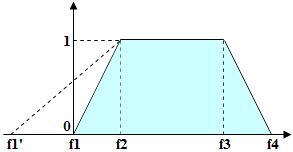
**퍼지 구간(Fuzzy interval)**은 가설의 길이에 따라 그 품질을 평가할 수 있게 해 주는 도구입니다. 퍼지 구간은 길이 단위(도트, 밀리미터 등)나 문자 수(행의 경우)로 측정될 수 있습니다. 퍼지 구간에 대해서는 가능한 값의 범위와 최적 값의 범위를 정의하는 네 개의 값을 지정해야 합니다. 이를 단순화하기 위해, 프로그램에는 사용하기 쉬운 퍼지 구간 편집기가 제공됩니다.퍼지 구간이 {f1,f2,f3,f4}이고, 탐지된 string의 길이(문자 수, 또는 탐지된 공백의 경우 도트 수)가 L이라고 가정해 보겠습니다. 길이 L이 f2와 f3 사이의 범위에 있을 경우(즉, L>=f2 and L<=f3), 가설의 품질은 1입니다. 길이가 f1과 f2 사이의 범위에 있을 경우, 가설의 품질은 0에서 1까지 비례하여 변화합니다(Quality(f1) = 0, Quality(f2)=1). 마찬가지로 길이가 f3과 f4 사이의 범위에 있을 경우, 가설의 품질은 1에서 0까지 비례하여 변화합니다(Quality(f3) = 1, Quality(f4) = 0). 길이가 f1과 f4의 범위를 벗어나는 경우(즉, Lf4), 가설의 품질은 0입니다(Quality(L) = 0). 탐지된 객체에 대한 가설의 품질은, 탐지된 객체의 길이에 따라 선택되는 Character count 속성 값과 곱해져 적용됩니다.
참고: 여러 요소로 이루어진 가설 체인의 품질은 체인에 포함된 각 요소의 가설 품질을 서로 곱하여 계산합니다. 체인이 충분히 길고, 제한 조건이 너무 엄격하여 구성 가설들의 품질 평가값이 너무 낮은 경우, 전체 체인의 최종 품질도 너무 낮아질 수 있습니다.
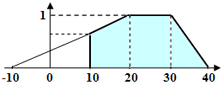
따라서, 선택된 가설이 가능한 한 가장 높은 품질 평가를 갖도록 하는 것이 좋습니다. 반면, 최선의 가설을 선택할 수 있도록 가설들을 그 품질에 따라 구분할 수 있어야 합니다. 그러므로 허용 가능한 가설에 대해 과도한 페널티가 부과되지 않도록, 가설 평가를 위한 수학 함수인 퍼지 구간을 적절히 설정해야 합니다.퍼지 구간의 왼쪽 경계에는 음수 값도 사용할 수 있습니다(실제로는 음수 길이의 string은 존재하지 않더라도). 이는 (0, 1) 구간에서 품질 그래프의 기울기를 완만하게 만들어 품질 페널티를 줄이는 데 유용할 수 있습니다. 만약 이 매개변수에 하한을 설정해야 하는 경우(예: string의 길이에 대한 퍼지 구간이 [-10,20,30,40}일 때 string의 길이가 10자보다 작을 수 없도록 해야 하는 경우), Hypothesis Evaluation에서 Value.Length >=10을 설정하여 직접 지정할 수 있습니다.퍼지 구간의 경계를 너무 엄격하게 설정하는 것은 권장되지 않습니다. 이는 특히 품질이 서로 다른 이미지를 처리할 때 중요합니다. 예를 들어, 일부 이미지에서는 원본 문서의 품질이 좋지 않거나 특정 스캐닝 옵션 때문에 문자 사이에 불필요한 공백이 생길 수 있습니다. 이 경우 프로그램은 하나의 문자를 여러 문자로 인식할 수 있으며, 구간이 지나치게 엄격하면 가설의 품질이 급격히 떨어질 수 있습니다. 그 결과, 프로그램은 그 가설(실질적으로는 올바른 가설일 수 있음)을 폐기하고 다른 가설을 선택할 수 있습니다. 이러한 이유로, 길이를 비교하여 가설을 선택해야 하는 경우, 이는 Hypothesis Evaluation에서 추가 조건을 사용하여 수행하는 것이 좋습니다.