Antes de começar
- Abra a atividade “Sick Note DE” no Activity Editor.
- Selecione um dos documentos do conjunto de documentos.
- Verifique se o modo avançado das propriedades do elemento está habilitado. Para ativar ou desativar esse modo, clique no ícone no painel Properties.
- Todos os documentos carregados passaram por pré-reconhecimento, e é útil ver quais objetos foram encontrados na imagem. Clique no ícone. Se você não vir esse ícone devido ao tamanho da tela, clique no ícone e selecione Recognized Words. Os objetos correspondentes serão destacados na imagem do documento. Você pode alternar entre vários tipos de objetos destacados a qualquer momento. Por exemplo, alternar para Recognized Lines pode ser útil ao procurar parágrafos, e alternar para Separators facilitará a configuração de um elemento de pesquisa do tipo Separator.
- Se um elemento de pesquisa estiver fora da área de pesquisa, ele não será encontrado. Habilite a opção Show search area no menu de contexto da imagem do documento. A área de pesquisa de cada elemento ficará destacada em verde quando você avaliar os resultados da correspondência.
Extraindo os dados do paciente
- Clique em Create Element e selecione o elemento Group na lista suspensa. Altere o nome para “PatientDataArea”.
- Um novo elemento de pesquisa do tipo grupo é definido como obrigatório por padrão. Se um elemento obrigatório não for encontrado, o Activity Editor gera um erro e a correspondência é interrompida. Esse cenário permite que atividades sejam ignoradas se não forem adequadas para um determinado documento. No entanto, neste tutorial estamos criando uma atividade para extrair dados de todos os documentos recebidos, portanto queremos que o grupo seja opcional. Na seção Under what conditions, altere o valor Element is para Optional.
- Queremos localizar o parágrafo que contém o nome e o endereço do paciente. Em documentos em alemão, o parágrafo que procuramos está sempre no campo com o rótulo “Name, Vorname … ”. Precisamos encontrar esse texto no documento e usá-lo como referência para buscar os dados que queremos extrair. a. Palavras-chave podem ser encontradas usando o elemento de pesquisa Static Text. Clique em Create Element e selecione o elemento Static Text na lista suspensa. Altere o nome para “kwPatientTitle”. b. Insira o texto “Name, Vorname” no campo Text to find no painel Properties. c. Clique em Match. Quando o processamento terminar, você verá a Tree of Hypotheses abaixo do documento. Verifique se o Advanced Designer encontrou o texto estático desejado. Um ponto verde ao lado do nome do elemento indica que um elemento correspondente foi encontrado no documento. Se você clicar no nome do elemento na Tree of Hypotheses, verá uma moldura violeta ao redor da região correspondente no documento.
Se um elemento não for encontrado, você verá um ponto laranja ao lado do nome e uma moldura laranja ao redor da imagem do documento. Lembre-se de que a qualidade da hipótese de um elemento afeta o estado dos elementos seguintes na cadeia e a qualidade geral da cadeia. Você pode encontrar informações detalhadas sobre a qualidade da hipótese na documentação.
- Agora vamos encontrar o limite inferior da célula que contém o nome e o endereço do paciente. Faremos isso usando um elemento Separator. a. Adicione um elemento Separator ao grupo e nomeie-o como “SeparatorBottom”. Defina o comprimento mínimo como 200. b. Clique com o botão direito no elemento e selecione Match Element no menu de contexto. Você verá que a Tree of Hypotheses contém muitos pontos verdes. Eles correspondem a diferentes separadores que atendem aos critérios de busca. Você pode clicar em cada ponto para ver o objeto correspondente na imagem. c. Para restringir os critérios de busca, especifique a área de pesquisa do separador. Clique em Match para encontrar o elemento “kwPatientTitle” que será usado como elemento âncora. Na seção Where to search do painel Properties, clique em Draw on Image. Selecione o elemento “kwPatientTitle” no documento e clique no ícone de seta para baixo para definir a área de pesquisa abaixo da palavra-chave e o ícone mais próximo para procurar o separador mais próximo da palavra‑chave. Você pode encontrar uma descrição detalhada dos elementos âncora na documentação. d. Clique em Match e verifique se o Advanced Designer encontrou o separador abaixo do elemento “kwPatientTitle”. Você pode verificar a hipótese de cada elemento clicando no seu nome na seção Tree of Hypotheses.
