Document Skill Designer 中的 Results 选项卡包含文档技能的字段提取统计信息。分析这些统计信息有助于了解如何提升提取数据的质量。
由技能提取的所有字段都会显示在 Fields 列中。属于字段组的字段会被归入以其字段组命名的可折叠下拉列表中。
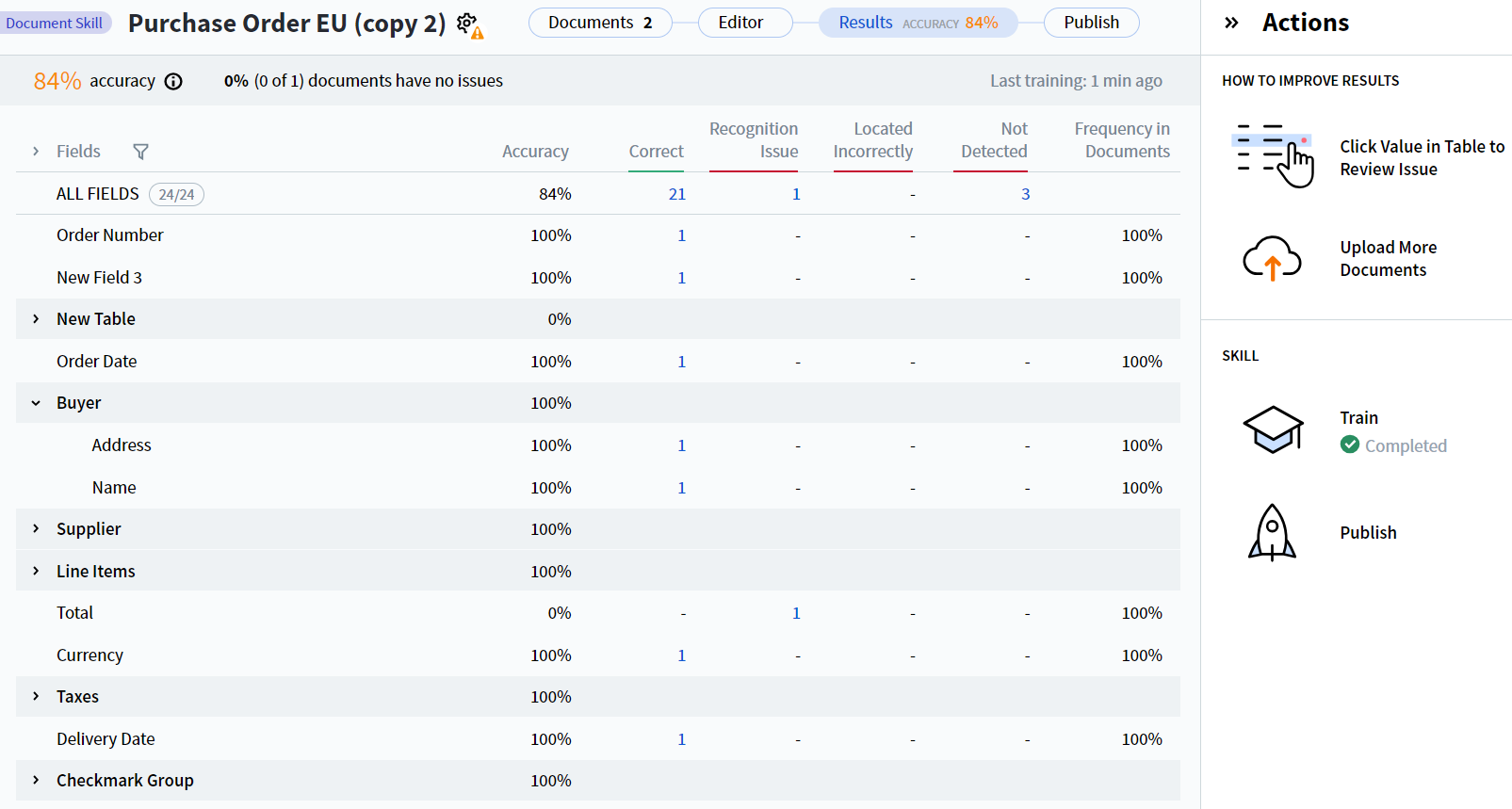 可用的字段提取统计信息包括:
可用的字段提取统计信息包括:
- Accuracy 列显示具有正确提取值的字段所占的百分比 (ALL FIELDS 行) ,以及各个字段的正确提取值百分比。
- 各个字段的准确率按以下公式计算:Accuracy = Correct / (Correct + Recognition Issue + Located Incorrectly + Not Detected)。
- ALL FIELDS 的准确率使用相同的公式计算,但分母中的数字是所有字段的汇总值。
- Correct 列显示提取值与参考值匹配的字段实例数量。
- Recognition Issue 列显示在文档中检测到但未被正确识别的字段实例数量。
- Located Incorrectly 列显示由于其区域检测位置与标注中指定位置不同,从而其值与预测值不一致的字段实例数量。
- Not Detected 列显示未检测到的字段实例数量。
- Frequency in Documents 列显示包含给定字段的文档所占的百分比。
默认情况下,这些统计信息会针对所有字段显示。您可以在列表中隐藏单个字段,仅查看所需字段的统计信息。为此,请单击 Fields 列顶部的过滤器图标,并选择所需字段。
