시작하기 전에
- Activity Editor에서 “Sick Note DE” 액티비티를 엽니다.
- 문서 세트에서 문서 하나를 선택합니다.
- 요소 속성의 고급 모드가 활성화되어 있는지 확인합니다. 이 모드를 켜거나 끄려면 Properties 창에서 아이콘을 클릭합니다.
- 업로드된 모든 문서는 사전 인식을 거쳤으며, 이미지에서 어떤 객체가 발견되었는지 확인해 두는 것이 좋습니다. 아이콘을 클릭합니다. 화면 크기 때문에 이 아이콘이 보이지 않으면 아이콘을 클릭하고 Recognized Words를 선택합니다. 해당 객체가 문서 이미지에 강조 표시됩니다. 언제든지 다양한 강조 표시 객체 유형 사이를 전환할 수 있습니다. 예를 들어 단락을 찾을 때는 Recognized Lines로 전환하는 것이 도움이 될 수 있으며, Separators로 전환하면 Separator 검색 요소를 더 쉽게 구성할 수 있습니다.
- 검색 요소가 검색 영역 밖에 있으면 찾을 수 없습니다. 문서 이미지 컨텍스트 메뉴에서 Show search area 옵션을 활성화합니다. 각 요소의 검색 영역은 매칭 결과를 평가할 때 녹색으로 강조 표시됩니다.
환자 데이터 추출하기
- Create Element를 클릭하고 드롭다운 목록에서 Group 요소를 선택합니다. 이름을 “PatientDataArea”로 변경합니다.
- 새 그룹 검색 요소는 기본적으로 필수로 설정됩니다. 필수 요소를 찾지 못하면 Activity Editor에서 오류가 발생하고 매칭이 중단됩니다. 이 방식은 특정 문서에 적합하지 않은 액티비티를 건너뛸 수 있게 해 줍니다. 그러나 이 튜토리얼에서는 모든 수신 문서에서 데이터를 추출하는 액티비티를 만들고 있으므로 그룹을 선택 사항으로 설정해야 합니다. Under what conditions 섹션에서 Element is 값을 Optional로 변경합니다.
- 환자의 이름과 주소가 포함된 단락을 찾아 추출하려고 합니다. 독일어 문서에서 우리가 찾는 단락은 항상 “Name, Vorname … “라는 레이블이 붙은 field에 있습니다. 이 텍스트를 문서에서 찾아 추출하려는 데이터를 검색하기 위한 기준점으로 사용해야 합니다.
a. 키워드는 Static Text 검색 요소를 사용하여 찾을 수 있습니다. Create Element를 클릭하고 드롭다운 목록에서 Static Text 요소를 선택합니다. 이름을 “kwPatientTitle”로 변경합니다.
b. Properties 창의 Text to find field에 “Name, Vorname” 텍스트를 입력합니다.
c. Match를 클릭합니다. 처리가 완료되면 문서 아래에 Tree of Hypotheses가 표시됩니다. Advanced Designer가 원하는 정적 텍스트를 성공적으로 찾았는지 확인합니다. 요소 이름 옆의 초록색 점은 해당 요소가 문서에서 성공적으로 검색되었음을 나타냅니다. Tree of Hypotheses에서 요소 이름을 클릭하면 문서에서 해당 영역 주위에 보라색 프레임이 표시됩니다.
요소를 찾지 못한 경우 이름 옆에 주황색 점이 표시되고 문서 이미지 주위에는 주황색 프레임이 표시됩니다. 요소의 가설 품질은 체인에 있는 이후 요소들의 상태와 체인 전체의 품질에 영향을 미친다는 점을 기억하십시오. 가설 품질에 대한 자세한 정보는 설명서에서 확인할 수 있습니다.
