| 此情境的結果是文件的可編輯版本。 在此情境中,系統會辨識文件影像並完整保留所有原始格式,再將資料儲存為可編輯的檔案格式。最終,您將獲得文件的可編輯版本,可輕鬆進行錯誤檢查與修改。 詳情請參閱文件轉換。 |
| 在此處理情境中,紙本文件會被轉換為不可編輯的數位副本,並以可搜尋的格式保存所有文件資訊。經過此類處理後,文件的數位副本可透過全文搜尋在電子檔案庫中輕鬆找到,文件文字片段可供複製,文件亦可透過電子郵件傳送或列印輸出。 詳情請參閱文件歸檔。 |
| 此情境用於從文件中擷取所有可能的資料,並以結構化方式儲存。 結果為一個代表文件結構的 JSON 檔案,其中儲存所有文件物件:印刷文字與手寫文字、表格、條碼、核取記號及影像,並包含其位置與屬性。此格式最適合用於後續處理、將資料儲存至資料庫,或與其他應用程式整合。 詳情請參閱資料提取。 |
| 此情境可提取文件的正文,以及標誌、印章及正文以外任何元素上的文字。 文字的自然閱讀順序 (即「人類閱讀的方式」) 將被保留。您可以將文件輸入至您端的自然語言處理 (NLP) 引擎,例如用於快速摘要、搜尋敏感資訊或進行情感分析。 詳情請參閱文字提取。 |
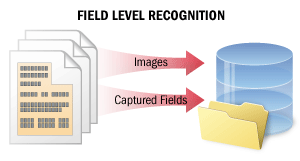
| 在欄位層級辨識的情況下,系統會辨識短文字片段,以從特定欄位擷取資料。辨識品質在此情境中至關重要。 此情境也可作為更複雜情境的一部分,用於從文件中擷取有意義的資料 (例如,將紙本文件的資料擷取至資訊系統與資料庫,或在文件管理系統中自動分類和索引文件) 。 在此情境中,系統可辨識部分欄位中的數行文字,或小型影像上的完整文字。系統會為每個已辨識的字元計算確信度評分,該評分可在核查辨識結果時使用。此外,系統可為文字中的單字和字元儲存多個辨識變體,這些變體可用於投票演算法以提升辨識品質。 詳情請參閱欄位層級辨識。 |
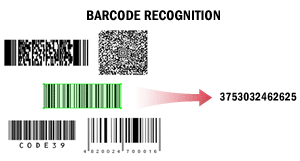
| 在此情境中,ABBYY FineReader Engine 用於讀取條碼。條碼的讀取可能有多種用途,例如自動文件分隔、透過文件管理系統處理文件,或對文件進行索引和分類。 此情境可作為其他情境的一部分使用。例如,以高速生產掃描器掃描的文件可透過條碼進行分隔,或準備長期儲存的文件可根據其條碼值歸入文件管理系統的歸檔庫。 從文字中提取條碼時,系統可偵測所有條碼,或僅偵測具有特定值的特定類型條碼。系統可取得條碼的值並計算其校驗碼。 已辨識的條碼值可儲存為最便於後續處理的格式,例如 TXT 格式。 詳情請參閱條碼辨識。 |
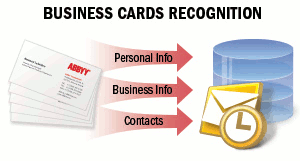
| 名片包含公司或個人的商業資訊,可包括姓名、公司名稱、電話號碼、傳真、電子郵件、網站地址及類似資訊。您可能需要從紙本名片擷取這些資訊並以電子格式儲存,例如儲存至手機電子通訊錄、電子郵件客戶端或任何其他資料儲存系統。例如,名片通常以 vCard 格式透過電子郵件或網路傳遞。 詳情請參閱名片辨識以取得詳細資訊。 |
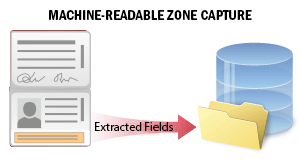
| 許多國家的官方旅行或身分證件均包含機器可讀區域 (MRZ) ,可確保更準確地處理文件資料。 此情境用於在客戶入職或驗證流程中,從身分證件的機器可讀區域擷取資料。系統會辨識文件影像上的 MRZ 並從中擷取資料。擷取的資料包含數個欄位,內含文件及其持有人的個人資訊 (文件類型與到期日、持有人的姓名等) 。您可以搜尋各欄位、驗證資料,並將其儲存至外部檔案以供後續處理。 請參閱機器可讀區域擷取以取得詳細資訊。 |
| 僅限 Windows。 在此情境中,ABBYY FineReader Engine 部署於「掃描電腦」上,負責掃描影像並將其儲存為檔案。 此情境可作為其他情境的一部分,用於文件處理的前置階段,即取得文件的電子版本以供後續處理。使用範例包括:掃描文件以供存檔、取得可編輯的文件版本,以及從文件中擷取有效資料。 紙本文件經掃描後,影像以電子格式儲存,生成高品質的印刷文件電子版本。 請參閱掃描以取得詳細資訊。 |
| 文件分類的目的是將文件歸入使用者定義的類別。您可能需要處理由多種類型文件組成的文件流,例如合約、發票、收據,並識別每份文件的類型,例如將文件排序至不同資料夾,或依類型重新命名。這些操作均可透過預先訓練的系統自動完成。 此情境的主要前提是您已知悉將要處理的文件類型。ABBYY FineReader Engine 可依文件外觀或內容進行分類。 請參閱文件分類以取得詳細資訊。 |
| 在處理紙本文件時,您需要找出並更正其中的錯誤或刻意進行的變更。 此情境用於將重要文件 (例如合約和銀行文件) 與其副本進行比對。比對結果包含內容類型差異 (僅限文字) 、修改類型 (刪除、插入或修改) 及其在原件與副本中的位置等資訊。您可以取得偵測到的差異清單或任何變更的區域,並將比對結果儲存至外部檔案以供後續處理或長期保存。 請參閱文件比對以取得詳細資訊。 |
總覽
基本使用案例概覽
本節說明 ABBYY FineReader Engine 最常見的使用案例。我們建議您在開始使用 ABBYY FineReader Engine 時,先選擇最適合您工作需求的案例。找到合適的案例後,您可以在 基本使用案例實作 章節中,查看該案例的詳細說明、實作建議,以及針對特定工作最佳化程式碼的建議。


基本使用案例實作