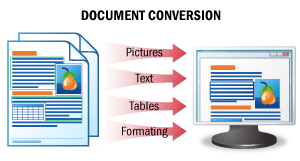
| Il risultato di questo scenario è una versione modificabile di un documento. In questo scenario, le immagini dei documenti vengono riconosciute mantenendo intatta la formattazione originale e i dati vengono salvati in un formato di file modificabile. Il risultato sono versioni modificabili dei documenti, che possono essere facilmente verificate per individuare errori e corrette. Per i dettagli, vedereDocument Conversion. |
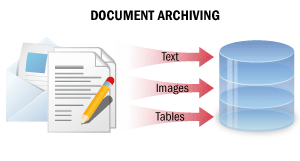
| In questo scenario di elaborazione, i documenti cartacei vengono convertiti in copie digitali non modificabili contenenti tutte le informazioni del documento in un formato ricercabile. Grazie a questa elaborazione, le copie digitali dei documenti possono essere facilmente trovate in un archivio elettronico tramite ricerca full-text, i segmenti di testo possono essere copiati e i documenti possono essere inviati via e-mail o stampati. Per i dettagli, vedereDocument Archiving. |
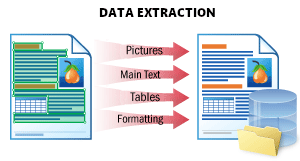
| Questo scenario viene utilizzato per estrarre tutti i dati possibili da un documento e archiviarli in modo strutturato. Il risultato è un file JSON che rappresenta la struttura del documento. Contiene tutti gli oggetti del documento: testo stampato e testo scritto a mano, tabelle, barcode, segni di spunta e immagini con la relativa posizione e i relativi attributi. Questo formato è ottimale per l’elaborazione successiva, l’archiviazione dei dati in un database o l’integrazione con un’altra applicazione. Per i dettagli, vedereData Extraction. |
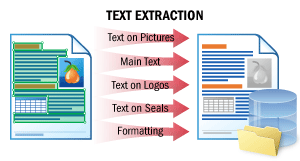
| Questo scenario consente di estrarre il testo principale di un documento e i testi presenti su loghi, timbri e qualsiasi altro elemento diverso dal testo principale. Viene preservato l’ordine naturale del testo “così come lo leggerebbe un essere umano”. È quindi possibile inviare i documenti ai motori di elaborazione del linguaggio naturale (NLP) disponibili, ad esempio per generare un riepilogo rapido, ricercare informazioni sensibili o eseguire un’analisi del sentiment. Per i dettagli, vedereText Extraction. |
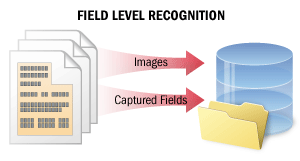
| Nel caso del riconoscimento a livello di field, brevi frammenti di testo vengono riconosciuti per acquisire dati da determinati field. La qualità del riconoscimento è fondamentale in questo scenario. Questo scenario può essere utilizzato anche nell’ambito di scenari più complessi in cui è necessario estrarre dati significativi dai documenti (ad esempio, per acquisire dati da documenti cartacei in sistemi informativi e database, oppure per classificare e indicizzare automaticamente i documenti nei sistemi di gestione documentale). In questo scenario, il sistema riconosce alcune righe di testo solo in determinati field oppure l’intero testo su un’immagine di piccole dimensioni. Il sistema calcola un indice di certezza per ogni carattere riconosciuto. Tali indici possono quindi essere utilizzati durante la verifica dei risultati del riconoscimento. Inoltre, il sistema può memorizzare più varianti di riconoscimento per le parole e i caratteri nel testo, che possono poi essere impiegate in algoritmi di votazione per migliorare la qualità del riconoscimento. Per i dettagli, vedereField-Level Recognition. |
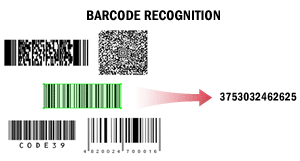
| In questo scenario, ABBYY FineReader Engine viene utilizzato per leggere i barcode. La lettura dei barcode può essere necessaria, ad esempio, per la separazione automatica dei documenti, per l’elaborazione dei documenti da parte di un sistema di gestione documentale o per l’indicizzazione e la classificazione dei documenti. Questo scenario può essere utilizzato nell’ambito di altri scenari. Ad esempio, i documenti acquisiti con scanner di produzione ad alta velocità possono essere separati tramite barcode, oppure i documenti predisposti per l’archiviazione a lungo termine possono essere inseriti in sistemi di gestione documentale per l’archiviazione in base ai valori dei rispettivi barcode. Durante l’estrazione dei barcode dai testi, il sistema può rilevare tutti i barcode oppure solo i barcode di un determinato tipo con un determinato valore. Il sistema può ottenere il valore di un barcode e calcolarne il checksum. I valori dei barcode riconosciuti possono essere salvati nei formati più adatti all’elaborazione successiva, ad esempio in formato TXT. Per i dettagli, vedereRiconoscimento dei barcode. |
