개요
- 프롬프트 기반 추출 액티비티 생성
- LLM 연결 구성
- 효과적인 추출 프롬프트 작성
- 출력 형식과 구조 정의
- 엄격도 및 검증 규칙 적용
- 추출 결과 테스트 및 개선
- 송장에서 공급업체 정보 추출
- 문서 헤더 수준 데이터 캡처
- 반구조화된 문서 처리
- 레이아웃이 다양한 문서 처리
사전 준비 사항
- ABBYY Vantage Advanced Designer에 대한 접근 권한.
- 구성된 LLM 연결. LLM 연결 구성 방법을 참조하십시오.
- 샘플 문서가 로드된 Document Skill.
- JSON 구조에 대한 기본적인 이해.
- 추출하려는 데이터에 대한 field 정의.
프롬프트 기반 추출 이해
프롬프트 기반 추출이란?
- 역할(Role): LLM이 어떤 역할을 해야 하는지 (예: “data extraction model”).
- 지침(Instructions): 데이터를 어떻게 추출하고 어떤 형식으로 제공해야 하는지.
- 출력 구조(Output Structure): 결과에 사용할 정확한 JSON 형식.
- 규칙(Rules): 애매하거나 누락된 데이터를 어떻게 처리할지에 대한 지침.
장점
- 학습 데이터 불필요: 프롬프트 엔지니어링만으로도 동작합니다.
- 유연함: field를 쉽게 추가하거나 수정할 수 있습니다.
- 변형 처리 가능: LLM은 다양한 문서 형식을 이해할 수 있습니다.
- 빠른 설정: 기존 ML 모델을 학습하는 것보다 더 빠르게 구축할 수 있습니다.
- 자연어 사용: 평이한 영어로 지침을 작성할 수 있습니다.
제한 사항
- 비용: 각 추출에는 LLM API 호출이 사용됩니다.
- 속도: 단순한 문서의 경우 기존 추출 방식보다 느립니다.
- 일관성: 실행 간에 결과가 약간씩 달라질 수 있습니다.
- 컨텍스트 제한: 매우 긴 문서는 별도의 처리가 필요할 수 있습니다.
1단계: 프롬프트 기반 Activity 추가
- ABBYY Vantage Advanced Designer에서 Document Skill을 엽니다.
- 왼쪽 패널에서 **EXTRACT FROM TEXT (NLP)**를 찾습니다.
- Prompt-based를 찾아 클릭합니다.
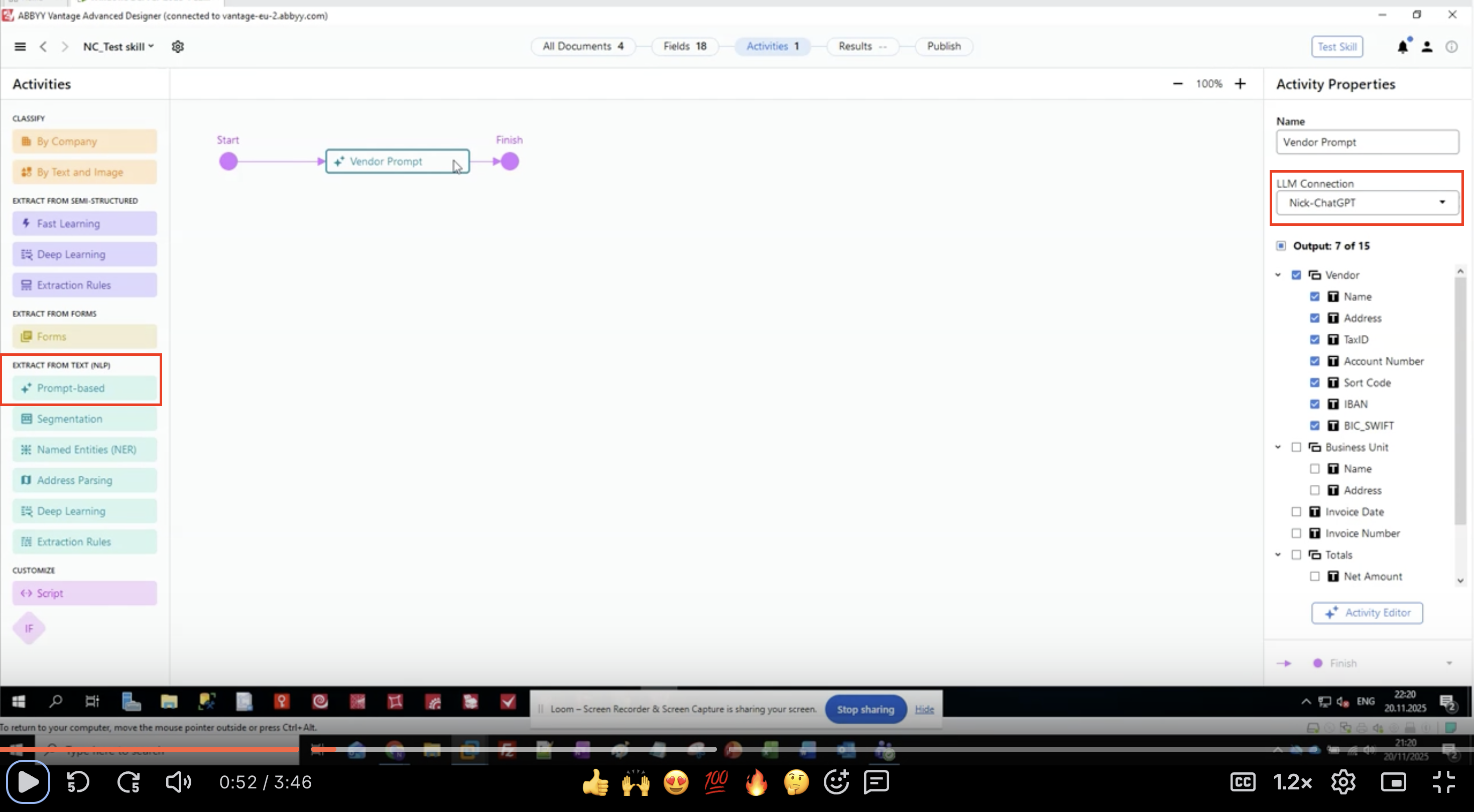
- 해당 Activity가 워크플로우 캔버스에 추가됩니다.
