概要
- プロンプトベース抽出アクティビティを作成する
- LLM 接続を構成する
- 効果的な抽出プロンプトを作成する
- 出力形式と構造を定義する
- 厳格さとバリデーションルールを適用する
- 抽出結果をテストし、改善する
- 請求書のベンダー情報の抽出
- ヘッダーレベルのドキュメントデータの取得
- 半構造化ドキュメントの処理
- レイアウトが可変なドキュメントの処理
前提条件
- ABBYY Vantage Advanced Designer へのアクセス権
- 構成済みの LLM 接続(LLM 接続の構成方法 を参照)
- サンプルドキュメントが読み込まれている Document Skill
- JSON 構造に関する 基本的な理解
- 抽出したいデータの field の定義
プロンプトベースの抽出について理解する
プロンプトベース抽出とは?
- Role: LLM にどのような役割を担わせるか(例: 「data extraction model」)
- Instructions: データをどのように抽出し、どのような形式に整形するか
- Output Structure: 結果の厳密な JSON フォーマット
- Rules: あいまいなデータや欠損データをどのように扱うかについてのガイドライン
メリット
- 学習データ不要: プロンプトエンジニアリングだけで利用可能
- 柔軟: field の追加や変更が容易
- バリエーションに対応: LLM はさまざまな文書形式を理解できる
- セットアップが速い: 従来型の機械学習モデルの学習よりも短時間でセットアップ可能
- 自然言語: 平易な英語で指示を書ける
制限事項
- コスト: 各抽出処理で LLM API 呼び出しが発生します
- 速度: 単純な文書に対する従来の抽出よりも遅くなります
- 一貫性: 実行のたびに結果がわずかに異なる場合があります
- コンテキスト制限: 非常に長い文書では特別な対応が必要になる場合があります
ステップ 1: プロンプトベースのアクティビティを追加する
- ABBYY Vantage Advanced Designer で対象の Document Skill を開きます
- 左側のパネルで EXTRACT FROM TEXT (NLP) を見つけます
- Prompt-based をクリックします
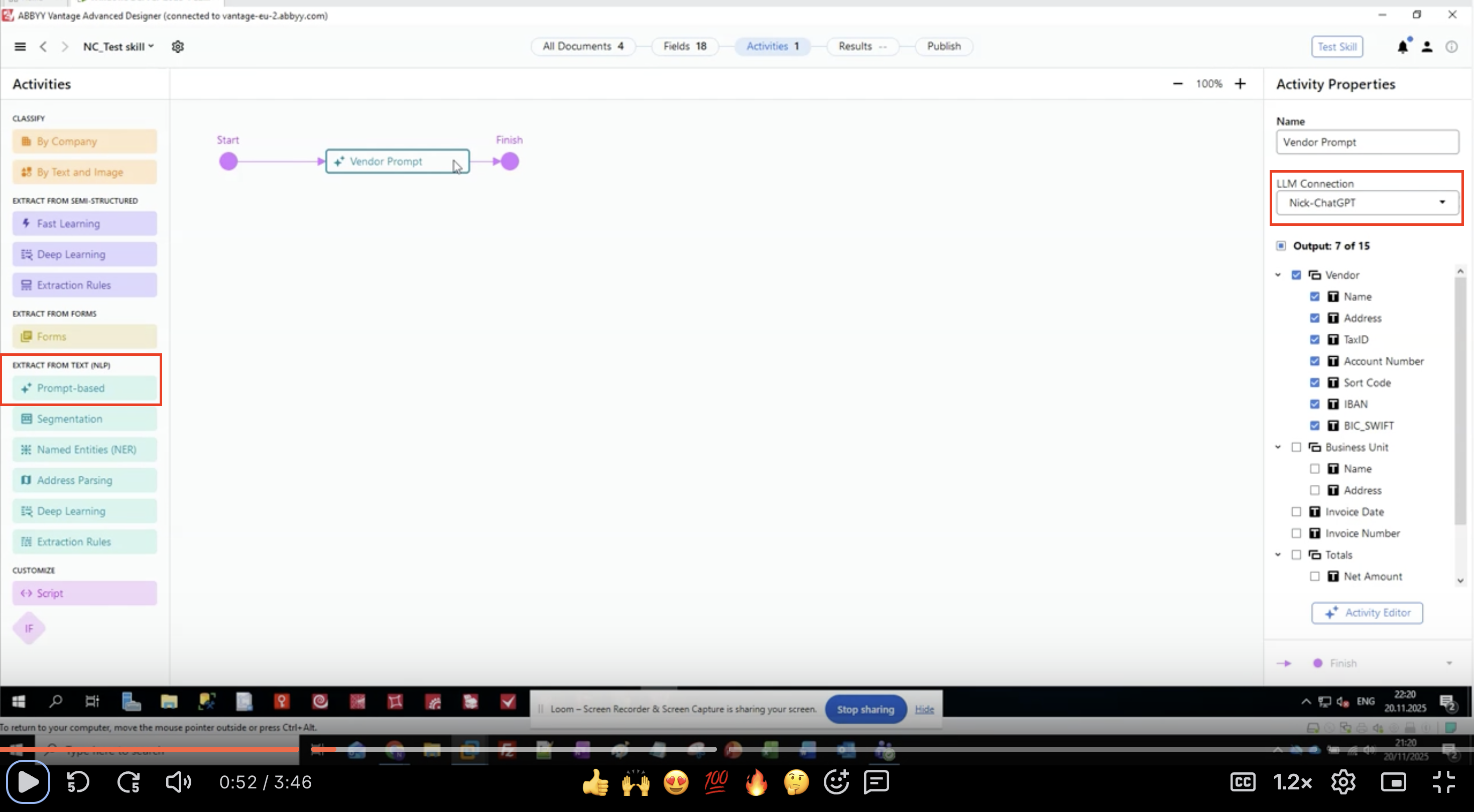
- ワークフローキャンバス上にアクティビティが表示されます
- 入力アクティビティと出力アクティビティの間に接続します
ステップ 2: LLM 接続を構成する
