinaciones y mantienen la calidad de los datos
- Las pruebas iterativas y el perfeccionamiento mejoran la precisión
Próximos pasos
- Pruebe con documentos diversos: Valide con distintos diseños y variaciones
- Refine sus prompts: Mejórelos continuamente en función de los resultados
- Supervise los costos: Haga un seguimiento del uso de tokens en el panel de control de su proveedor de LLM
- Optimice el rendimiento: Ajuste finamente los prompts para mejorar la velocidad y la precisión
- Explore la extracción de tablas: Experimente con la extracción de Partidas (si está disponible)
- Integre con flujos de trabajo: Combínelo con otras actividades para lograr un procesamiento completo
Recursos adicionales
- Documentación de ABBYY Vantage Advanced Designer: https://docs.abbyy.com
- Guía de configuración de conexiones LLM: Cómo configurar conexiones LLM
- Mejores prácticas de ingeniería de prompts: Consulte la documentación de su proveedor de LLM
- Soporte: Póngase en contacto con el soporte de ABBYY para obtener asistencia técnica
Preguntas frecuentes
R: La extracción basada en prompts utiliza instrucciones en lenguaje natural para LLM sin necesidad de datos de entrenamiento. Los métodos tradicionales requieren ejemplos de entrenamiento, pero son más rápidos y rentables a gran escala. P: ¿Puedo extraer tablas con actividades basadas en prompts?
R: La extracción a nivel de encabezado está plenamente soportada. Las capacidades de extracción de tablas pueden variar y requerir estructuras de prompt específicas. P: ¿Por qué usar Annotated Text en lugar de PDF?
R: Annotated Text ofrece el mejor equilibrio entre conservación de la estructura y eficiencia de procesamiento. Las pruebas han demostrado que es la opción más fiable. P: ¿Cómo reduzco los costes de la API?
R: Optimice la longitud del prompt, use el formato Annotated Text, procese de forma eficiente y supervise el uso de tokens mediante el panel de control de su proveedor de LLM. P: ¿Qué ocurre si falla mi conexión de LLM?
R: Compruebe el estado de la conexión en Configuration → Connections. Pruebe la conexión, verifique las credenciales y asegúrese de que no se haya superado su cuota de API. P: ¿Puedo usar múltiples conexiones de LLM en una sola Habilidad?
R: Sí, diferentes actividades pueden usar conexiones distintas. Esto le permite usar distintos modelos para diferentes tareas de extracción. P: ¿Cómo gestiono documentos en varios idiomas?
R: Añada variaciones de etiquetas en varios idiomas a sus reglas de campo. Los LLM generalmente gestionan bien el contenido multilingüe. P: ¿Cuál es el tamaño máximo de documento?
R: Depende de los límites de tokens de su proveedor de LLM. Es posible que los documentos muy extensos deban dividirse o procesarse por secciones.