- Um rótulo e um separador são elementos de referência confiáveis para os dados do paciente. No entanto, se a qualidade de impressão for muito baixa, há a possibilidade de que o texto do rótulo não seja reconhecido ou que o separador não seja encontrado. Para garantir bons resultados de extração, vamos procurar um parágrafo que esteja entre o rótulo e o separador. Um parágrafo é um bloco uniforme de texto, o que significa que ele pode ser encontrado com sucesso mesmo que alguns elementos de limite não sejam encontrados. a. Crie um elemento de pesquisa Paragraph e nomeie-o como “NameAddressParagraph”. b. Altere Text alignment para Left. c. Os dados do paciente ocupam de duas a cinco linhas; portanto, defina a Line count de 2 a 5. d. Especifique a área de pesquisa do parágrafo. Desta vez, use o menu Add na seção Where to search. O elemento deve estar localizado abaixo do elemento “kwPatientTitle” e acima do elemento “SeparatorBottom”. e. Clique em Match.
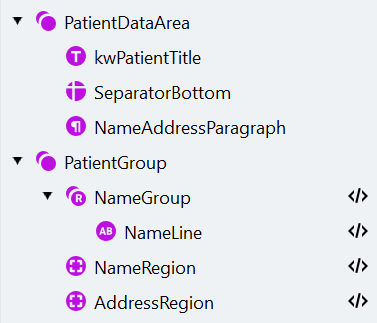
- Agora queremos extrair os dados do paciente. Crie um novo elemento de grupo chamado “PatientGroup”.
- O nome do paciente pode ocupar uma ou duas linhas. Para capturar várias instâncias de um elemento, usaremos um grupo repetido. a. Crie um elemento de pesquisa Repeating Group e nomeie-o como “NameGroup”. Especifique 2 como o número máximo de repetições. Torne o elemento opcional. b. Queremos procurar as linhas que fazem parte do parágrafo “NameAddressParagraph”. Para definir a região do elemento como a área de pesquisa, clique no ícone do editor de código abaixo da imagem do documento e cole o seguinte script na seção Search Conditions do Code Editor:
As configurações padrão permitem que a string contenha até 30% de caracteres não incluídos em nenhum conjunto. Isso ajuda a encontrar strings mesmo quando alguns caracteres são reconhecidos incorretamente ou não estão incluídos no conjunto (como caracteres com sinais diacríticos). Você pode ajustar essa configuração alterando o valor de Allowed errors no painel Properties.
g. Especifique a área de pesquisa para o elemento “NameLine”: abaixo do elemento “kwPatientTitle” e o mais próximo possível dele.
h. Clique em Match e revise a Tree of Hypotheses. Você verá que duas sequências de caracteres são encontradas. No entanto, a segunda string contém o endereço do paciente.
i. Para excluir o endereço dos resultados da pesquisa, verificaremos se a primeira string contém tanto o primeiro nome quanto o sobrenome. Isso pode ser feito adicionando uma condição de pesquisa simples em script. Selecione o elemento de pesquisa “NameLine” e abra o editor de código Search Conditions.
j. Consideramos que a primeira linha contém um nome completo se ela contiver uma vírgula e um espaço em branco. Se ela contiver um nome completo, não queremos procurar uma segunda instância do grupo repetido. Cole o seguinte script no editor:
- O nome do paciente extraído na etapa 7 será mapeado para o campo “Name”. Também vamos extrair e mapear o endereço do paciente.
a. Dentro de “PatientGroup”, crie um elemento de pesquisa do tipo Character String chamado “Address” com a mesma configuração de conjunto de caracteres do elemento “NameLine”.