- 입력 Activity와 출력 Activity 사이에 연결합니다.
2단계: LLM 연결 구성
- 워크플로에서 프롬프트 기반 활동을 선택합니다.
- 오른쪽의 Activity Properties 패널에서 LLM Connection을 찾습니다.
- 드롭다운 메뉴를 클릭합니다.
- 목록에서 사전에 구성해 둔 LLM 연결을 선택합니다.
- 예:
Nick-ChatGPT,Microsoft Foundry,Production GPT-4
- 예:
- 선택한 연결이 올바르게 지정되었는지 확인합니다.
3단계: 출력 field 정의
- Activity Properties 패널에서 Output 섹션을 찾습니다.
- field 그룹과 field가 계층 구조로 표시됩니다.
- 이 예에서는 공급업체 정보를 추출합니다:
- 공급업체 (Vendor)
- Name
- Address
- TaxID
- 계좌 번호 (Account Number)
- Sort Code
- IBAN
- BIC_SWIFT
- Business Unit
- Name
- Address
- 송장 발행일 (Invoice Date)
- 송장 번호 (Invoice Number)
- 합계 (Totals)
- 순액 (Net Amount)
- 공급업체 (Vendor)
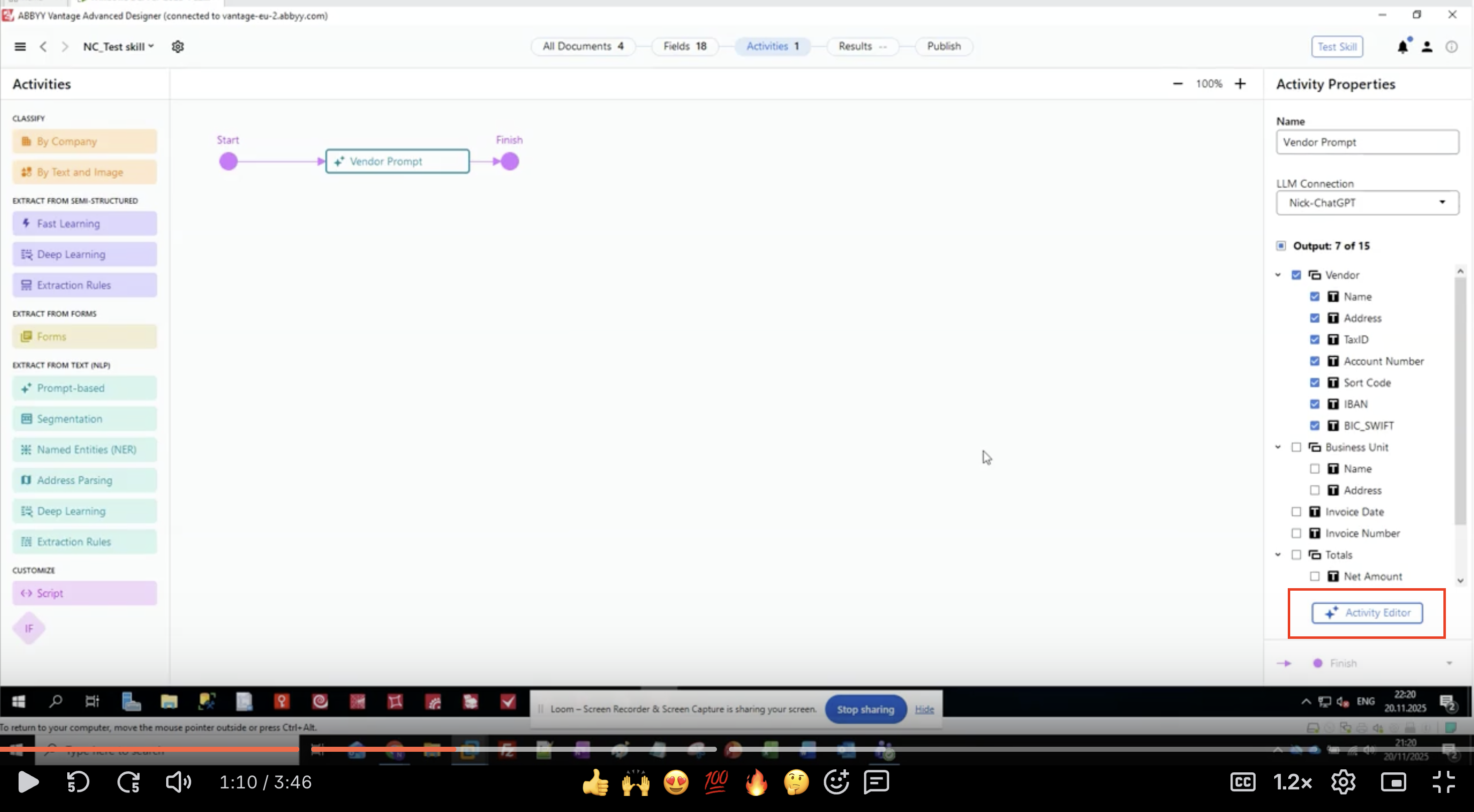
- 프롬프트 구성을 시작하려면 Activity Editor 버튼을 클릭합니다.
