方法
字符
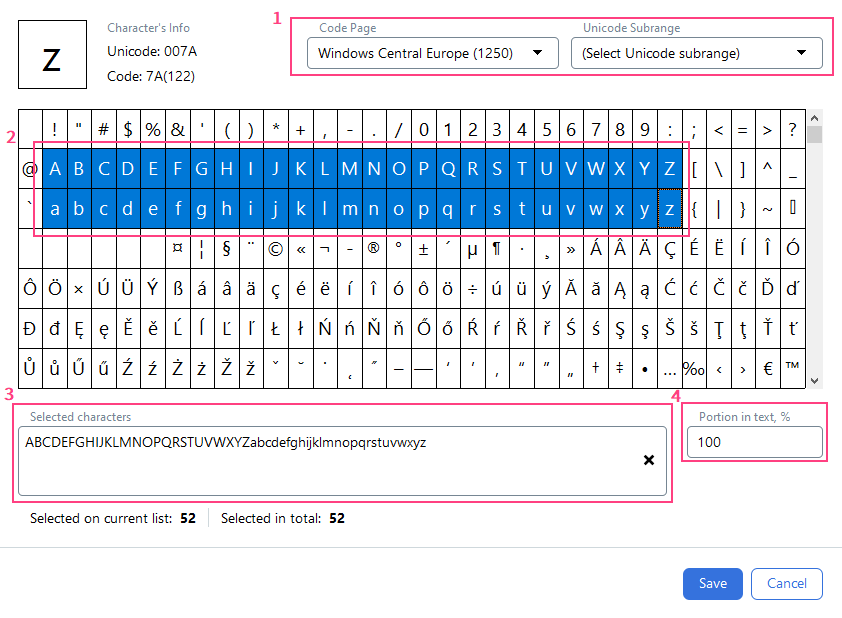
设置字符集
- 在 Code Page 字段或 Unicode Subrange 字段的下拉列表中选择适当的字符编码标准。
- 在下方的表格中选择相应的字符。
- 所选字符会显示在 Selected characters 字段中。您也可以使用键盘来指定字符集。
- 在
Portion in text, %字段中,指定要搜索的文本中此类字符所占的百分比 (从 0 到 100) 。
正则表达式
正则表达式字符集
| 列表中的名称 | 字段中符号 | 示例 | ||
|---|---|---|---|---|
| 任意单个字符 | * | “k”*“t” – 允许 ‘kit’、‘kat’ 等 | ||
| 字母 | C | C”at” – 允许 cat、bat、Rat、mat 等 | ||
| 大写字母 | A | A”at” – 允许 Cat、Bat、Rat、Mat 等 | ||
| 小写字母 | a | a”at” – 允许 car、bat、rat、mat 等 | ||
| 字母或数字 | X | X – 允许任意单个字母或数字 | ||
| 数字 | N | N”th” – 允许 5th、4th、6th 等 | ||
| 字符串 | "" | "cat” | ||
| 或 | ”dr”(“i" | "u”)“nk” – 允许 “drink” 或 “drunk” | ||
| 集合中的字符 | [] | [hm]“at” – 允许 ‘hat’ 或 ‘mat’ | ||
| 不在集合中的字符 | [^] | [^b]“at” – 允许 ‘cat’、‘mat’、‘rat’,但不允许 ‘bat’ | ||
| 任意次数重复 (应用于左侧表达式或子表达式) | {-} | [AB74]{-} – 允许任意长度、由 A、B、7、4 组成的任意组合 | ||
| 重复次数为 n | {n} | N{2}"th" – 允许 25th、84th、11th 等 | ||
| 重复 n 到 m 次 | {n-m} | N{1-3}"th" – 允许 5th、84th、111th 等 | ||
| 重复 0 到 n 次 | {-n} | N{-2}"th" – 允许 th、84th、4th 等 | ||
| 重复 n 次或更多次 | {n-} | N{2-}"th" – 允许 25th、834th、311th、34576th 等 | ||
| 子表达式 | () |
正则表达式示例
- 邮政编码:
[0-9]{6}示例值:“142172” - 美国邮政编码 (USA) :
[0-9]{5}("-"[0-9]{4}){-1}示例值:“55416”、“33701-4313” - 收入:N
{4-8}[,]N{2}示例值:“15000,00”、“4499,00” - 数字形式的月份:
((|"0")[1-9])|("10")|("11")|("12")示例值:“4”、“05”、“12” - 分数:
("-"|)([0-9]{1-})(|(("."| ",")([0-9]{1-})))示例值:“1234,567”、“0.99”、“100,0”、“-345.6788903” - 电子邮件:
[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-3}"@"[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-4}"."([A-Za-z]{2-4}|"asia"|"museum"|"travel"|"example"|"localhost")示例值:“support@abbyy.com”、“my-name@company.org.ru”、“info@gallery.museum”
扩展正则表达式
[% and %]) 。扩展正则表达式具有以下附加特性:
- 括号内的一个或多个字符会扩展为同时包含这些字符及其常见的 OCR 识别错误。例如,
[%S%]可以匹配 S、$ 和 5。 [%...%]内的特殊关键字用于表示常见字符集及其 OCR 识别错误:a. LETTERS - 大写拉丁字母以及通常会被识别为大写拉丁字母的字符;b. DIGITS - 数字以及通常会被识别为数字的字符;c. LETERSANDDIGITS - 大写拉丁字母、数字以及通常会被识别为大写拉丁字母和数字的字符。
[%DIGITS%]{9} 指定九个连续数字或数字的常见 OCR 识别错误,例如 “OI234Sb7B9”。
其他属性
- 允许错误 指定最大允许的识别错误率 (百分比) 。换句话说,它表示在全部字符中,最多有多少百分比的字符可以不在已定义的字符集中。仅当对象的识别错误率不高于指定值时,才能为该对象生成假设。
- 单词数量 指定要搜索的文本中单词数量的最小值和最大值。
- 字符数量 指定要搜索的文本中字符数量的最小值和最大值。
- 搜索单词的部分内容 指定在假设中是否允许包含单词片段。如果需要排除包含单词片段的假设并且只搜索完整单词,请禁用此选项。
高级属性
- Allow embedded hypotheses:允许使用搜索区域中的字符生成所有可能的假设——包括相交和嵌套的假设。
- Max. space length:允许指定在检测到的对象内部空格的最大长度。
- Text orientation:允许指定要查找的文本方向。默认情况下,该活动只查找水平方向的文本,不会针对旋转文本生成假设。如果需要查找以特定方式旋转的文本并忽略其他方向书写的文本,应仅选择 Clockwise 或 Counter-clockwise 选项。若要在不考虑方向的情况下查找文本,则应启用所有可用选项。
- Detect words by:指定应如何将行划分为单词:自动 (Pre-Recognition) ,或在相邻字符之间的空格大于或等于 Min. interword space 中输入的值时,通过将一行拆分为单词 (Interword Space) 。