- Fichiers journaux de Vantage
- Le service Skill Monitor intégré, qui collecte des statistiques pour les Skills Vantage existants et fournit des informations détaillées sur les transactions terminées et en cours. Ce service vous permet également d’obtenir les informations sur les événements de transaction requises par le support technique.
- Des services tiers qui vous permettent de surveiller les processus internes de Vantage, de surveiller des workflows spécifiques, d’analyser les données collectées afin d’affiner et d’optimiser davantage le traitement de documents, ainsi que de collecter et d’analyser les journaux.
- Cliquez sur Help dans le volet de gauche, puis sur About, et sélectionnez Version details.
- Copiez les informations.
Comment accéder aux journaux de diagnostic
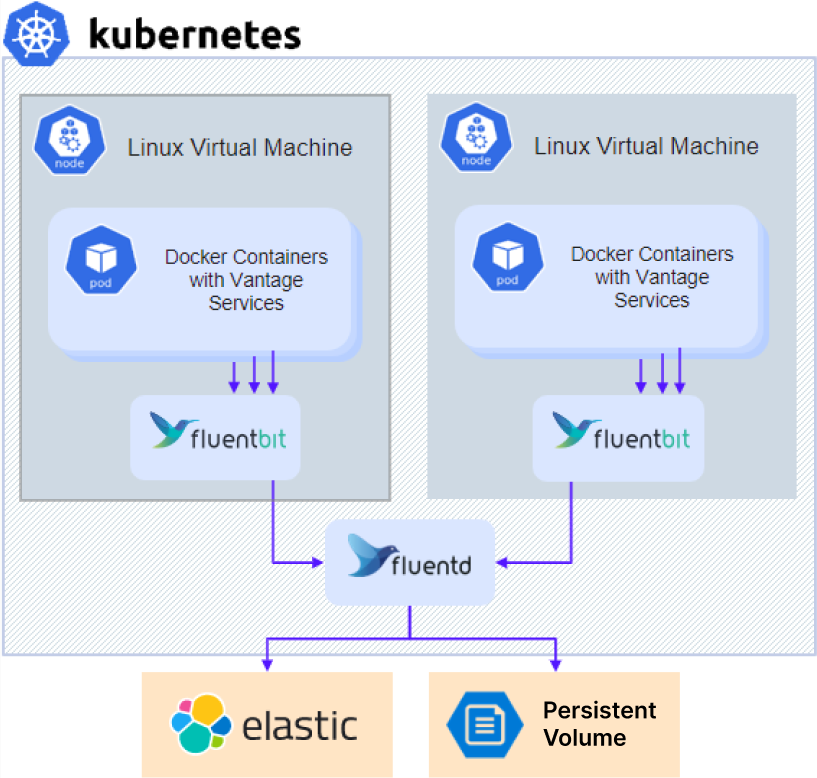
- Si vous utilisez un serveur NFS externe ou un autre type de stockage externe, passez directement à l’étape 3.
- Pour une installation avec un serveur NFS dans le cluster (configuration par défaut pour Sans haute disponibilité), récupérez l’adresse IP du serveur NFS :
- Accédez au partage :
- Pour NFS :
- Linux :
mount –t nfs <nfs server ip>:/ /opt/mount - Windows : installez Client for NFS, ouvrez l’Explorateur de fichiers et accédez à
\\<nfs server ip>
- Linux :
- Pour les autres types de stockage externe : contactez votre administrateur système pour obtenir les instructions d’accès.
- Pour NFS :
- Accédez au répertoire
\\<nfs server ip>\<sharename>\<env>\abbyy-monitoring\fluentd-pvc.
Fournir des journaux à l’assistance technique
- Accédez au dossier des journaux. Les journaux sont stockés dans des sous-dossiers qui portent les mêmes noms que les espaces de noms du cluster Kubernetes. Les journaux Vantage se trouvent dans le dossier
abbyy-vantage. - Copiez les fichiers correspondant à la période pendant laquelle le problème est survenu. Les journaux sont compressés au format gzip, avec des noms suivant le format
Y-M-DD-H(par exemple,2022-12-09-0800.log.gz). - Envoyez les fichiers à l’assistance technique ABBYY.
Elasticsearch et Kibana
La procédure de configuration d’exemple ci-dessous a été simplifiée et est fournie uniquement à titre d’illustration.
- Clonez le dépôt :
- Installez l’opérateur chargé de déployer les ressources :
- Créez un fichier nommé
elastic.yamlavec le contenu suivant :
- Créez un fichier nommé
kibana.yamlavec le contenu suivant :
- Exécutez la commande suivante pour installer Elasticsearch :
- Exécutez la commande suivante pour installer Kibana :
- Obtenir le mot de passe d’un utilisateur Elasticsearch :
- Ajoutez les Parameter suivants à votre fichier
env_specific.yaml:
- Si vous installez Kibana après l’installation du produit, mettez à jour votre fichier
env_specific.yamlet exécutez la commande suivante :
Grafana
Grafana doit être installé dans le cluster, car Prometheus n’est disponible qu’à l’intérieur d’un cluster.
La procédure de configuration ci-dessous a été simplifiée et est fournie uniquement à titre d’illustration.
- Créez un fichier nommé
grafana.yaml. - Copiez et collez le code suivant dans le fichier, puis enregistrez-le :
Remplacez la valeur du Parameter host par le nom de domaine de votre cluster Vantage, puis modifiez le mot de passe de l’administrateur initial.
- Exécutez les commandes suivantes :