4단계: 역할 정의 작성
- Activity Editor에서 Prompt Text 인터페이스를 확인합니다.
- ROLE 섹션부터 시작합니다:
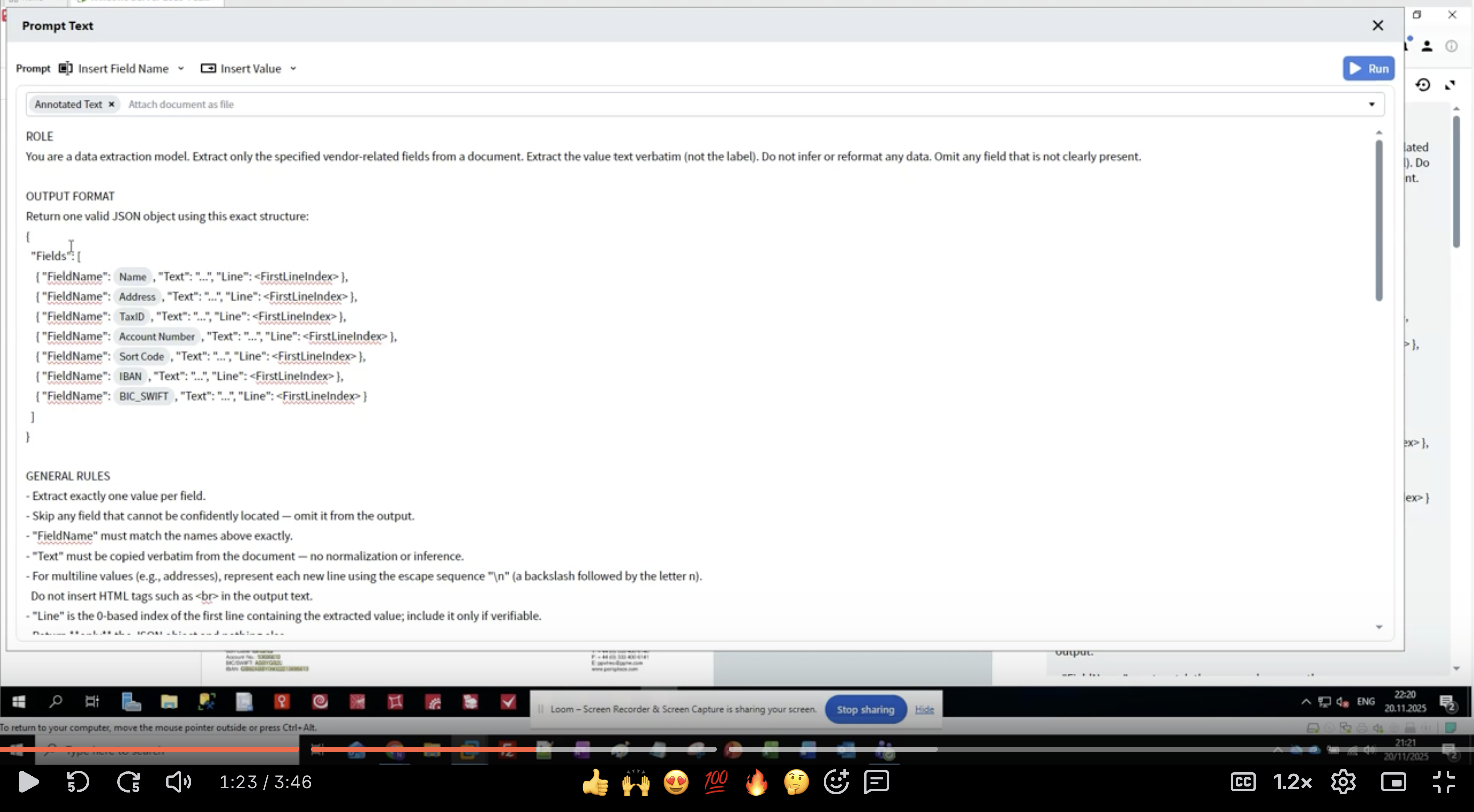
- 구체적으로 정의: “data extraction model”은 LLM에게 역할(목적)을 명확히 알려 줍니다.
- 범위 정의: “vendor-related fields”는 추출 대상을 제한합니다.
- 기대치 설정: “value text verbatim”은 값 텍스트를 원문 그대로 사용하도록 지시해 재포맷팅을 방지합니다.
- 누락 데이터 처리: “Omit any field that is not clearly present”를 통해 명확히 존재하지 않는 field는 생략합니다.
- 역할 설명은 명확하고 간결하게 유지합니다.
- 명령형 문장을 사용합니다 (“Extract”, “Do not infer”).
- 하지 말아야 할 작업을 명시적으로 기술합니다.
- 예외/경계 상황(edge case)을 어떻게 처리할지 정의합니다.
5단계: 출력 형식 정의
- ROLE 섹션 아래에 OUTPUT FORMAT 제목을 추가합니다.
- JSON 구조를 정의합니다.
