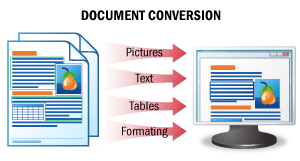
| O resultado deste cenário é uma versão editável de um documento. Neste cenário, as imagens dos documentos são reconhecidas com toda a formatação original preservada, e os dados são salvos em um formato de arquivo editável. Como resultado, você obtém versões editáveis dos seus documentos, que podem ser facilmente verificadas quanto a erros e modificadas. ConsulteConversão de Documentospara obter detalhes. |
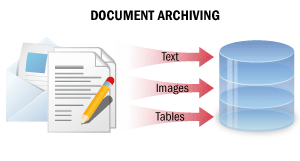
| Neste cenário de processamento, documentos em papel são convertidos em cópias digitais não editáveis contendo todas as informações do documento em formato pesquisável. Como resultado desse processamento, cópias digitais de documentos podem ser facilmente encontradas em um arquivo eletrônico por meio de pesquisa de texto completo, segmentos de texto dos documentos podem ser copiados, e os documentos podem ser enviados por e-mail ou impressos. ConsulteArquivamento de Documentospara obter detalhes. |
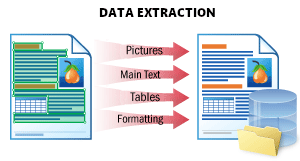
| Este cenário é utilizado para extrair todos os dados possíveis de um documento e armazená-los de forma estruturada. O resultado é um arquivo JSON que representa a estrutura do documento. Ele armazena todos os objetos do documento: texto impresso e manuscrito, tabelas, códigos de barras, marcas de seleção e imagens com sua localização e atributos. Esse formato é ideal para processamento posterior, armazenamento de dados em um banco de dados ou integração com outro aplicativo. ConsulteExtração de Dadospara obter detalhes. |
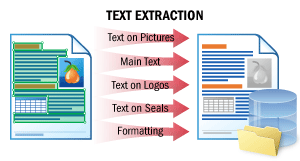
| Este cenário permite a extração do texto principal de um documento, bem como textos em logotipos, selos e quaisquer outros elementos além do texto principal. A ordem natural do texto “como um ser humano o leria” é preservada. Em seguida, você pode enviar os documentos para mecanismos de processamento de linguagem natural (PLN) do seu lado, por exemplo, para serem resumidos rapidamente, pesquisados em busca de informações sensíveis ou submetidos a uma análise de sentimento. ConsulteExtração de Textopara obter detalhes. |
| No reconhecimento em nível de campo, fragmentos de texto curtos são reconhecidos para capturar dados de determinados campos. A qualidade do reconhecimento é fundamental neste cenário. Este cenário também pode ser utilizado como parte de cenários mais complexos, nos quais dados relevantes precisam ser extraídos de documentos (por exemplo, para capturar dados de documentos em papel em sistemas de informação e bancos de dados, ou para classificar e indexar documentos automaticamente em Sistemas de Gerenciamento de Documentos). Neste cenário, o sistema reconhece algumas linhas de texto em apenas alguns dos campos ou o texto completo em uma imagem pequena. O sistema calcula uma pontuação de confiança para cada caractere reconhecido. Essas pontuações podem ser usadas na verificação dos resultados do reconhecimento. Além disso, o sistema pode armazenar múltiplas variantes de reconhecimento para palavras e caracteres no texto, que podem ser utilizadas em algoritmos de votação para melhorar a qualidade do reconhecimento. ConsulteReconhecimento em Nível de Campopara obter detalhes. |
| Neste cenário, o ABBYY FineReader Engine é utilizado para ler códigos de barras. A leitura de códigos de barras pode ser necessária, por exemplo, para separação automática de documentos, para processamento de documentos por um Sistema de Gerenciamento de Documentos, ou para indexação e classificação de documentos. Este cenário pode ser utilizado como parte de outros cenários. Por exemplo, documentos digitalizados com scanners de produção de alta velocidade podem ser separados por meio de códigos de barras, ou documentos preparados para armazenamento de longo prazo podem ser inseridos em Sistemas de Gerenciamento de Documentos de arquivamento com base nos valores de seus códigos de barras. Ao extrair códigos de barras de textos, o sistema pode detectar todos os códigos de barras ou apenas códigos de barras de um determinado tipo com um determinado valor. O sistema pode obter o valor de um código de barras e calcular seu dígito de verificação. Os valores de códigos de barras reconhecidos podem ser salvos nos formatos mais convenientes para processamento posterior, por exemplo, em TXT. ConsulteReconhecimento de Códigos de Barraspara obter detalhes. |
