Encontrando a última ocorrência de uma entidade nomeada
Regra para extrair a última ocorrência de organização
Exemplo
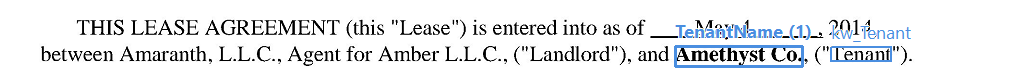
Extraindo um montante de dinheiro declarado tanto por extenso quanto em algarismos
Regra para extrair um montante em dinheiro
Exemplo

Encontrando segmentos por meio de palavras-chave
Regra para extrair títulos de segundo nível no elemento de pesquisa kw_Heading2
Regra para extrair o segmento no elemento de pesquisa de Segmento
Exemplo

kw_Heading2 e, em seguida, o texto entre quaisquer duas ocorrências consecutivas do elemento de pesquisa kw_Heading2 é extraído para uma instância do elemento de pesquisa Segment.
Agrupando informações sobre cada entidade
- Procurar nomes de organizações, criar uma nova instância do elemento de busca de grupo
Party_Grouppara cada nome encontrado e preencher seu elemento de busca filho chamado “Organization_Name”. - Procurar o endereço e a função que estejam a não mais do que, digamos, 20 tokens de cada instância do nome da organização, acessar a instância de
Party_Groupque é o pai do nome da organização e preencher os elementos de busca filhos chamados “Address” e “Role” nessa instância.
Regra para extrair o elemento de pesquisa Organization_Name
Regra para extrair o elemento de busca Address
Regra para extrair o elemento de pesquisa de função
Exemplo


Encontrando a data e a hora juntas
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?). Em seguida, procuramos uma entidade nomeada Date localizada próxima a ele. Por fim, concatenamos as sequências de tokens encontradas e atribuimos o resultado a um elemento de pesquisa chamado “TimeAndDate”.
Regra para extrair data e hora combinadas
Exemplo