- ワークフロー内のプロンプトベースのアクティビティを選択します
- 右側にある Activity Properties パネルで LLM Connection を探します
- ドロップダウンメニューをクリックします
-
リストから構成済みの LLM 接続を選択します
- 例:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- 例:
- 接続が選択されていることを確認します
ステップ 3: 出力fieldを定義する
- Activity Properties パネルで、Output セクションを見つけます
- fieldグループとfieldの階層リストが表示されます
- この例では、ベンダー情報を抽出します:
- ベンダー
- Name
- Address
- TaxID
- アカウント番号
- Sort Code
- IBAN(国際銀行口座番号)
- BIC_SWIFT
- Business Unit
- Name
- Address
- 請求日
- 請求書番号
- Totals
- Net Amount
- ベンダー
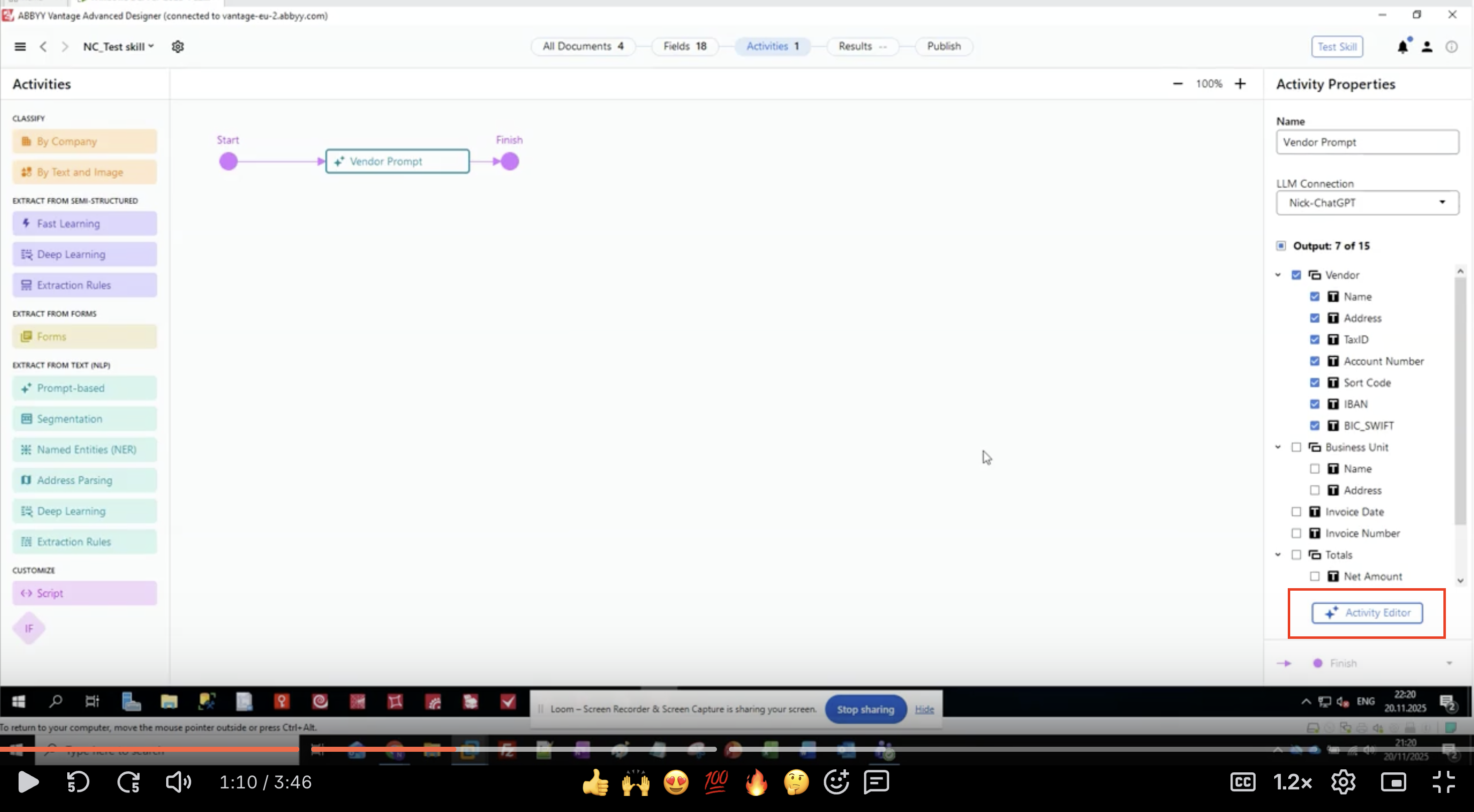
- Activity Editor ボタンをクリックして、プロンプトの設定を開始します
ステップ 4: ロール定義を記述する
- Activity Editor で Prompt Text インターフェースが表示されます
- ROLE セクションから開始します。
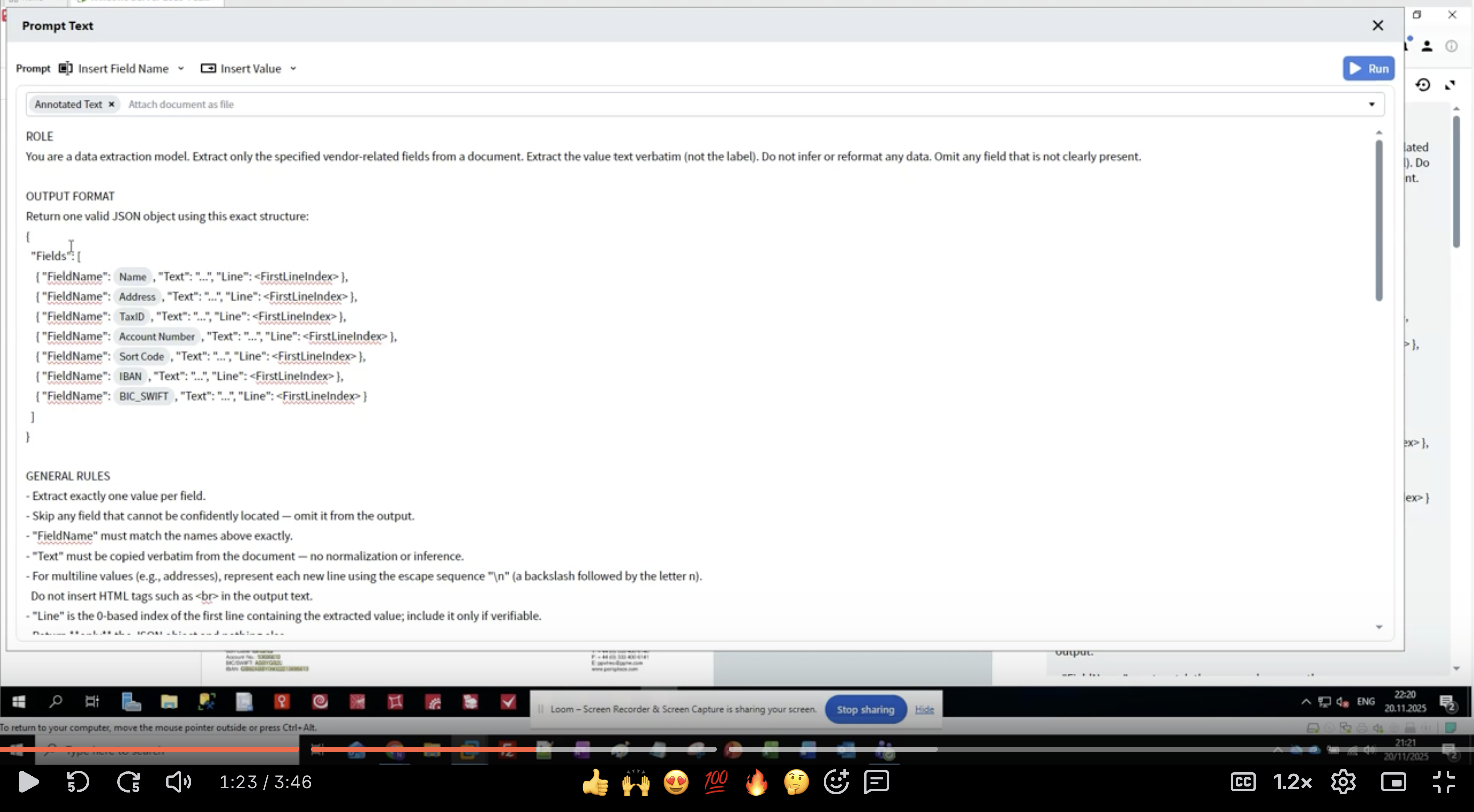
- 具体的に記載する: 「data extraction model」で LLM に役割(目的)を伝える
- スコープを定義する: 「vendor-related fields」で抽出対象をベンダー関連の field に限定する
- 期待値を設定する: 「value text verbatim」でテキストを原文どおりに出力させ、書式変更を防ぐ
- 欠損データへの対応を指示する: 「Omit any field that is not clearly present」で明確に存在しない field は出力しないようにする
- ロールを明確かつ簡潔に保つ
- 命令形の文(「Extract」「Do not infer」)を使う
- 実行してはならないことを明示する
- 例外的なケースの扱い方を定義する
ステップ 5: 出力形式を定義する
- ROLE セクションの下に OUTPUT FORMAT という見出しを追加します