- 이제 환자의 이름과 주소가 포함된 셀의 하단 경계를 찾아보겠습니다. 이를 위해 Separator 요소를 사용합니다.
a. 그룹에 Separator 요소를 추가하고 이름을 “SeparatorBottom”으로 지정합니다. 최소 길이는 200으로 설정합니다.
b. 해당 요소를 마우스 오른쪽 버튼으로 클릭하고 컨텍스트 메뉴에서 Match Element를 선택합니다. 그러면 Tree of Hypotheses에 많은 초록색 점이 표시됩니다. 이 점들은 검색 조건에 맞는 서로 다른 separator에 해당합니다. 각 점을 클릭하여 이미지에서 해당 객체를 확인할 수 있습니다.
c. 검색 조건을 더 좁히기 위해 separator의 검색 영역을 지정합니다. Match를 클릭하여 앵커 요소로 사용할 “kwPatientTitle” 요소를 찾습니다. Properties 창의 Where to search 섹션에서 Draw on Image를 클릭합니다. 문서에서 “kwPatientTitle” 요소를 선택한 다음 아래쪽 화살표 아이콘을 클릭하여 키워드 아래쪽의 검색 영역을 지정하고, 키워드에 가장 가까운 separator를 찾을 수 있도록 가장 가까운 아이콘을 선택합니다. 앵커 요소에 대한 자세한 설명은 설명서에서 확인할 수 있습니다.
d. Match를 클릭하고 Advanced Designer가 “kwPatientTitle” 요소 아래에서 separator를 찾았는지 확인합니다. Tree of Hypotheses 섹션에서 각 요소 이름을 클릭하여 해당 요소의 가설을 확인할 수 있습니다. - 레이블과 separator는 환자 데이터에 대한 신뢰할 수 있는 기준 요소입니다. 하지만 인쇄 품질이 너무 낮으면 레이블 텍스트가 인식되지 않거나 separator를 찾지 못할 수 있습니다. 좋은 추출 결과를 보장하기 위해 레이블과 separator 사이에 있는 단락을 검색하겠습니다. 단락은 균일한 텍스트 블록이므로 일부 경계 요소를 찾지 못했더라도 성공적으로 찾을 수 있습니다.
a. Paragraph 검색 요소를 만들고 이름을 “NameAddressParagraph”로 지정합니다.
b. Text alignment를 Left로 변경합니다.
c. 환자 데이터는 2줄에서 5줄까지 차지하므로 Line count를 2에서 5로 지정합니다.
d. 단락의 검색 영역을 지정합니다. 이번에는 Where to search 섹션에서 Add 메뉴를 사용해야 합니다. 요소는 “kwPatientTitle” 요소 아래에 있고 “SeparatorBottom” 요소 위에 위치해야 합니다.
e. Match를 클릭합니다. - 이제 환자 데이터를 추출해 보겠습니다. “PatientGroup”이라는 새 그룹 요소를 만듭니다.
- 환자의 이름은 한 줄 또는 두 줄을 차지할 수 있습니다. 요소의 여러 인스턴스를 캡처하기 위해 반복 그룹을 사용하겠습니다.
a. 반복 그룹 검색 요소를 만들고 이름을 “NameGroup”으로 지정합니다. 최대 반복 횟수를 2로 지정합니다. 요소는 선택 사항으로 설정합니다.
b. “NameAddressParagraph” 단락의 일부인 줄을 검색하려고 합니다. 요소의 영역을 검색 영역으로 지정하려면 문서 이미지 아래의 코드 편집기 아이콘을 클릭하고 Code Editor의 Search Conditions 섹션에 다음 스크립트를 붙여 넣습니다:
d. 찾으려는 텍스트에는 대문자와 소문자, 그리고 이름에 사용될 수 있는 여러 문장 부호가 포함될 수 있습니다. 두 개의 별도 문자 집합을 구성합니다. 첫 번째 집합에는 모든 라틴 대문자와 소문자가 포함되어야 합니다. 발음 구별 부호가 있는 문자를 추가하려면 Unicode 하위 범위를 변경하거나 해당 문자를 Selected characters field에 직접 붙여 넣습니다.
e. 다른 집합에는 다음 문장 부호가 포함되어야 합니다: ,-.()’. 문자열이 문장 부호로만 구성되지 않도록 두 번째 집합의 Portion in text, % 값을 40%로 설정합니다. 이 속성은 특정 집합의 문자에 대해 허용되는 최대 비율을 정의합니다.
