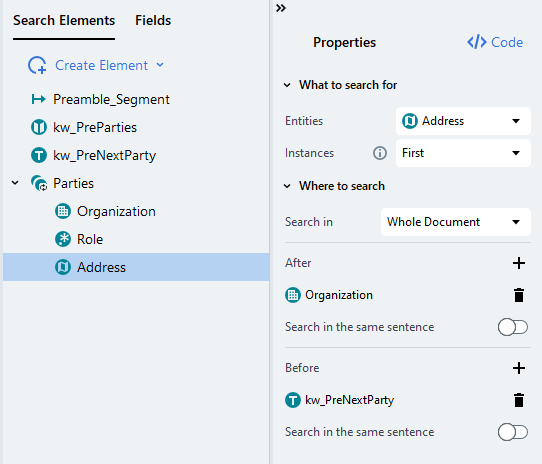
// Check that the Address search element hasn't been found yet, because we need only the first instance
~Parties.Address,
// Get the Organization search element and the next party keyword search element. They were found before Address
t1 : Parties.Organization,
t2 : kw_PreNextParty
// NERAddress 명명된 엔티티 하나를 포함하는 토큰 시퀀스를 찾습니다
// ("same" 키워드는 여러 개가 있을 경우 하나의 NERAddress만 일치시켜야 함을 지정합니다)
// 주소는 조직 이름 뒤, 다음 당사자 키워드 앞에 위치해야 합니다
// + 기호는 토큰 시퀀스가 여러 단어로 구성될 수 있음을 의미합니다
// 끝에 있는 ~@Parties.Address 조건은
// 주소가 동일한 토큰에서 다시 일치되지 않도록 보장합니다
[ t: @NERAddress( same, right_to( t1 ), left_to( t2 ) ) ~@Parties.Address ]+
=>
Parties.Address( t );