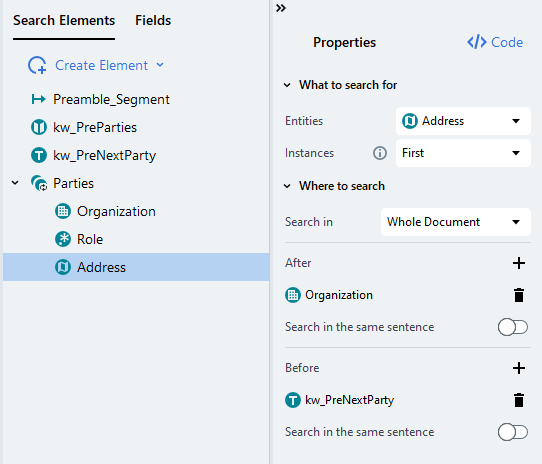
// Check that the Address search element hasn't been found yet, because we need only the first instance
~Parties.Address,
// Get the Organization search element and the next party keyword search element. They were found before Address
t1 : Parties.Organization,
t2 : kw_PreNextParty
// 查找包含一个 NERAddress 命名实体的标记序列
// ("same" 关键字指定如果有多个 NERAddress,则只应匹配一个)
// 地址应位于组织名称之后和下一个参与方的关键字之前
// + 号表示标记序列可能由多个单词组成
// 末尾的 ~@Parties.Address 条件确保
// 地址不会在相同的标记上再次匹配
[ t: @NERAddress( same, right_to( t1 ), left_to( t2 ) ) ~@Parties.Address ]+
=>
Parties.Address( t );