查找命名实体的最后一次出现
提取最后一个组织实体实例的规则
示例
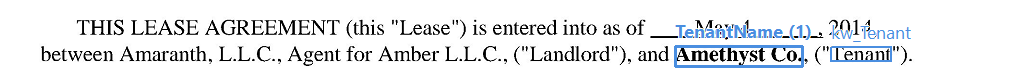
提取同时以文字和数字形式表示的金额
金额提取规则
示例

借助关键字查找片段
用于将二级标题提取到 kw_Heading2 搜索元素的规则
用于将片段提取到 Segment 搜索元素中的规则
示例

kw_Heading2 搜索元素中,然后将任意两个连续出现的 kw_Heading2 搜索元素之间的文本提取为一个 Segment 搜索元素实例。
对每个实体的信息进行分组
- 查找组织名称,为找到的每个名称创建一个新的
Party_Group组搜索元素实例,并填充其名为 “Organization_Name” 的子搜索元素。 - 针对每个组织名称实例,查找与其相距不超过 (例如) 20 个 token 的地址和角色,访问作为该组织名称父级的
Party_Group实例,并在该实例中填充名为 “Address” 和 “Role” 的子搜索元素。
用于提取 Organization_Name 搜索元素的规则
用于提取 Address 搜索元素的规则
用于提取 Role 搜索元素的规则
示例


同时查找日期和时间
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?) 。接下来,我们查找一个与其相邻的 Date 命名实体。最后,我们将找到的词元序列拼接起来,并将结果赋值给名为 “TimeAndDate” 的搜索元素。
同时提取日期和时间的规则
示例
