Trovare l’ultima occorrenza di un’entità denominata
Regola per estrarre l’ultima occorrenza dell’organizzazione
Esempio
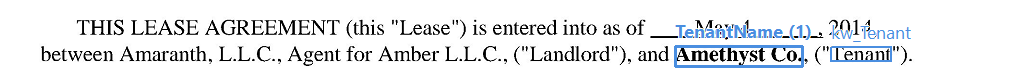
Estrazione di un importo indicato sia in lettere sia in cifre
Regola per l’estrazione di un importo di denaro
Esempio

Trovare segmenti tramite parole chiave
Regola per estrarre i titoli di secondo livello nell’elemento di ricerca kw_Heading2
Regola per estrarre il segmento nell’elemento di ricerca Segment
Esempio

kw_Heading2, quindi il testo compreso tra due istanze consecutive dell’elemento di ricerca kw_Heading2 viene estratto in un’istanza dell’elemento di ricerca Segment.
Raggruppare le informazioni su ciascuna entità
- Cercare i nomi delle organizzazioni, creare una nuova istanza dell’elemento di ricerca di gruppo
Party_Groupper ciascun nome trovato e valorizzare il relativo elemento di ricerca figlio denominato “Organization_Name.” - Cercare l’indirizzo e il ruolo che siano distanti non più di, diciamo, 20 token da ciascuna istanza del nome dell’organizzazione, accedere all’istanza di
Party_Groupche è il genitore del nome dell’organizzazione e valorizzare gli elementi di ricerca figli denominati “Address” e “Role” in quella istanza.
Regola per l’estrazione dell’elemento di ricerca Organization_Name
Regola per l’estrazione dell’elemento di ricerca Address
Regola per l’estrazione dell’elemento di ricerca “Role”
Esempio


Trovare data e ora insieme
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?). Successivamente, cerchiamo un’entità denominata Date situata nelle vicinanze. Infine, concateniamo le sequenze di token trovate e assegniamo il risultato a un elemento di ricerca denominato “TimeAndDate”.
Regola per l’estrazione combinata di data e ora
Esempio