기본 설정에서는 어떤 집합에도 포함되지 않은 문자가 문자열의 최대 30%까지 포함될 수 있습니다. 이는 일부 문자가 잘못 인식되었거나 집합에 포함되지 않은 경우(예: 발음 구별 부호가 있는 문자)에도 문자열을 찾는 데 도움이 됩니다. 이 설정은 Properties 창에서 Allowed errors 값을 변경하여 조정할 수 있습니다.
g. “NameLine” 요소의 검색 영역을 지정합니다. “kwPatientTitle” 요소 아래쪽이면서 그 요소에 가장 가까운 영역으로 설정합니다.
h. Match를 클릭하고 Tree of Hypotheses를 확인합니다. 두 개의 문자열이 검색된 것을 볼 수 있습니다. 하지만 두 번째 문자열에는 환자의 주소가 포함되어 있습니다.
i. 검색 결과에서 주소를 제외하기 위해 첫 번째 문자열에 이름과 성이 모두 포함되어 있는지 확인합니다. 이는 간단한 스크립트 검색 조건을 추가하여 수행할 수 있습니다. “NameLine” 검색 요소를 선택하고 Search Conditions 코드 편집기를 엽니다.
j. 첫 번째 줄에 쉼표와 공백이 포함되어 있다면 전체 이름이 포함되어 있다고 가정합니다. 전체 이름이 포함되어 있다면 반복 그룹의 두 번째 인스턴스를 더 이상 검색하지 않으려 합니다. 다음 스크립트를 편집기에 붙여 넣습니다:
- 7단계에서 추출한 환자 이름은 “Name” field에 매핑됩니다. 환자의 주소도 추출하여 매핑하겠습니다.
a. “PatientGroup” 안에서 “NameLine” 요소와 동일한 문자 집합 구성을 사용하는 Character String 검색 요소를 만들고 이름을 “Address”로 지정합니다.
b. 코드를 사용하여 요소의 검색 영역을 지정합니다. 주소는 “NameLine” 아래에 있거나, 이 요소를 찾지 못한 경우 “NameAddressParagraph” 요소의 첫 번째 줄 아래에 있어야 합니다.
d. Match를 클릭합니다. 검색 요소 구조는 다음과 같아야 합니다:
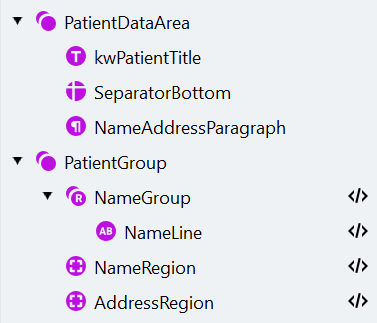
- Manage Fields 대화 상자를 열고 해당 field를 생성한 다음 다음과 같이 검색 요소에 매핑합니다:
| Name | Type | Search element |
|---|---|---|
| Name | ”Patient” 그룹의 Text field | NameLine |
| Address | ”Patient” 그룹의 Text field | Address |
- 새 field에 대해 자동으로 생성된 검색 요소를 삭제합니다.
병가 진단서 유형 추출하기
- “TypeOfSickNoteGroup”라는 이름의 Group 요소를 만듭니다. 이 요소는 선택 사항으로 설정합니다.