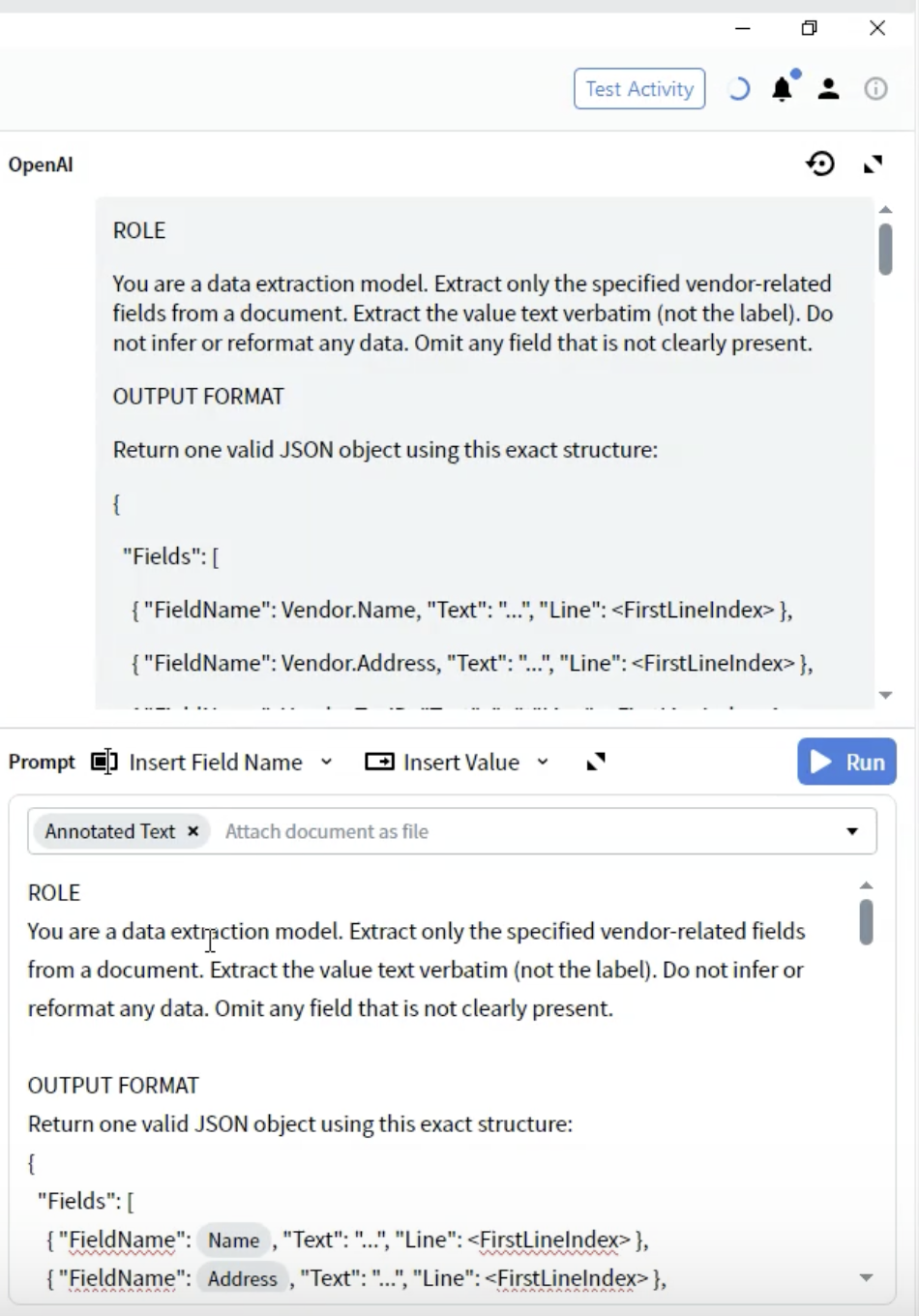
- FieldName: field 정의와 정확히 일치해야 합니다(예:
Vendor.Name). - Text: string 형태의 추출된 값입니다.
- Line: 값이 문서에서 나타나는 줄의 0부터 시작하는 인덱스입니다.
- Output 구성에서 정의한 field 이름을 정확히 사용하세요.
- 비어 있을 수 있는 경우라도 모든 field를 포함하세요.
- 이 구조는 올바른 JSON 형식이어야 합니다.
- 줄 번호는 검증 및 문제 해결에 도움이 됩니다.
Step 6: Field별 추출 규칙 추가
- 인식 패턴: 각 field에 대한 대체 레이블을 나열합니다.
- 형식 명세: 추출해야 하는 정확한 형식을 설명합니다.
- 위치 힌트: 데이터를 일반적으로 어디에서 찾을 수 있는지 설명합니다.
- 제외 항목: 추출 대상에서 제외해야 할 내용을 정의합니다.
- 규칙에 번호를 매겨 명확하게 합니다.
- 레이블의 여러 변형을 제공합니다.
- 데이터 소유 주체를 명시합니다(공급업체 측 vs. 고객 측).
- 괄호 안에 형식 예시를 포함합니다.
- 연관된 field에 대해 명확하게 기술합니다(예: “IBAN — 별도의 field가 있으므로 무시”).