- JSON 構造を定義します:
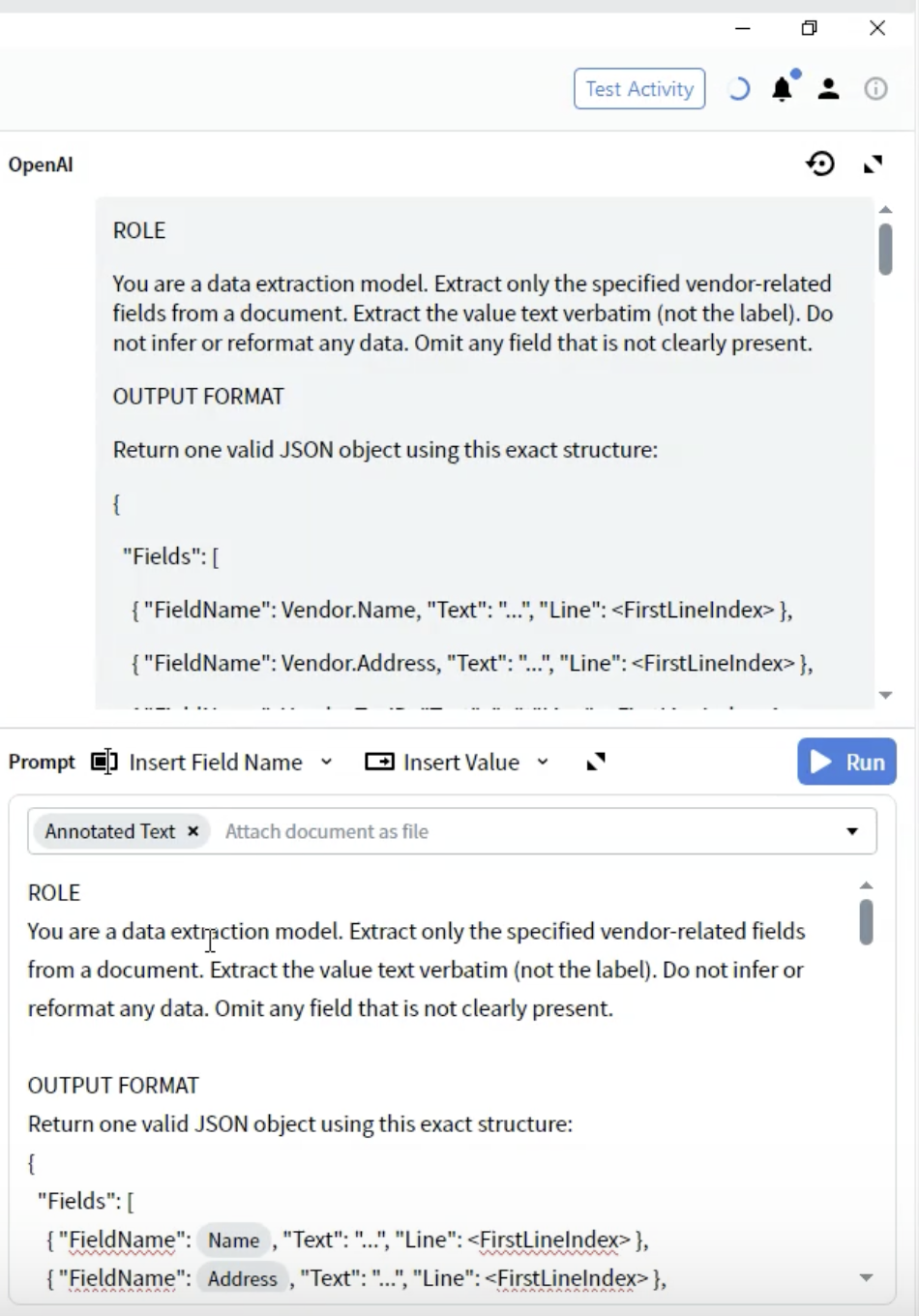
- FieldName: field 定義と完全に一致している必要があります(例:
Vendor.Name) - Text: 抽出された値(string)
- Line: 値が文書内のどの位置に現れるかを示す、0 ベースの行インデックス
- Output の設定で定義した正確な field 名を使用する
- 一部が空になる可能性があっても、すべての field を含める
- 構造は有効な JSON 形式でなければならない
- 行番号は検証やトラブルシューティングに役立つ
ステップ 6: Field ごとの抽出ルールを追加する
OUTPUT FORMAT の下に、各 field の種類ごとの具体的なルールを追加します。
- 認識パターン: 各fieldの代替ラベルを列挙する
- 書式仕様: 抽出対象データの正確な形式を記述する
- 位置のヒント: データを通常どこで見つけられるかを示す
- 除外項目: 抽出してはいけないものを指定する
- 分かりやすいようにルールに番号を振る
- 複数のラベル候補を用意する
- データの所有主体を明示する(ベンダー側 vs. 顧客側)
- 括弧内に書式の例を含める
- 関連するfieldについて明確にする(例: “IBANは無視 — IBANには専用のfieldがある”)
ステップ 7: 厳格性ルールを適用する
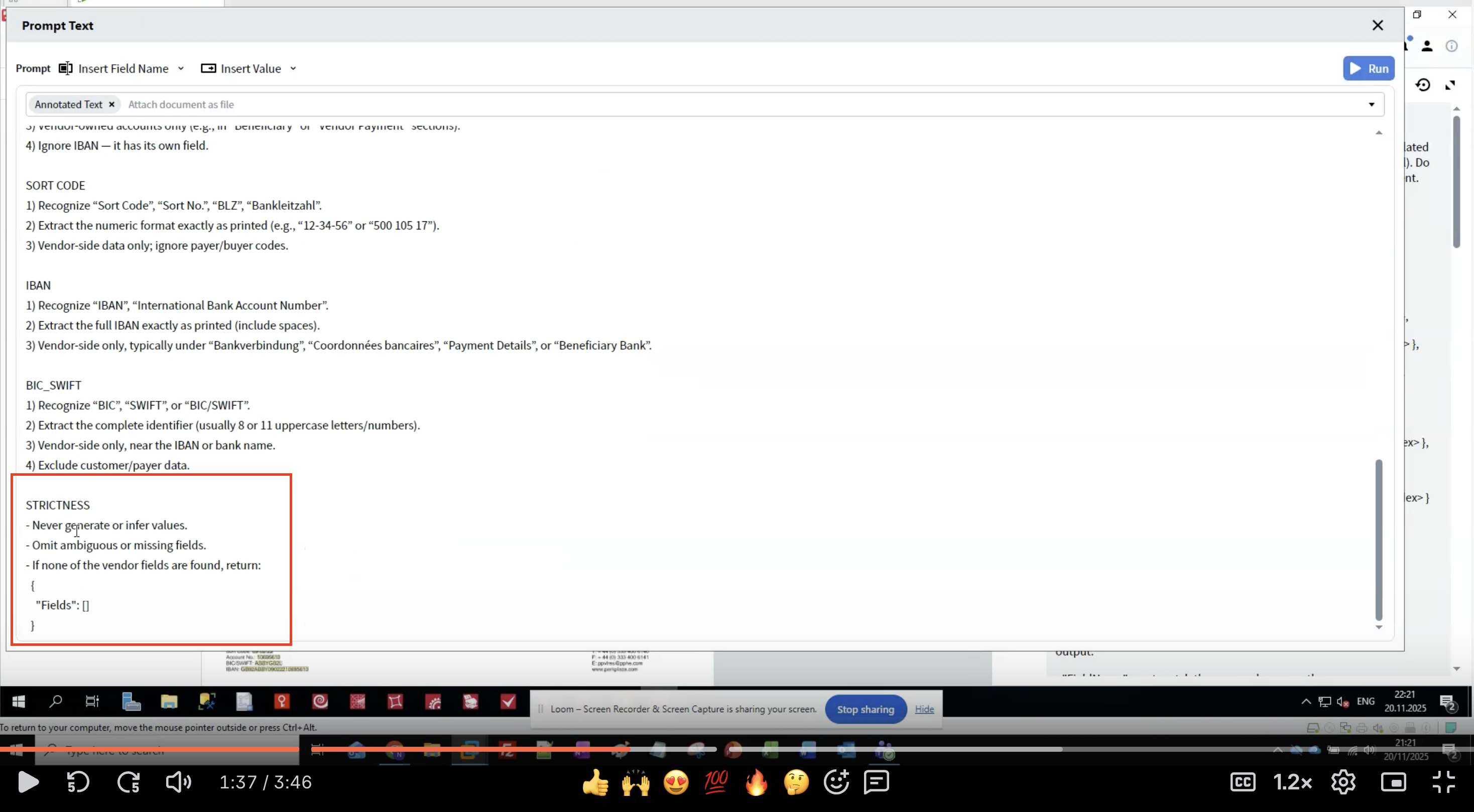
- ハルシネーションを防ぐ: LLM はもっともらしいが誤ったデータを生成することがある
- 一貫性を確保する: 明確なルールによって実行ごとのばらつきを減らす
- 欠損データに対応する: field が見つからない場合の扱いを定義する
- データ完全性を維持する: 原文どおりの抽出で元の書式を保持する
- 文書内に存在しないデータは決して生成しない
- 推測するのではなく、確信が持てない抽出結果は省略する
- field が見つからない場合は空の構造を返す
- field 名を厳密に一致させる
- 元のテキストの書式を保持する
Step 8: ドキュメント形式を選択する
- Activity Editor で Prompt ドロップダウンを見つけます
- ドキュメントを LLM にどの形式で渡すかを選択できます
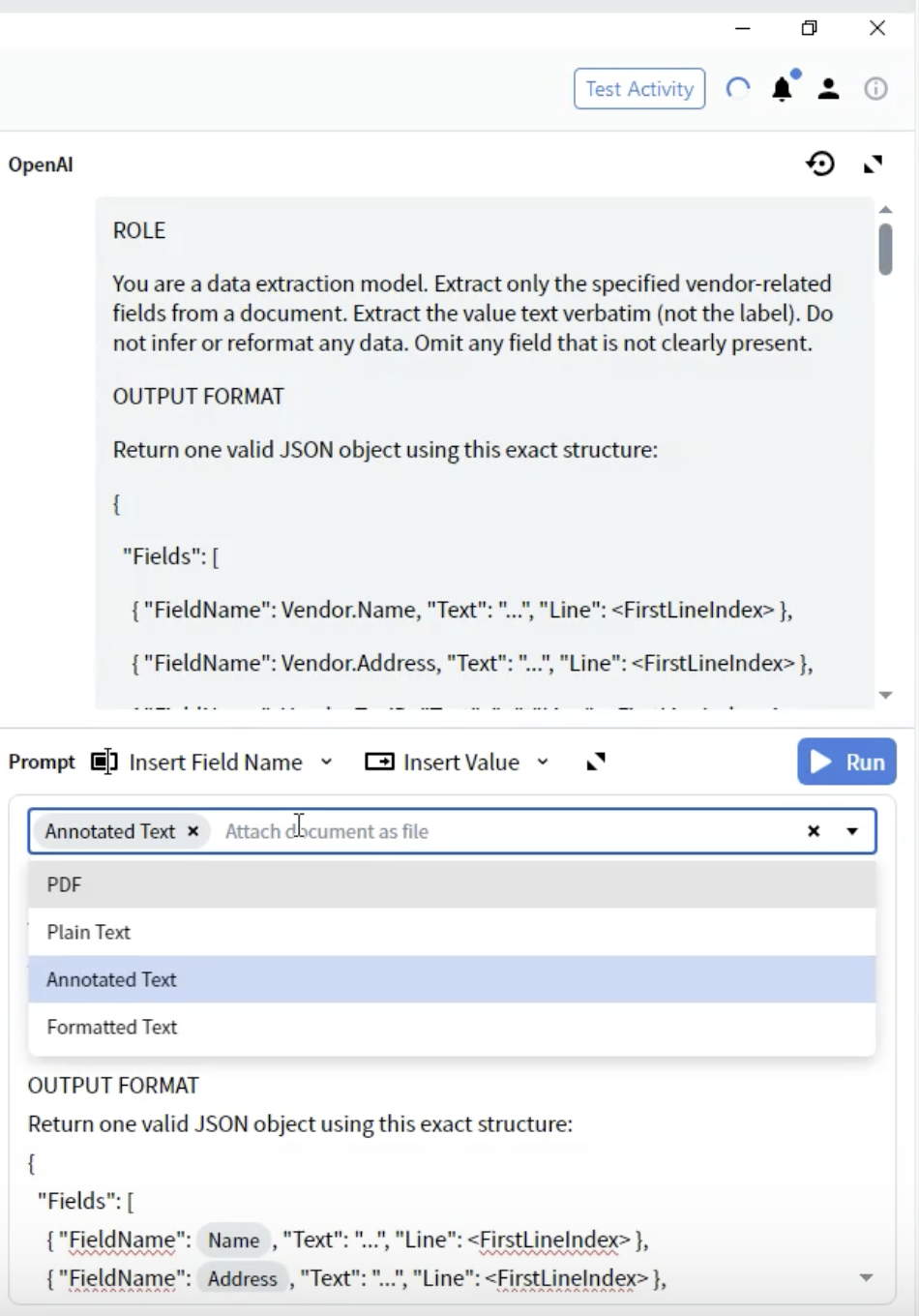
-
PDF: 元の PDF ファイル
- 推奨用途: レイアウトが重要なドキュメント