b. Especifique a área de pesquisa para o elemento usando código: o endereço deve estar localizado abaixo de “NameLine” ou, caso esse elemento não seja encontrado, abaixo da primeira linha do elemento “NameAddressParagraph”.
d. Clique em Match. Esta é a estrutura de elementos de pesquisa:
- Abra a caixa de diálogo Manage Fields, crie os campos correspondentes e mapeie-os para os elementos de pesquisa da seguinte forma:
| Name | Type | Search element |
|---|---|---|
| Name | Campo de texto no grupo “Patient” | NameLine |
| Address | Campo de texto no grupo “Patient” | Address |
- Exclua os elementos de pesquisa que foram criados automaticamente para os novos campos.
Extraindo o tipo de atestado médico
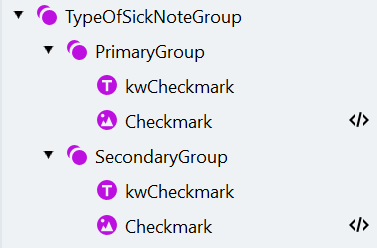
- Crie um elemento Group chamado “TypeOfSickNoteGroup”. Torne o elemento opcional.
- Para armazenar as informações sobre ambas as marcas de seleção, crie um elemento de pesquisa Repeating Group e chame-o de “PrimaryGroup”.
a. É uma boa prática restringir a área de pesquisa para o grupo de elementos. Especifique a área de pesquisa usando código: à direita do elemento “PatientGroup” e acima do elemento “DoctorAreaGroup” (que será criado posteriormente). **Observação: **sempre especifique a condição “Exists” ao usar elementos futuros.
c. Crie um elemento de pesquisa Object Collection chamado “Checkmark” com as seguintes configurações: Type:
Checkmark, Checkmark state: Checked, Minimum height: 10, Maximum width: 20, Maximum height: 20. Especifique que o elemento está localizado à esquerda do elemento “kwPrimary” e o mais próximo possível dele. d. Clique em Match.
- Copie e cole o grupo “PrimaryGroup”. Renomeie o grupo copiado para “SecondaryGroup”. Este grupo será obrigatório.
- Edite o “SecondaryGroup”.
a. Renomeie o elemento “kwPrimary” para “kwSecondary” e defina o texto a encontrar como “Folgebescheinigung”. Especifique a área de pesquisa: abaixo do elemento “kwPrimary” do “PrimaryGroup”.
b. Especifique a área de pesquisa para o elemento “Checkmark”: à esquerda de “kwSecondary” e o mais próximo possível dele.
c. O elemento de pesquisa Object Collection encontra uma coleção de todos os objetos adequados dentro da área de pesquisa. Se as marcas de seleção estiverem localizadas na mesma linha, o elemento “Checkmark” do “SecondaryGroup” também poderá encontrar a marca de seleção primária. Para evitar isso, exclua a marca de seleção primária (elemento “Checkmark” do “PrimaryGroup”) da área de pesquisa do elemento “Checkmark” do “SecondaryGroup”.
d. Clique em Match.
- Abra a janela Manage Fields, crie os campos correspondentes e faça o mapeamento para os elementos de pesquisa da seguinte forma:
| Name | Type | Search element |
|---|---|---|
| Type of Sick Note | Checkmark group | |
| Primary | Checkmark in the “Type of Sick Note” checkmark group | PrimaryGroup -> Checkmark |
| Secondary | Checkmark in the “Type of Sick Note” checkmark group | SecondaryGroup -> Checkmark |
- Exclua os elementos de pesquisa que foram criados automaticamente para os novos campos.
Extraindo os dados do médico
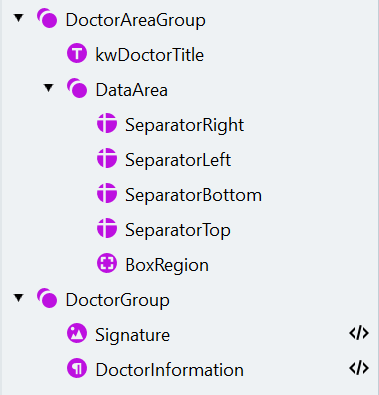
- Crie um elemento Group chamado “DoctorAreaGroup”. Torne o elemento opcional.