7단계: 엄격도 규칙 적용
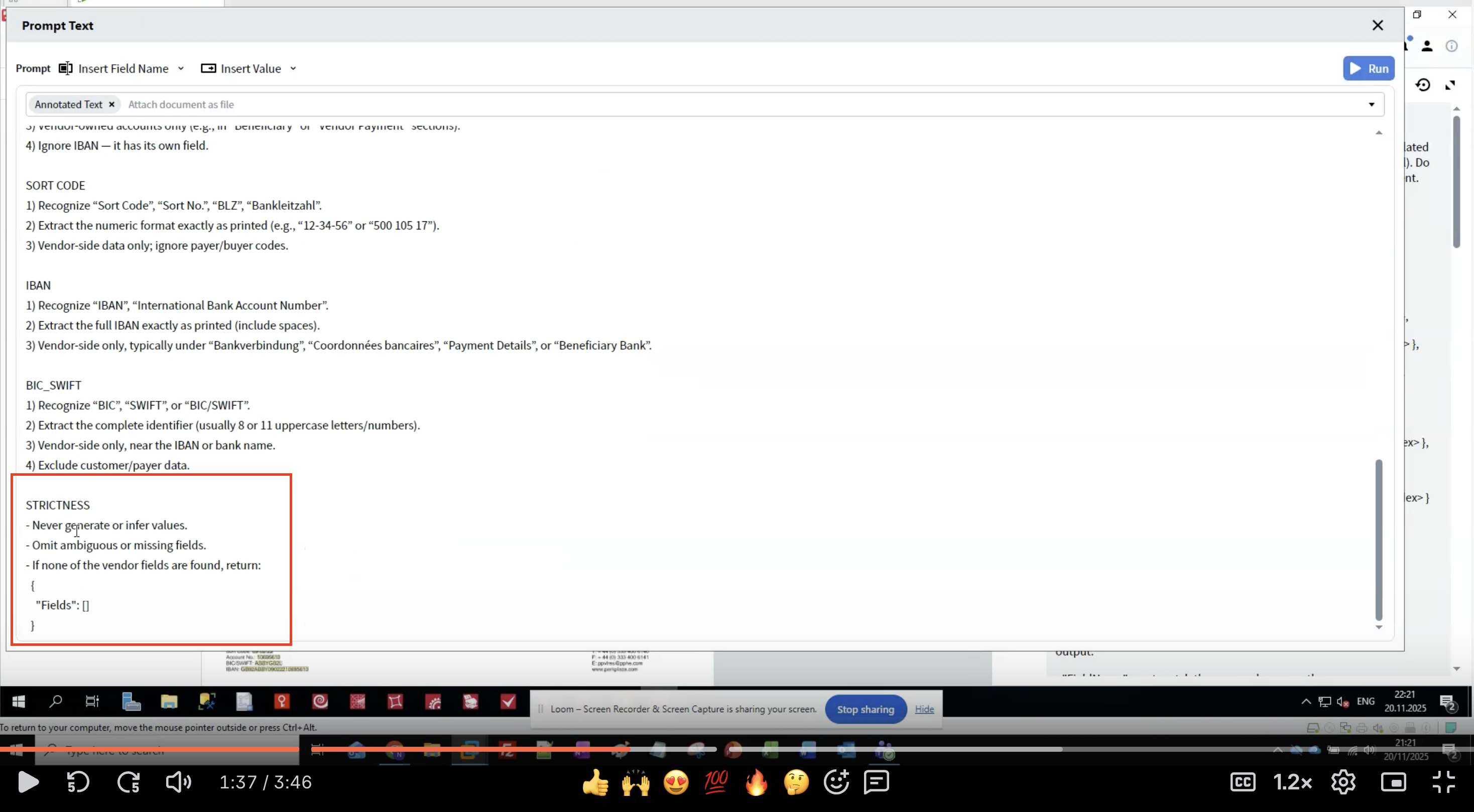
- 환각(hallucination)을 방지: LLM은 그럴듯하지만 잘못된 데이터를 생성할 수 있습니다.
- 일관성 보장: 명확한 규칙은 실행 결과 간 변동을 줄여 줍니다.
- 누락된 데이터 처리: field를 찾지 못했을 때 무엇을 할지 정의합니다.
- 데이터 무결성 유지: 원문을 그대로 추출하면 원래 서식을 보존할 수 있습니다.
- 문서에 존재하지 않는 데이터를 절대 생성하지 않습니다.
- 추측하기보다는 불확실한 추출 결과는 생략합니다.
- 어떤 field도 발견되지 않으면 빈 구조를 반환합니다.
- field 이름을 정확히 일치시킵니다.
- 원본 텍스트 서식을 보존합니다.
8단계: 문서 형식 선택
- Activity Editor에서 Prompt 드롭다운을 찾습니다.
- 문서를 LLM에 어떤 방식으로 제공할지에 대한 여러 옵션을 볼 수 있습니다.