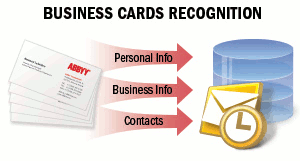
| I biglietti da visita contengono informazioni professionali relative a un’azienda o a una persona e possono includere il nome, l’azienda, i numeri di telefono, il fax, l’e-mail, gli indirizzi dei siti web e informazioni simili. Potrebbe essere necessario acquisire queste informazioni da biglietti da visita cartacei e salvarle in formato elettronico, ad esempio in una rubrica elettronica di un telefono cellulare, in un client di posta elettronica o in qualsiasi altro sistema di archiviazione dati. I biglietti da visita vengono spesso condivisi via e-mail o in rete in formato vCard. Per i dettagli, vedereBusiness Cards Recognitionfor details. |
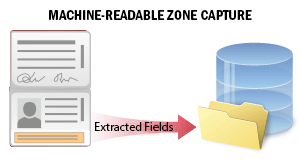
| The official travel or identity documents of many countries contain a machine-readable zone (MRZ) that ensures more accurate processing of the document data. Questo scenario viene utilizzato per estrarre dati da una zona leggibile meccanicamente su documenti d’identità durante i processi di onboarding o verifica dei clienti. Il sistema riconosce l’MRZ sull’immagine del documento ed estrae i dati da essa. I dati estratti contengono diversi field con le informazioni personali relative al documento e al suo titolare (tipo di documento e data di scadenza, nome e cognome del titolare del documento, ecc.). È possibile cercare tra i field, verificare i dati e salvarli in un file esterno per ulteriori elaborazioni. SeeMachine-Readable Zone Capturefor details. |
| Windows only. In this scenario, ABBYY FineReader Engine is used on a “scanning computer,” which scans images and saves them as files. This scenario may be used as part of other scenarios in the preliminary stage of document processing, i.e., for obtaining electronic versions of documents for further processing. Usage examples include scanning documents for archiving purposes, getting editable versions of documents, and extracting meaningful data from documents. Paper documents are scanned and the images are saved in an electronic format, producing high-quality electronic versions of your printed documents. SeeScanningfor details. |
| The task of document classification is to assign a document to one of the user-defined categories. You may have to deal with a document flow which consists of documents of several types, for example, contracts, invoices, receipts. You need to identify the type of each document. For example, you want to sort the documents into different folders, or rename them according to their types. This can be done automatically with a pretrained system. The main aspect of this scenario is that you know which types of documents you are going to process. ABBYY FineReader Engine can classify documents by their appearance or by their content. SeeDocument Classificationfor details. |
| When working with the paper documents, you need to find and correct the mistakes or intentionally made changes. This scenario is used to compare the documents of special importance, such as contracts and bank documentation, with their copies. The comparison result contains the information about differences in the type of content (text only), kind of modification (deleted, inserted, or modified) and their locations in the original and the copy. You may get the list of the detected differences or the region of any change and save the comparison result to an external file for further processing or long-term storage. SeeDocument Comparisonfor details. |
Panoramica
Panoramica degli scenari di utilizzo di base
Questa sezione descrive gli scenari più comuni in cui è possibile utilizzare ABBYY FineReader Engine. Si consiglia di iniziare a lavorare con ABBYY FineReader Engine selezionando lo scenario più adatto alle proprie esigenze. Una volta individuato lo scenario appropriato, nella sezione Implementazione degli scenari di utilizzo di base è possibile trovare una descrizione dettagliata dello scenario, consigli sull’implementazione e suggerimenti per ottimizzare il codice per attività specifiche.


Implementazione degli scenari di utilizzo di base