Recherche de la dernière occurrence d’une entité nommée
Règle d’extraction de la dernière occurrence d’organisation
Exemple
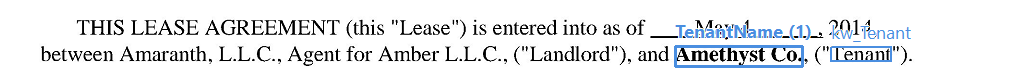
Extraire un montant indiqué à la fois en toutes lettres et en chiffres
Règle d’extraction d’un montant
Exemple

Recherche de segments à l’aide de mots-clés
Règle d’extraction des titres de niveau 2 vers l’élément de recherche kw_Heading2
Règle d’extraction du segment vers l’élément de recherche « Segment »
Exemple

kw_Heading2, puis le texte compris entre deux occurrences consécutives de l’élément de recherche kw_Heading2 est extrait dans une instance de l’élément de recherche Segment.
Regrouper les informations sur chaque entité
- Rechercher les noms d’organisation, créer une nouvelle instance de l’élément de recherche de groupe
Party_Grouppour chaque nom trouvé, et renseigner son élément de recherche enfant nommé “Organization_Name”. - Rechercher l’adresse et le rôle situés à une distance maximale de, disons, 20 tokens de chaque occurrence du nom de l’organisation, accéder à l’instance de
Party_Groupparente de ce nom et renseigner, dans cette instance, les éléments de recherche enfants nommés “Address” et “Role”.
Règle d’extraction de l’élément de recherche Organization_Name
Règle d’extraction de l’élément de recherche Address
Règle d’extraction de l’élément de recherche « Role »
Exemple


Recherche conjointe de la date et de l’heure
[1]?\d:\d{2}\s+(([ap]\.m\.)|([AP]M))?). Ensuite, nous recherchons une entité nommée Date située à proximité. Enfin, nous concaténons les séquences de jetons trouvées et affectons le résultat à un élément de recherche nommé “TimeAndDate”.
Règle d’extraction de la date et de l’heure combinées
Exemple