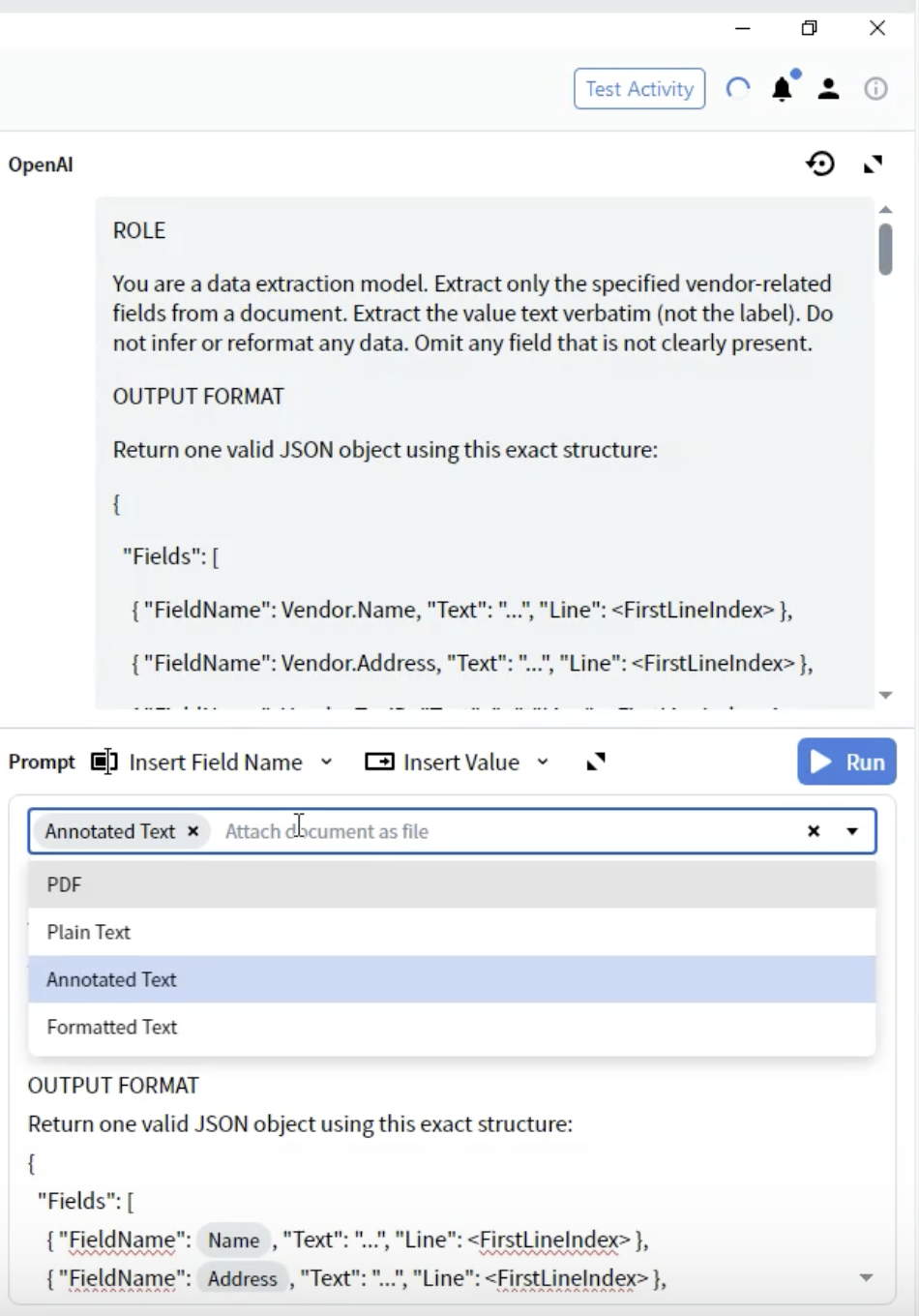
- PDF: 원본 PDF 파일
- 사용 대상: 레이아웃이 매우 중요한 문서
- 고려 사항: 파일 크기가 크고 일부 LLM은 PDF 지원이 제한적임
- Plain Text: 서식이 제거된 텍스트 추출
- 사용 대상: 단순한 텍스트 전용 문서
- 고려 사항: 모든 서식 및 레이아웃 정보가 손실됨
- Annotated Text ⭐ (권장)
- 사용 대상: 대부분의 문서 유형
- 고려 사항: 텍스트 기반이면서 구조를 보존함
- 이점: 구조와 성능 간의 최적 균형 제공
- Formatted Text: 기본 서식이 유지된 텍스트
- 사용 대상: 일부 서식이 중요한 문서
- 고려 사항: Plain Text와 Annotated Text의 중간 지점
- 최상의 결과를 위해 Annotated Text를 선택합니다.
9단계: 추출 결과 테스트
Activity 실행
- Activity Editor를 닫습니다.
- All Documents 탭으로 이동합니다.
- 테스트 문서를 선택합니다.
- Test Activity 또는 Run 버튼을 클릭합니다.
- LLM이 문서를 처리할 때까지 기다립니다.
- 처리 시간: 문서 복잡도에 따라 일반적으로 5–30초 정도 소요됩니다.
- API 응답을 기다리는 동안 로딩 표시가 나타납니다.
결과 검토
- 인터페이스가 Predictive view로 전환됩니다.
- 추출된 fields가 표시된 Output 패널을 검토합니다.
- 각 field를 클릭하여 다음을 확인합니다:
- 추출된 값
- 신뢰도 점수(제공된 경우)
- 문서 이미지에서 하이라이트된 영역
- ✅ 예상된 모든 fields가 값으로 채워져 있음
- ✅ 값이 문서와 정확히 일치함
- ✅ 환각(hallucination)이나 과도한 추론으로 생성된 데이터가 없음
- ✅ 여러 줄 field가 올바르게 처리됨
- ✅ 누락된 fields는 생략되어 있음(잘못된 데이터로 채워지지 않음)
일반적인 결과 유형
10단계: 프롬프트 다듬기
일반적인 문제와 해결 방법
- 해결 방법: 더 구체적인 위치 힌트를 추가합니다.
- 예시: “공급업체 측 정보만; 고객/구매자 주소는 제외”
- 해결 방법: 원문 그대로 추출하도록 강조합니다.
- 예시: “숫자 형식을 인쇄된 그대로 정확히 추출하십시오 (예: ‘12-34-56’)”
- 해결 방법: 엄격한 규칙을 강화합니다.
- 예시: “값을 생성하거나 추론하지 마십시오. 존재하지 않으면 생략하십시오.”
- 해결 방법: 이스케이프 시퀀스를 지정합니다.
- 예시: “여러 줄 값의 경우, 줄 바꿈에는
\n을 사용하십시오”
- 해결 방법: field 이름이 정확히 일치하는지 확인합니다.
- 예시:
AccountNumber가 아니라Vendor.Account Number를 사용하십시오
반복적 개선 프로세스
- 여러 문서로 테스트: 하나의 예시에만 맞춰 최적화하지 마세요.
- 패턴 문서화: 어떤 규칙이 잘 동작하고, 어떤 규칙은 추가 개선이 필요한지 기록하세요.