- A caixa que vamos procurar contém um rótulo. Para encontrá‑la, crie um elemento Static Text chamado “kwDoctorTitle” (texto a encontrar: “Unterschrift des Arztes”).
- Dentro do grupo “DoctorAreaGroup”, crie outro grupo chamado “DataArea”.
- A caixa que contém as informações e a assinatura do médico é uma combinação de quatro separadores. Eles estão localizados ao redor do elemento “kwDoctorTitle”. No entanto, devemos configurar os elementos de forma que o programa consiga encontrá‑los mesmo se o elemento “kwDoctorTitle” não tiver sido encontrado. No grupo “DataArea”, crie quatro elementos de pesquisa Separator com as seguintes propriedades:
| Name | Orientation | Minimum length | Search area |
|---|---|---|---|
SeparatorRight | Vertical | 180 | À direita de “kwDoctorTitle”, mais próximo da borda direita da página |
SeparatorLeft | Vertical | 180 | À esquerda de “kwDoctorTitle”, à esquerda de “SeparatorRight” (caso “kwDoctorTitle” não tenha sido encontrado), mais próximo de “SeparatorRight”, abaixo de “SeparatorRight” (clique no ícone à direita do nome do separador e selecione Top Boundary of Region), exclua “SeparatorRight” |
SeparatorBottom | Horizontal | 200 | Abaixo de “kwDoctorTitle” (com ajuste de -10 pontos), à direita de “SeparatorLeft”, à esquerda de “SeparatorRight”, mais próximo da borda inferior da página (esta configuração será útil caso “kwDoctorTitle” não tenha sido encontrado) |
SeparatorTop | Horizontal | 200 | Acima de “kwDoctorTitle”, à direita de “SeparatorLeft”, mais próximo de “TypeOfSickNoteGroup”, exclua “SeparatorBottom” |
- Poderíamos especificar manualmente a área de pesquisa da assinatura do médico e das informações do médico em relação aos separadores encontrados. Em vez disso, vamos criar um elemento Region que corresponda à área delimitada pelos separadores. Crie um elemento de pesquisa Region chamado “BoxRegion” e especifique a área de pesquisa: à esquerda de “SeparatorRight”, à direita de “SeparatorLeft”, acima de “SeparatorBottom” e abaixo de “SeparatorTop”.
- Crie um novo grupo chamado “DoctorGroup”.
- Para localizar a assinatura do médico, crie um elemento Object Collection com as seguintes configurações dentro de “DoctorGroup”:
| Property | Value |
|---|---|
| Name | Signature |
| Type | Picture |
| Minimum width | 15 |
| Minimum height | 15 |
| Maximum width | 600 |
| Maximum height | 350 |
| Search Conditions section of the Code Editor | A assinatura pode estar localizada parcialmente fora da caixa. Para encontrar a imagem inteira, vamos expandir a área de pesquisa em 100 pontos em cada direção: RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect.GetInflated(100dot,100dot); |
- Para extrair as informações em texto da caixa, crie um elemento Paragraph com as seguintes configurações:
| Property | Value |
|---|---|
| Name | DoctorInformation |
| Maximum line count | 6 |
| Search area | Acima de “kwDoctorTitle”, exclua “Signature” |
| Search Conditions section of the Code Editor | RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect; |
- Clique em Match e certifique‑se de que os elementos sejam encontrados corretamente.
- Abra a caixa de diálogo Manage Fields, crie os campos correspondentes e faça o mapeamento para os elementos de pesquisa da seguinte forma:
| Name | Type | Search element |
|---|---|---|
| Doctor Information | Campo de texto no grupo “Doctor” | DoctorInformation |
| Signature | Campo de imagem no grupo “Doctor” | Signature |
- Exclua os elementos de pesquisa que foram criados automaticamente para os novos campos.