- 두 체크 표시 모두에 대한 정보를 저장하려면 Repeating Group 검색 요소를 만들고 “PrimaryGroup”이라고 이름을 지정합니다.
a. 좋은 방법은 요소 그룹의 검색 영역을 제한하는 것입니다. 코드로 검색 영역을 지정하여 “PatientGroup” 요소의 오른쪽, 그리고 (나중에 생성될) “DoctorAreaGroup” 요소의 위쪽으로 설정합니다. **Note: **나중에 정의될 요소를 사용할 때는 항상 “Exists” 조건을 지정해야 합니다.
c. 다음 설정으로 “Checkmark”라는 이름의 Object Collection 검색 요소를 생성합니다: Type:
Checkmark, Checkmark state: Checked, Minimum height: 10, Maximum width: 20, Maximum height: 20. 이 요소가 “kwPrimary” 요소의 왼쪽에 있고 그 요소에 가장 가까운 위치에 있도록 지정합니다. d. Match를 클릭합니다.
- “PrimaryGroup” 그룹을 복사하여 붙여 넣습니다. 복사한 그룹의 이름을 “SecondaryGroup”으로 변경합니다. 이 그룹은 필수입니다.
- “SecondaryGroup”을 편집합니다.
a. “kwPrimary” 요소의 이름을 “kwSecondary”로 변경하고 찾을 텍스트를 “Folgebescheinigung”으로 설정합니다. 검색 영역은 “PrimaryGroup”의 “kwPrimary” 요소 아래로 지정합니다.
b. “Checkmark” 요소의 검색 영역을 지정합니다. “kwSecondary”의 왼쪽이면서 그 요소에 가장 가까운 위치로 설정합니다.
c. Object Collection 검색 요소는 검색 영역 내의 모든 적합한 객체 컬렉션을 찾습니다. 체크 표시가 같은 줄에 있는 경우 “SecondaryGroup”의 “Checkmark” 요소가 기본 체크 표시도 함께 찾을 수 있습니다. 이를 방지하려면 “SecondaryGroup”의 “Checkmark” 요소에 대한 검색 영역에서 기본 체크 표시(“PrimaryGroup”의 “Checkmark” 요소)를 제외합니다.
d. Match를 클릭합니다.
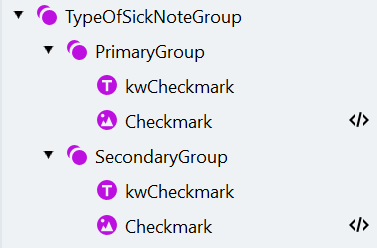
- Manage Fields 창을 열고 해당 field를 생성한 다음 다음과 같이 검색 요소에 매핑합니다:
| Name | Type | Search element |
|---|---|---|
| Type of Sick Note | Checkmark group | |
| Primary | ”Type of Sick Note” checkmark group의 Checkmark | PrimaryGroup -> Checkmark |
| Secondary | ”Type of Sick Note” checkmark group의 Checkmark | SecondaryGroup -> Checkmark |
- 새 field에 대해 자동으로 생성된 검색 요소를 삭제합니다.
의사 데이터 추출하기
- “DoctorAreaGroup”이라는 이름의 Group 요소를 생성합니다. 이 요소는 선택 사항으로 설정합니다.
- 우리가 찾을 상자에는 레이블이 들어 있습니다. 이를 찾기 위해 “kwDoctorTitle”이라는 이름의 Static Text 요소를 생성합니다(찾을 텍스트: “Unterschrift des Arztes”).
- “DoctorAreaGroup” 그룹 안에 “DataArea”라는 또 다른 그룹을 생성합니다.