- 구체적인 예 추가: 괄호 안에 형식 예시를 포함하세요.
- 엄격도 조정: 과도/과소 추출 패턴에 따라 조정하세요.
- 엣지 케이스(경계 사례) 테스트: field가 누락되었거나 레이아웃이 특이한 문서로도 시험해 보세요.
개선 예시
추출 프로세스 이해
프롬프트 기반 추출 작동 방식
- 문서 변환: 문서는 선택한 형식으로 변환됩니다(Annotated Text 권장).
- 프롬프트 구성: 사용자 역할, 출력 형식, field 규칙, 엄격도 규칙이 하나의 프롬프트로 결합됩니다.
- API 호출: 프롬프트와 문서가 연결을 통해 LLM으로 전송됩니다.
- LLM 처리: LLM이 문서를 읽고 지시에 따라 데이터를 추출합니다.
- JSON 응답: LLM이 지정된 JSON 형식으로 구조화된 데이터를 반환합니다.
- Field 매핑: Vantage가 JSON 응답을 정의해 둔 출력 fields에 매핑합니다.
- 검증: 행 번호와 신뢰도 점수(제공된 경우)를 사용해 정확성을 검증합니다.
토큰 사용량 및 비용
- 문서 길이: 문서가 길수록 더 많은 토큰을 사용합니다.
- 프롬프트 복잡도: 프롬프트가 복잡할수록 토큰 수가 증가합니다.
- 형식 선택: Annotated Text가 토큰 사용 측면에서 일반적으로 PDF보다 효율적입니다.
- field 수: field가 많을수록 프롬프트가 길어집니다.
- 프롬프트에는 간결하지만 명확한 표현을 사용하세요.
- 지시사항을 중복해서 작성하지 마세요.
- 불필요한 예시는 제거하세요.
- 관련 데이터는 field를 그룹화하는 방식을 고려하세요.
모범 사례
프롬프트 작성
- ✅ 명확한 명령문을 사용하세요 (“Extract”, “Recognize”, “Omit”).
- ✅ 각 field에 대해 여러 개의 라벨 변형을 제공하세요.
- ✅ 괄호 안에 형식 예시를 포함하세요.
- ✅ 추출하면 안 되는 것(제외 항목)을 명시하세요.
- ✅ 참조하기 쉽도록 규칙에 번호를 매기세요.
- ✅ 전체적으로 일관된 용어를 사용하세요.
- ❌ 모호한 지시를 사용하지 마세요 (“get the name”).
- ❌ LLM이 도메인별 관행을 알고 있다고 가정하지 마세요.
- ❌ 지나치게 길고 복잡한 문장을 작성하지 마세요.
- ❌ 서로 다른 섹션에서 스스로 모순되게 작성하지 마세요.
- ❌ 엄격성 규칙을 생략하지 마세요.
Field 정의
- 인식 패턴(대체 레이블)부터 정의합니다.
- 유지해야 할 정확한 형식을 지정합니다.
- 위치 힌트(일반적인 배치 위치)를 제공합니다.
- 데이터 소유권(공급업체 vs. 고객)을 정의합니다.
- 여러 줄 값에 대한 처리 방식을 포함합니다.
- 혼동을 피하기 위해 관련 fields를 참조합니다.
테스트 전략
- 간단한 문서부터 시작: 먼저 기본적인 추출을 테스트합니다.
- 다양한 변형으로 확장: 서로 다른 레이아웃과 형식을 시도합니다.
- 경계 사례 테스트: 누락된 field, 비정상적인 위치, 여러 개가 일치하는 경우 등을 테스트합니다.
- 실패 사례 문서화: 추출이 실패한 예시를 기록해 둡니다.
- 체계적으로 반복: 한 번에 한 가지씩만 변경합니다.
성능 최적화
- 프롬프트를 간결하게 유지합니다.
- Annotated Text 형식을 사용합니다.
- 액티비티당 field 수를 최소화합니다.
- 복잡한 문서는 분할하는 방안을 고려합니다.
- 포괄적인 field 규칙을 제공합니다.
- 형식 예시를 포함합니다.
- 엄격한 규칙을 추가합니다.
- 다양한 문서 샘플로 테스트합니다.
- 프롬프트 길이를 최적화합니다.
- 효율적인 문서 형식을 사용합니다.
- 적절한 경우 결과를 캐시합니다.
- LLM 제공업체 대시보드를 통해 토큰 사용량을 모니터링합니다.
문제 해결
추출 문제
- field 이름의 철자가 정확히 일치하는지 확인합니다.
- 데이터가 선택한 문서 형식에 맞게 존재하는지 확인합니다.
- 인식 패턴에 더 다양한 레이블 변형을 추가합니다.
- LLM이 찾는지 확인하기 위해 엄격도를 일시적으로 낮춥니다.
- 문서 품질이 OCR/Text 추출에 영향을 주는지 확인합니다.
- 공급업체 측 사양을 더 구체적이고 엄격하게 정의합니다.
- 고객/구매자 데이터에 대한 명시적 제외 규칙을 추가합니다.
- 위치 힌트를 제공합니다(예: “문서 상단”, “발행자 섹션”).
- 올바른 추출과 잘못된 추출 예시를 모두 포함합니다.
- 이스케이프 시퀀스 형식(
\n)을 명시적으로 지정합니다. - 올바른 여러 줄 출력 예시를 제공합니다.
- 문서 형식이 줄바꿈을 보존하는지 확인합니다.
- 다음 지시를 추가합니다: “원래 줄바꿈을
\n으로 보존할 것”.
- “verbatim” 및 “인쇄된 그대로”라는 표현을 강조합니다.