- Reference 模式显示在设置技能时创建的参考标注 (即训练之前) ,以及使用该标注提取出的字段值。在此模式下可以编辑字段值和区域。
- Predicted 模式显示处理文档时获得的字段值和区域。在此模式下无法编辑字段值和区域。
- Difference 模式显示参考标注与预测标注之间的差异。相同的字段值和区域以绿色显示,不同的字段值和区域以红色显示。在此模式下无法编辑字段值和区域。
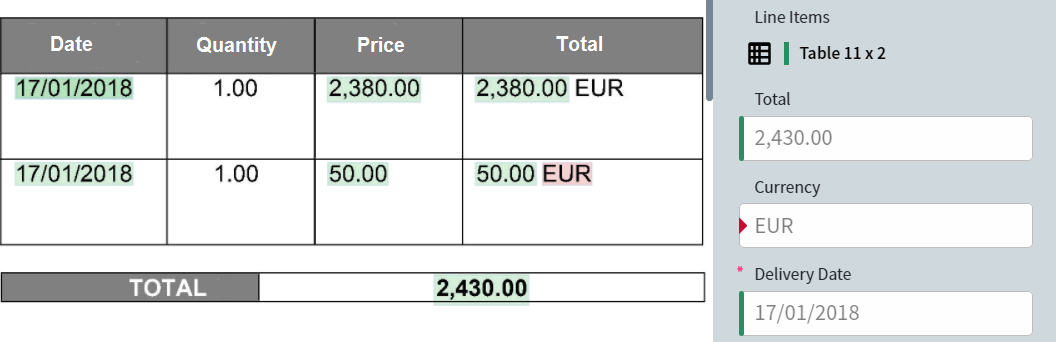 您可以通过点击工具栏上的相应选项卡在这三种模式之间切换。
如果在设置技能时对某个字段进行了错误标注,而在处理文档时获得了正确结果,您可以更正参考标注。为此,请切换到 Difference 模式,然后点击位于包含标注错误的字段值上方的图标:
您可以通过点击工具栏上的相应选项卡在这三种模式之间切换。
如果在设置技能时对某个字段进行了错误标注,而在处理文档时获得了正确结果,您可以更正参考标注。为此,请切换到 Difference 模式,然后点击位于包含标注错误的字段值上方的图标:
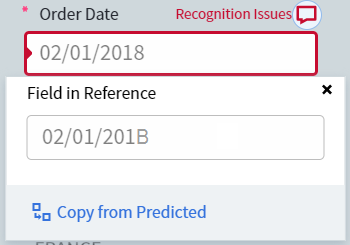 Field in Reference 框中将包含使用参考标注提取出的值。点击 Copy from Predicted,可将该错误值替换为处理文档时提取出的值。
Field in Reference 框中将包含使用参考标注提取出的值。点击 Copy from Predicted,可将该错误值替换为处理文档时提取出的值。
识别问题表示字段值中的一个或多个字符没有被正确识别。要修复此类错误,请修改字段的属性,使此类字符能够被正确识别。