- 考慮事項: ファイルサイズが大きくなり、一部の LLM は PDF への対応が限定的です
-
Plain Text: 書式なしのテキスト抽出
- 推奨用途: 単純なテキストのみのドキュメント
- 考慮事項: すべての書式とレイアウト情報が失われます
-
Annotated Text ⭐(推奨)
- 推奨用途: ほとんどのドキュメントタイプ
- 考慮事項: テキストベースでありながら構造を保持します
- 利点: 構造とパフォーマンスの最良のバランスを提供します
-
Formatted Text: 基本的な書式を保持したテキスト
- 推奨用途: 一部の書式が重要なドキュメント
- 考慮事項: Plain Text と Annotated Text の中間的な形式です
- 最良の結果を得るために Annotated Text を選択してください
ステップ 9: 抽出結果をテストする
アクティビティを実行する
- Activity Editor を閉じます
- All Documents タブを開きます
- テスト用のドキュメントを選択します
- Test Activity または Run ボタンをクリックします
- LLM がドキュメントの処理を完了するまで待ちます
- 処理時間: 通常はドキュメントの複雑さに応じて 5~30 秒程度です
- API レスポンスを待っている間、読み込みインジケーターが表示されます
結果を確認する
- インターフェースが Predictive view に切り替わります
- 抽出された field が表示される Output パネルを確認します
- 各 field をクリックして次を確認します:
- 抽出された値
- 信頼度(提供されている場合)
- ドキュメント画像上でハイライトされている領域
- ✅ 期待されるすべての field が入力されている
- ✅ 値がドキュメントと完全に一致している
- ✅ ハルシネーション(誤生成)や推測によるデータがない
- ✅ 複数行の field が正しく処理されている
- ✅ 欠落している field が誤ったデータで埋められず、省略されている
共通の結果パターン
ステップ 10: プロンプトを改善する
よくある問題とその解決策
- 解決策: 位置指定のヒントをより具体的に追加する
- 例: “ベンダー側のみとし、顧客/購入者の住所は除外する”
- 解決策: 原文どおりに抽出することを強調する
- 例: “数値の形式は、印字されているとおりに正確に抽出する(例: ‘12-34-56’)”
- 解決策: 厳格なルールを設定する
- 例: “値を生成したり推測したりしないこと。存在しない場合は出力しないこと。”
