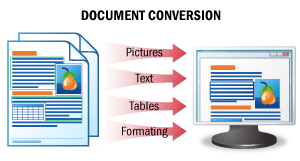
| 此场景的输出结果是文档的可编辑版本。 在此场景中,系统对文档图像进行识别,完整保留所有原始格式,并将数据保存为可编辑的文件格式。最终,您将获得文档的可编辑版本,可方便地进行错误检查和内容修改。 详情请参阅文档转换。 |
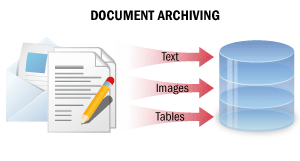
| 在此处理场景中,纸质文档被转换为不可编辑的数字副本,以可搜索的格式保存所有文档信息。经过此类处理后,可通过全文搜索在电子档案中快速找到文档的数字副本,还可复制文档文本片段,以及通过电子邮件发送或打印文档。 详情请参阅文档归档。 |
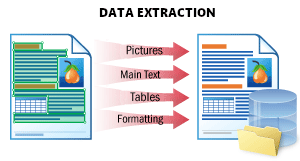
| 此场景用于从文档中提取所有可能的数据,并以结构化方式存储。 输出结果为一个表示文档结构的 JSON 文件,其中存储了所有文档对象:印刷文本和手写文本、表格、条码、复选标记以及图像的位置和属性信息。此格式非常适合后续处理、将数据存入数据库或与其他应用程序集成。 详情请参阅数据提取。 |
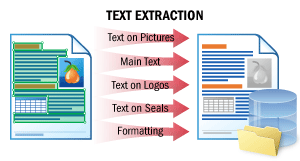
| 此场景可提取文档正文文本,以及徽标、印章和其他非正文元素上的文本。 文本的自然阅读顺序 (即”人类阅读方式”) 将得到保留。之后,您可以将文档输入自己的自然语言处理 (NLP) 引擎,例如用于快速摘要生成、敏感信息检索或情感分析。 详情请参阅文本提取。 |
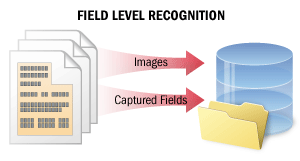
| 在字段级识别场景中,系统对短文本片段进行识别,以从特定字段中采集数据。识别质量在此场景中至关重要。 此场景还可作为更复杂场景的组成部分,用于从文档中提取有价值的数据 (例如,将纸质文档中的数据录入信息系统和数据库,或在文档管理系统中自动对文档进行分类和索引) 。 在此场景中,系统可识别部分字段中的若干行文本,或识别小图像上的完整文本。系统会为每个已识别字符计算置信度评分,该评分可在核查识别结果时参考使用。此外,系统还可为文本中的单词和字符保存多个识别候选项,这些候选项可用于投票算法,从而提升识别质量。 详情请参阅字段级识别。 |
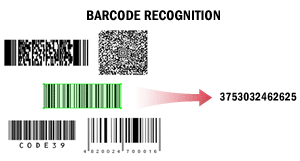
| 在此场景中,ABBYY FineReader Engine 用于读取条码。读取条码可能出于多种目的,例如自动文档分割、通过文档管理系统处理文档,或对文档进行索引和分类。 此场景可作为其他场景的组成部分。例如,使用高速生产扫描仪扫描的文档可通过条码进行分割,或根据条码值将需要长期存储的文档归入档案文档管理系统。 从文本中提取条码时,系统可检测所有条码,或仅检测具有特定值的特定类型条码。系统可获取条码的值并计算其校验和。 已识别的条码值可保存为最便于后续处理的格式,例如 TXT 格式。 详情请参阅条码识别。 |
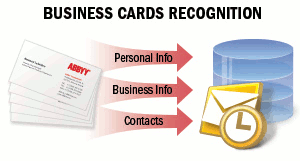
| 名片包含公司或个人的商业信息,可包括姓名、公司、电话号码、传真、电子邮件、网站地址等内容。您可能需要从纸质名片中采集这些信息并以电子格式保存,例如保存到手机电子通讯录、电子邮件客户端或其他数据存储系统中。名片通常以 vCard 格式通过电子邮件或网络进行传递。 详情请参阅名片识别了解详情。 |
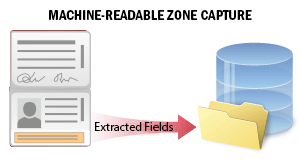
| 许多国家的官方旅行证件或身份证件均包含机器可读区域 (MRZ) ,有助于更准确地处理文档数据。 此场景用于在客户入职或身份验证流程中,从身份证件的机器可读区域提取数据。系统识别文档图像上的 MRZ 并从中提取数据。提取的数据包含多个字段,涵盖文档及其持有人的个人信息 (文档类型、有效期、持有人姓名等) 。您可以搜索这些字段、验证数据,并将其保存到外部文件以供后续处理。 请参阅机器可读区域捕获了解详情。 |
| 仅限 Windows。 在此场景中,ABBYY FineReader Engine 部署于”扫描计算机”上,负责扫描图像并将其保存为文件。 此场景可作为其他场景的组成部分,用于文档处理的前期阶段,即获取文档的电子版本以供后续处理。典型用途包括:扫描文档用于存档、获取文档的可编辑版本,以及从文档中提取有效数据。 纸质文档经扫描后,图像以电子格式保存,生成高质量的印刷文档电子版本。 请参阅扫描了解详情。 |
| 文档分类的任务是将文档归入用户定义的某个类别。您可能需要处理由多种类型文档组成的文档流,例如合同、发票、收据。您需要识别每个文档的类型,例如将文档整理到不同的文件夹,或按类型重命名。这些操作均可通过预训练系统自动完成。 此场景的核心前提是您已知晓将要处理的文档类型。ABBYY FineReader Engine 可按文档外观或内容对文档进行分类。 请参阅文档分类了解详情。 |
| 在处理纸质文档时,您需要找出并纠正其中的错误或蓄意改动。 此场景用于将重要文档 (如合同和银行文件) 与其副本进行比较。比较结果包含以下差异信息:内容类型 (仅限文本) 、修改类型 (删除、插入或修改) 以及差异在原件和副本中的位置。您可以获取检测到的差异列表或任意改动的区域,并将比较结果保存到外部文件以供进一步处理或长期存储。 请参阅文档比较了解详情。 |
概述
基本使用场景概述
本节介绍 ABBYY FineReader Engine 最常见的使用场景。我们建议您在开始使用 ABBYY FineReader Engine 时,先选择最适合自己任务的场景。找到合适的场景后,您可以在 基本使用场景实现 部分中查看该场景的详细说明、实施建议,以及针对特定任务的代码优化建议。


基本使用场景实现