이 객체는 단어를 나타냅니다. 단어 컬렉션(Words 객체)의 요소입니다.
이 객체가 나타내는 단어는 내부적으로 사용되는 엔터티라는 점에 유의하세요. 따라서 자연어에서 일반적으로 의미하는 단어, 정규식으로 정의된 단어, 또는 공백으로 다른 단어와 구분되는 문자열과 일치한다고 보장할 수는 없습니다. Word 객체의 주된 목적은 해당 단어에 대한 인식 후보를 제공하는 것입니다. 인식된 텍스트를 다뤄야 하는 경우에는 다른 객체의 속성(예: IParagraph::Text)을 사용하세요.
위 내용은 특히 텍스트가 중국어, 일본어 또는 한국어로 작성된 경우에 해당합니다. 이러한 언어에서 “단어”는 순전히 기술적인 목적에 따라 구분되며 실제 단어와는 일치하지 않습니다.
손글씨/정자체 텍스트 인식에서는 Voting API를 사용할 수 없습니다.
| 이름 | 유형 | 설명 |
|---|
| Application | Engine, 읽기 전용 | Engine 객체를 반환합니다. |
| FirstSymbolPosition | int, 읽기 전용 | 단어의 첫 번째 문자의 인덱스를 반환합니다. 인덱스는 문단 내 문자 위치이며, 0부터 IParagraph::Length 속성 값에서 1을 뺀 값까지의 범위일 수 있습니다. |
| IsWordFromDictionary | VARIANT_BOOL, 읽기 전용 | 단어를 사전에서 찾았는지 여부를 지정합니다. |
| ModelType | WordModelTypeEnum, 읽기 전용 | 단어를 분리할 때 적용된 모델 유형을 반환합니다. <Note> 문서를 인식할 때 모델 유형 적용 여부는 선택한 문서 내용 재사용 모드에 따라 달라집니다(자세한 내용은 SourceContentReuseModeEnum 참조). </Note> |
| Region | Region, 읽기 전용 | 단어를 포함하는 영역에 액세스할 수 있습니다. 이 영역의 BoundingRectangle 속성을 사용하여 단어의 사각형을 가져옵니다. 영역 좌표(픽셀 단위)는 이미지의 왼쪽 위 모서리를 기준으로 합니다. |
| Text | BSTR, 읽기 전용 | 단어를 있는 그대로 반환합니다. <Note> IParagraph::Text 속성과 달리, 문단의 쓰기 방향이 오른쪽에서 왼쪽(예: 히브리어)인 경우 문단의 단어는 해당 단어의 문자를 왼쪽에서 오른쪽 순서로 포함하는 string입니다. 예를 들어, 히브리어 단어 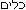 는 string ""로 반환됩니다. </Note> 는 string ""로 반환됩니다. </Note> |
| 이름 | 설명 |
|---|
| GetRecognitionVariants | 단어 인식 결과의 여러 변형을 모아 반환합니다. |
 객체 다이어그램
이 객체는 Words 객체의 Item 메서드에서 반환되는 출력 매개변수입니다.
이 객체는 다음 코드 샘플에서 사용됩니다.
Linux: CustomLanguage
Windows: CustomLanguage, RecognizedTextProcessing
텍스트 다루기
Words
속성 다루기
객체 다이어그램
이 객체는 Words 객체의 Item 메서드에서 반환되는 출력 매개변수입니다.
이 객체는 다음 코드 샘플에서 사용됩니다.
Linux: CustomLanguage
Windows: CustomLanguage, RecognizedTextProcessing
텍스트 다루기
Words
속성 다루기