跳转到主要内容
ABBYY Documentation home page
简体中文
FineReader Engine
Search documentation...
⌘K
询问AI
Website
Get Started
Get Started
搜索...
Navigation
主要新功能
多 CPU 识别架构
简介
导览
API 参考
Visual Components 参考
许可管理
安装
分发版
技术规格
常见问题
发行说明
概述
ABBYY FineReader Engine 12 简介
基本使用场景概述
主要新功能
主要新增功能
文档扫描与图像导入
图像预处理
文档分析
OCR 与其他识别技术
PDF 转换
高级开发工具
获取和导出识别文本
多 CPU 识别架构
优势
简要规格
快速入门
ABBYY FineReader Engine 术语表
在此页面
另请参阅
主要新功能
多 CPU 识别架构
复制页面
复制页面
本主题适用于 Windows 版 FRE。
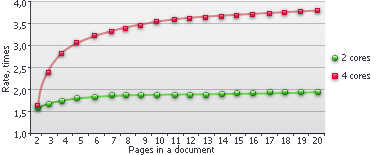
ABBYY FineReader Engine 会自动组合并执行页面分发、识别与合成协调等步骤。因此,它可以轻松扩展,并充分利用多核/多 CPU 硬件。与单核系统相比,每增加一个核心,速度最高可提升 90%。
此图未将文档导出步骤考虑在内,因为该步骤会因具体场景而异,且无法并行处理。速度提升幅度也可能因文档复杂度不同而有所差异。对于布局复杂的文档,提升更高;对于简单文档,提升较低。分析和识别所花费的时间越多,多进程带来的收益就越高。此图还表明,文档中的页面越多,负载均衡效果越好,性能提升也越明显。
上述数据基于 ABBYY 内部测试。
另请参阅
主要功能
此页面对您有帮助吗?
是
否
获取和导出识别文本
上一页
优势
下一页
⌘I
助手
AI生成的回答可能包含错误。