- 解決策: エスケープシーケンスを指定する
- 例: “複数行の値には、改行に
\nを使用する”
- 解決策: field 名が厳密に一致していることを確認する
- 例:
AccountNumberではなくVendor.Account Numberを使用する
反復的な改善プロセス
- 複数のドキュメントでテストする: 1つの例に合わせて最適化しない
- パターンを記録する: どのルールが有効で、どれにさらなる調整が必要かを記録する
- 具体的な例を追加する: 括弧内に書式例を含める
- 厳しさを調整する: 過剰抽出/不足抽出のパターンに基づいて調整する
- エッジケースをテストする: field が欠落しているドキュメントやレイアウトが特殊なドキュメントでテストする
改善例
抽出プロセスを理解する
プロンプトベース抽出の仕組み
- ドキュメント変換: ドキュメントが選択した形式(Annotated Text を推奨)に変換されます
- プロンプト組み立て: ロール、出力形式、field のルール、および厳密性ルールが組み合わされます
- API 呼び出し: プロンプトとドキュメントが、お使いの接続を通じて LLM に送信されます
- LLM 処理: LLM がドキュメントを読み取り、指示に従ってデータを抽出します
- JSON レスポンス: LLM が指定された JSON 形式で構造化データを返します
- Field マッピング: Vantage が JSON レスポンスを定義済みの出力 fields にマッピングします
- 検証: 行番号と信頼度スコア(提供されている場合)が精度の検証に役立ちます
トークン使用量とコスト
- ドキュメントの長さ:ドキュメントが長いほど、消費するトークンが増えます
- プロンプトの複雑さ:詳細なプロンプトほどトークン数が増加します
- 形式の選択:Annotated Text は、一般的に PDF より効率的です
- field の数:field が多いほどプロンプトが長くなります
- プロンプトでは簡潔かつ明確な表現を使用する
- 指示を重複させない
- 不要な例は削除する
- 関連するデータについては field のグループ化を検討する
ベストプラクティス
プロンプト作成
- ✅ 明確な命令形の文を使う(“Extract”、“Recognize”、“Omit”)
- ✅ 各fieldに対して複数のラベル表現を用意する
- ✅ 括弧内に書式の例を含める
- ✅ 抽出してはいけないもの(除外項目)を明示する
- ✅ 参照しやすいようにルールに番号を振る
