명명된 개체의 마지막 인스턴스 찾기
마지막 조직 엔터티 인스턴스를 추출하는 규칙
예제
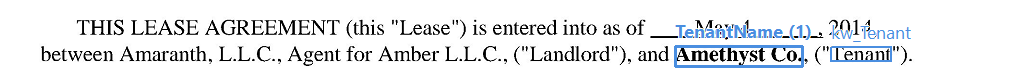
글과 숫자로 모두 표기된 금액 추출하기
금액 추출 규칙
예시

키워드를 이용한 세그먼트 찾기
2단계 제목을 kw_Heading2 검색 요소로 추출하기 위한 규칙
Segment search 요소로 세그먼트를 추출하는 규칙
예시

kw_Heading2 검색 요소로 추출된 다음, 서로 연속된 두 kw_Heading2 검색 요소 인스턴스 사이에 있는 텍스트가 Segment 검색 요소의 인스턴스로 추출됩니다.
각 엔티티에 대한 정보 그룹화
- 조직 이름을 찾고, 발견된 각 이름에 대해
Party_Group그룹 search element의 새 인스턴스를 생성한 다음, “Organization_Name”이라는 이름의 자식 search element를 채웁니다. - 각 조직 이름 인스턴스로부터, 예를 들어 최대 20개의 토큰 이내에 있는 주소와 역할을 찾고, 해당 조직 이름의 부모인
Party_Group인스턴스에 접근하여 그 인스턴스의 “Address” 및 “Role”이라는 이름의 자식 search element를 채웁니다.
Organization_Name 검색 요소 추출 규칙
Address 검색 요소 추출 규칙
Role 검색 요소 추출 규칙
예시
검색 요소는 다음과 같이 추출됩니다.

날짜와 시간을 함께 찾기
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?입니다). 다음으로, 그 근처에 위치한 Date라는 명명된 엔터티(named entity)를 찾습니다. 마지막으로, 찾아낸 토큰 시퀀스를 연결(concatenate)하여 결과를 “TimeAndDate”라는 검색 요소에 할당합니다.
날짜와 시간을 함께 추출하기 위한 규칙
예시