- 다음과 같은 엄격한 규칙을 추가합니다: “정규화나 추론 금지”.
- 서식을 그대로 보존하는 구체적인 예시를 제공합니다.
- 다음과 같은 부정 예시를 포함합니다: “‘12-34-56’으로 바꾸지 말고, ‘12 34 56’ 그대로 유지”.
성능 문제
- PDF를 사용하는 경우 Annotated Text 형식으로 전환합니다.
- 중요한 지침은 유지하면서 프롬프트를 단순화합니다.
- 이미지가 매우 큰 경우 문서 해상도를 낮춥니다.
- LLM 제공업체의 상태와 요청 속도 제한(rate limit)을 확인합니다.
- 단순한 문서에는 더 빠른 모델 사용을 고려합니다.
- 엄격성 규칙을 강화합니다.
- 지침을 더 구체적이고 모호하지 않게 작성합니다.
- 형식 예제를 더 추가합니다.
- 해석의 여지를 줄이기 위해 프롬프트 복잡도를 낮춥니다.
- (연결에서 지원되는 경우) temperature 값을 더 높게 설정하여 테스트합니다.
- 프롬프트 길이를 최적화합니다.
- PDF 대신 Annotated Text를 사용합니다.
- 비혼잡 시간대에 문서를 배치 처리합니다.
- 단순한 문서에는 더 작거나 저렴한 모델 사용을 고려합니다.
- LLM 제공업체 대시보드에서 예산 알림을 설정하고 모니터링합니다.
고급 기법
조건부 추출
다국어 지원
검증 규칙
Field 관계
제약 사항 및 고려사항
현재 기능
- ✅ 헤더 수준 field 추출
- ✅ 단일 및 여러 줄 값
- ✅ 문서당 여러 field
- ✅ 조건부 추출 로직
- ✅ 다국어 문서
- ✅ 다양한 문서 레이아웃
- ⚠️ 테이블 추출 (구현 방식에 따라 다름)
- ⚠️ 중첩된 복합 구조
- ⚠️ 매우 큰 문서 (토큰 제한)
- ⚠️ 실시간 처리 (API 지연)
- ⚠️ 완전히 결정론적인 결과 보장
프롬프트 기반 추출을 언제 사용해야 할까요
- 레이아웃이 가변적인 문서
- 반구조화된 문서
- 빠른 프로토타이핑 및 테스트
- 소규모~중간 규모 문서 처리량
- 학습 데이터가 없는 경우
- 다국어 문서 처리
- 대규모 프로덕션 환경 (기존 ML이 더 빠를 수 있음)
- 고도로 구조화된 양식 (템플릿 기반 추출이 적합)
- 비용에 민감한 애플리케이션 (기존 방식이 더 저렴할 수 있음)
- 지연 시간에 민감한 애플리케이션 (LLM API에는 네트워크 지연이 존재)
- 오프라인 처리가 필요한 경우 (기존 방식은 인터넷이 필요 없음)
Document Skill과의 통합
추출된 데이터 사용
- Validation Activities: 추출된 값에 비즈니스 규칙을 적용합니다.
- Script Activities: 추출된 데이터를 처리하거나 변환합니다.
- Export Activities: 데이터를 외부 시스템으로 전송합니다.
- Review Interface: 추출된 field를 수동으로 검토 및 검증합니다.
다른 액티비티와의 결합
Field 매핑
"FieldName": "Vendor.Name"→ 출력 fieldVendor.Name에 매핑됩니다.- Field 계층 구조는 출력 구조에서도 그대로 유지됩니다.
- 줄 번호는 검증 및 문제 해결에 도움이 됩니다.
요약
- ✅ 프롬프트 기반 추출 액티비티를 생성했습니다.
- ✅ LLM 연결을 구성했습니다.
- ✅ 역할, 형식, 규칙을 포함한 포괄적인 추출 프롬프트를 작성했습니다.
- ✅ 최적의 문서 형식(Annotated Text)을 선택했습니다.
- ✅ 데이터 품질을 위한 엄격도 규칙을 적용했습니다.
- ✅ 추출을 테스트하고 결과를 검토했습니다.
- ✅ 프롬프트 엔지니어링을 위한 모범 사례를 학습했습니다.
- 프롬프트 기반 추출은 자연어 지침을 사용합니다.
- Annotated Text 형식이 최상의 결과를 제공합니다.
- 명확하고 구체적인 프롬프트는 일관된 추출을 가능하게 합니다.
- 엄격도 규칙은 환각을 방지하고 데이터 품질을 유지합니다.
- 반복적인 테스트와 개선은 정확도를 향상시킵니다.
다음 단계
- 다양한 문서로 테스트: 서로 다른 레이아웃과 변형을 대상으로 검증합니다.
- 프롬프트 개선: 결과를 바탕으로 지속적으로 다듬습니다.
- 비용 모니터링: LLM 제공업체 대시보드에서 토큰 사용량을 추적합니다.
- 성능 최적화: 속도와 정확도를 높이도록 프롬프트를 최적화합니다.
- 테이블 추출 활용: 품목 내역 추출을 시도해 봅니다(지원되는 경우).
- 워크플로와 통합: 완전한 처리를 위해 다른 작업과 결합합니다.
추가 자료
- ABBYY Vantage Advanced Designer 설명서: https://docs.abbyy.com
- LLM 연결 설정 가이드: LLM 연결 구성 방법.
- 프롬프트 엔지니어링 모범 사례: 사용 중인 LLM 제공업체의 설명서를 참조하세요.
- 지원: 기술 지원이 필요하면 ABBYY 지원팀에 문의하세요.