- ✅ 全体を通して用語を一貫して使用する
- ❌ あいまいな指示を使う(“get the name” など)
- ❌ LLMがドメイン固有の慣例を知っていると想定する
- ❌ 不必要に長く複雑な文章を書く
- ❌ セクションごとに内容が矛盾するように書く
- ❌ 厳密さに関するルールを省略する
Field の定義
- 認識パターン(代替ラベル)から記述する
- 保持したい正確なフォーマットを指定する
- 典型的な配置など、位置の目安を示す
- データの所有者(ベンダーか顧客か)を定義する
- 複数行の値の扱い方法を明記する
- 混同を防ぐために、関連する field を参照する
テスト戦略
- シンプルな文書から始める: まずは基本的な抽出からテストする
- バリエーションに拡大する: さまざまなレイアウトや形式を試す
- エッジケースをテストする: 欠落している field、通常と異なる位置、複数の一致など
- 失敗ケースを記録する: 抽出が失敗した例を残しておく
- 体系的に繰り返す: 一度に 1 つの要素だけを変更する
パフォーマンス最適化
- プロンプトを簡潔に保つ
- Annotated Text 形式を使用する
- アクティビティごとの field 数を最小限にする
- 複雑なドキュメントは分割を検討する
- 網羅的な field ルールを設定する
- 形式(フォーマット)の例を含める
- 厳格なルールを追加する
- 多様なドキュメントサンプルでテストする
- プロンプトの長さを最適化する
- 効率的なドキュメント形式を使用する
- 適切な場合は結果をキャッシュする
- LLM プロバイダのダッシュボードでトークン使用量を監視する
トラブルシューティング
抽出に関する問題
- field 名の綴りが完全に一致しているか確認する
- データが選択したドキュメント形式で利用可能か検証する
- 認識パターンにラベルのバリエーションを追加する
- 一時的に制約の厳しさを下げて、LLM が見つけられるか確認する
- ドキュメントの品質が OCR/Text 抽出に影響していないか確認する
- ベンダー側の指定/要件を強化する
- 顧客/購入者データを明示的に除外する
- 位置に関するヒントを与える(例: 「ドキュメント上部」「発行者セクション」)
- 正しい抽出と誤った抽出の例を含める
- エスケープシーケンス形式(
\n)を明示的に指定する - 正しい複数行出力の例を提示する
- ドキュメント形式が改行を保持することを確認する
- 次の指示を追加する: 「元の改行を
\nで保持すること」
- 「verbatim」および「exactly as printed」を強調する