| Cartões de visita contêm informações profissionais sobre uma empresa ou pessoa. Eles podem incluir nome da pessoa, empresa, números de telefone, fax, e-mail, endereços de sites e informações similares. Pode ser necessário capturar essas informações de cartões de visita em papel e salvá-las em formato eletrônico. Isso pode ser uma agenda eletrônica de um celular, cliente de e-mail ou qualquer outro sistema de armazenamento de dados. Por exemplo, cartões de visita são frequentemente compartilhados por e-mail ou rede no formato vCard. ConsulteReconhecimento de Cartões de Visitapara mais detalhes. |
| Os documentos oficiais de viagem ou de identidade de muitos países contêm uma zona de leitura mecânica (MRZ) que garante um processamento mais preciso dos dados do documento. Este cenário é utilizado para extrair dados de uma zona de leitura mecânica em documentos de identidade durante processos de cadastro ou verificação de clientes. O sistema reconhece a MRZ na imagem do documento e extrai os dados dela. Os dados extraídos contêm vários campos com informações pessoais sobre o documento e seu titular (tipo e data de validade do documento, nome e sobrenome do titular, etc.). É possível pesquisar nos campos, verificar os dados e salvá-los em um arquivo externo para processamento posterior. ConsulteMachine-Readable Zone Capturepara mais detalhes. |
| Somente Windows. Neste cenário, o ABBYY FineReader Engine é utilizado em um “computador de digitalização,” que digitaliza imagens e as salva como arquivos. Este cenário pode ser utilizado como parte de outros cenários na etapa preliminar do processamento de documentos, ou seja, para obter versões eletrônicas de documentos para processamento posterior. Entre os exemplos de uso estão a digitalização de documentos para fins de arquivamento, a obtenção de versões editáveis de documentos e a extração de dados relevantes de documentos. Os documentos em papel são digitalizados e as imagens são salvas em formato eletrônico, gerando versões eletrônicas de alta qualidade dos seus documentos impressos. ConsulteScanningpara mais detalhes. |
| A tarefa de classificação de documentos consiste em atribuir um documento a uma das categorias definidas pelo usuário. Pode ser necessário lidar com um fluxo de documentos composto por documentos de vários tipos, como contratos, faturas e recibos. É preciso identificar o tipo de cada documento. Por exemplo, pode ser necessário organizar os documentos em pastas diferentes ou renomeá-los de acordo com seus tipos. Isso pode ser feito automaticamente com um sistema pré-treinado. O principal aspecto deste cenário é que você sabe quais tipos de documentos serão processados. O ABBYY FineReader Engine pode classificar documentos pela aparência ou pelo conteúdo. ConsulteDocument Classificationpara mais detalhes. |
| Ao trabalhar com documentos em papel, é necessário localizar e corrigir erros ou alterações feitas intencionalmente. Este cenário é utilizado para comparar documentos de especial importância, como contratos e documentação bancária, com suas cópias. O resultado da comparação contém informações sobre as diferenças no tipo de conteúdo (somente texto), no tipo de modificação (excluído, inserido ou modificado) e suas localizações no original e na cópia. É possível obter a lista das diferenças detectadas ou a região de qualquer alteração e salvar o resultado da comparação em um arquivo externo para processamento posterior ou armazenamento de longo prazo. ConsulteDocument Comparisonpara mais detalhes. |
Visão geral
Visão geral dos cenários básicos de uso
Esta seção descreve os cenários mais comuns em que o ABBYY FineReader Engine pode ser usado. Recomendamos que você comece a trabalhar com o ABBYY FineReader Engine selecionando o cenário mais adequado à sua tarefa. Depois de identificar o cenário apropriado, você encontrará uma descrição detalhada do cenário, orientações de implementação e sugestões para otimizar o código para tarefas específicas na seção Implementação dos cenários básicos de uso.


Implementação de cenários básicos de uso