跳轉到主要內容
ABBYY Documentation home page
繁體中文
FineReader Engine
Search documentation...
⌘K
詢問AI
Website
Get Started
Get Started
搜尋...
Navigation
重要新功能
多 CPU 辨識架構
簡介
導覽指南
API 參考
視覺元件參考
授權
安裝
發行
規格
常見問題
版本說明
總覽
ABBYY FineReader Engine 12 簡介
基本使用案例概覽
重要新功能
重點新功能
文件掃描與影像匯入
影像預處理
文件分析
OCR 與其他辨識技術
PDF 轉換
進階開發工具
接收與匯出已辨識文字
多 CPU 辨識架構
優勢
簡要規格
開始使用
ABBYY FineReader Engine 術語表
在此頁
另請參閱
重要新功能
多 CPU 辨識架構
複製頁面
複製頁面
本主題適用於 Windows 版 FRE。
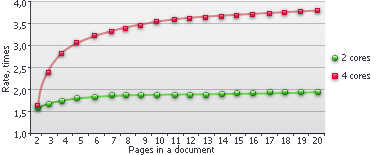
ABBYY FineReader Engine 會自動整合並執行頁面分派、協調辨識與合成等步驟。這可輕鬆實現可擴充性,並充分運用多核心/Core/CPU 硬體;相較於單核心系統,每增加一個核心,速度最高可提升 90%。
此圖未將文件匯出步驟納入考量,因為該步驟會因情境而異,且無法平行化。速度提升幅度也會因文件複雜度而有所不同。對於版面較複雜的文件,提升幅度較高;對於簡單文件,則較低。分析與辨識所花費的時間越多,多重處理帶來的效益就越高。此圖也顯示,文件中的頁面越多,負載平衡與效能表現就越好。
以上數據引自 ABBYY 內部測試。
另請參閱
主要功能
這個頁面有幫助嗎?
是
否
接收與匯出已辨識文字
上一頁
優勢
下一頁
⌘I
助手
AI生成的回答可能包含錯誤。