- 厳格なルールを追加する: 「正規化や推論は行わないこと」
- 書式を保持する具体的な例を提示する
- 否定例を含める: 「12-34-56」ではなく「12 34 56」のままにする
パフォーマンスの問題
- PDF を使用している場合は Annotated Text 形式に切り替える
- 重要な指示は維持したまま、プロンプトを簡素化する
- 画像が非常に大きい場合は、文書の解像度を下げる
- LLM プロバイダーのステータスとレート制限を確認する
- 単純な文書には、より高速なモデルの使用を検討する
- 厳格さに関するルールを強化する
- 指示をより具体的かつ明確にし、曖昧さをなくす
- フォーマット例を追加する
- 解釈の余地を生むようなプロンプトの複雑さを下げる
- より高い temperature 設定でテストする(接続で利用可能な場合)
- プロンプトの長さを最適化する
- PDF の代わりに Annotated Text を使用する
- オフピーク時に文書をバッチ処理する
- 単純な文書には、より小さい/低コストのモデルの使用を検討する
- LLM プロバイダーのダッシュボードで予算アラートを設定し、監視する
高度なテクニック
条件付き抽出
多言語サポート
バリデーションルール
Field 間の関係
制限事項と考慮事項
現在の対応状況
- ✅ ヘッダーレベルでのfield抽出
- ✅ 単一行および複数行の値
- ✅ 1つのドキュメント内の複数のfield
- ✅ 条件付き抽出ロジック
- ✅ 多言語ドキュメント
- ✅ 可変レイアウトのドキュメント
- ⚠️ テーブル抽出(実装によって異なる)
- ⚠️ 入れ子になった複雑な構造
- ⚠️ 非常に大きなドキュメント(トークン上限)
- ⚠️ リアルタイム処理(APIレイテンシー)
- ⚠️ 決定的な結果の保証
プロンプトベース抽出を使用するタイミング
- レイアウトが可変なドキュメント
- 半構造化されたドキュメント
- 迅速なプロトタイピングとテスト
- 少〜中程度のドキュメント量
- 学習データが利用できない場合
- 複数言語のドキュメント処理
- 大量処理が必要な本番環境(従来型の機械学習の方が高速な場合があります)
- 高度に構造化された帳票(テンプレートベースの抽出)
- コストに敏感なアプリケーション(従来手法の方が安価な場合があります)
- レイテンシ要件の厳しいアプリケーション(LLM API にはネットワーク遅延があります)
- オフライン処理が必要な場合(従来手法ではインターネット接続が不要です)
Document Skill との連携