- 의사 정보와 서명이 들어 있는 상자는 네 개의 Separator 조합으로 이루어져 있습니다. 이들은 “kwDoctorTitle” 요소 주변에 위치합니다. 하지만 “kwDoctorTitle” 요소를 찾지 못한 경우에도 프로그램이 이 요소들을 찾을 수 있도록 요소를 구성해야 합니다. “DataArea” 그룹에서 다음 속성으로 네 개의 Separator 검색 요소를 생성합니다:
| Name | Orientation | Minimum length | Search area |
|---|---|---|---|
SeparatorRight | Vertical | 180 | ”kwDoctorTitle”의 오른쪽, 페이지 오른쪽 가장자리와 가장 가까운 위치 |
SeparatorLeft | Vertical | 180 | ”kwDoctorTitle”의 왼쪽, “SeparatorRight”의 왼쪽(“kwDoctorTitle”을 찾지 못한 경우), “SeparatorRight”과 가장 가까운 위치, “SeparatorRight” 아래(구분선 이름 오른쪽의 아이콘을 클릭하고 Top Boundary of Region 선택), “SeparatorRight” 제외 |
SeparatorBottom | Horizontal | 200 | ”kwDoctorTitle” 아래(–10 포인트로 위치 조정), “SeparatorLeft”의 오른쪽, “SeparatorRight”의 왼쪽, 페이지 아래쪽 가장자리와 가장 가까운 위치(이 설정은 “kwDoctorTitle”을 찾지 못한 경우에 유용함) |
SeparatorTop | Horizontal | 200 | ”kwDoctorTitle” 위, “SeparatorLeft”의 오른쪽, “TypeOfSickNoteGroup”과 가장 가까운 위치, “SeparatorBottom” 제외 |
- 찾은 Separator를 기준으로 의사 서명과 의사 정보를 위한 검색 영역을 수동으로 지정할 수도 있습니다. 대신, Separator로 경계를 지정한 영역에 해당하는 Region 요소를 생성하겠습니다. “BoxRegion”이라는 이름의 Region 검색 요소를 생성하고 검색 영역을 다음과 같이 지정합니다: “SeparatorRight”의 왼쪽, “SeparatorLeft”의 오른쪽, “SeparatorBottom”의 위, “SeparatorTop”의 아래.
- “DoctorGroup”이라는 새 그룹을 생성합니다.
- 의사의 서명을 찾기 위해, “DoctorGroup” 내부에 다음 설정으로 Object Collection 요소를 생성합니다:
| Property | Value |
|---|---|
| Name | Signature |
| Type | Picture |
| Minimum width | 15 |
| Minimum height | 15 |
| Maximum width | 600 |
| Maximum height | 350 |
| Search Conditions section of the Code Editor | 서명의 일부가 상자 밖에 위치할 수 있습니다. 전체 이미지를 찾기 위해 각 방향으로 100 도트만큼 검색 영역을 확장합니다: RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect.GetInflated(100dot,100dot); |
- 상자 안의 텍스트 정보를 추출하려면 다음 설정으로 Paragraph 요소를 생성합니다:
| Property | Value |
|---|---|
| Name | DoctorInformation |
| Maximum line count | 6 |
| Search area | ”kwDoctorTitle” 위, “Signature” 제외 |
| Search Conditions section of the Code Editor | RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect; |
- Match를 클릭하여 요소들이 올바르게 검색되는지 확인합니다.
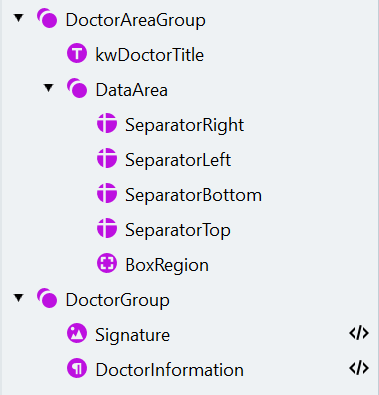
- Manage Fields 대화 상자를 열고, 해당 필드를 생성한 다음 아래와 같이 검색 요소에 매핑합니다:
| Name | Type | Search element |
|---|---|---|
| Doctor Information | ”Doctor” 그룹의 Text 필드 | DoctorInformation |
| Signature | ”Doctor” 그룹의 이미지 필드 | Signature |
- 새 필드에 대해 자동으로 생성된 검색 요소를 삭제합니다.