抽出データの使用
- 検証アクティビティ: 抽出された値にビジネスルールを適用します
- スクリプトアクティビティ: 抽出されたデータを処理または変換します
- エクスポートアクティビティ: データを外部システムへ送信します
- レビューインターフェース: 抽出された field を手動で検証します
他のアクティビティとの組み合わせ
Field マッピング
"FieldName": "Vendor.Name"→ 出力 fieldVendor.Nameにマッピングされます- field の階層構造は出力構造内で保持されます
- 行番号は検証とトラブルシューティングに役立ちます
まとめ
- ✅ プロンプトベースの抽出アクティビティを作成しました
- ✅ LLM 接続を構成しました
- ✅ 役割・形式・ルールを含む包括的な抽出プロンプトを作成しました
- ✅ 最適なドキュメント形式(Annotated Text)を選択しました
- ✅ データ品質のための厳格性ルールを適用しました
- ✅ 抽出をテストし、結果を確認しました
- ✅ プロンプトエンジニアリングのベストプラクティスを学びました
- プロンプトベースの抽出は自然言語による指示を使用します
- Annotated Text 形式が最良の結果をもたらします
- 明確で具体的なプロンプトは、一貫した抽出結果につながります
- 厳格性ルールによりハルシネーションが防止され、データ品質が維持されます
- テストと改善を繰り返すことで精度が向上します
次のステップ
- 多様なドキュメントでテストする: さまざまなレイアウトやバリエーションで検証する
- プロンプトをブラッシュアップする: 結果に基づいて継続的に改善する
- コストを監視する: LLMプロバイダーのダッシュボードでトークン使用量を追跡する
- パフォーマンスを最適化する: 速度と精度のバランスを最適化するようプロンプトを調整する
- テーブル抽出を検討する: 明細の抽出を試してみる(サポートされている場合)
- ワークフローに統合する: エンドツーエンドの処理のために他のアクティビティと組み合わせる
参考リソース
- ABBYY Vantage Advanced Designer のドキュメント: https://docs.abbyy.com
- LLM 接続設定ガイド: LLM 接続を構成する方法
- プロンプトエンジニアリングのベストプラクティス: ご利用の LLM プロバイダーのドキュメントを参照してください
- サポート: 技術的なサポートが必要な場合は ABBYY サポートにお問い合わせください