Prima di iniziare
- Apri l’attività “Sick Note DE” in Activity Editor.
- Seleziona uno dei documenti dal set di documenti.
- Assicurati che la modalità avanzata per le proprietà degli elementi sia attivata. Per attivare o disattivare questa modalità, fai clic sull’icona nel riquadro Properties.
- Tutti i documenti caricati sono stati prerecogniti ed è utile vedere quali oggetti sono stati individuati nell’immagine. Fai clic sull’icona. Se non vedi questa icona a causa delle dimensioni dello schermo, fai clic sull’icona e seleziona Recognized Words. Gli oggetti corrispondenti verranno evidenziati nell’immagine del documento. Puoi passare tra vari tipi di oggetti evidenziati in qualsiasi momento. Ad esempio, passare a Recognized Lines può essere utile quando cerchi paragrafi, mentre passare a Separators semplificherà la configurazione di un elemento di ricerca Separator.
- Se un elemento di ricerca si trova al di fuori dell’area di ricerca, non verrà trovato. Attiva l’opzione Show search area nel menu contestuale dell’immagine del documento. L’area di ricerca per ciascun elemento verrà evidenziata in verde quando valuti i risultati di corrispondenza.
Estrazione dei dati del paziente
- Fai clic su Create Element e seleziona l’elemento Group dall’elenco a discesa. Cambia il nome in “PatientDataArea”.
- Un nuovo elemento di ricerca di gruppo è impostato come obbligatorio per impostazione predefinita. Se un elemento obbligatorio non viene trovato, l’Activity Editor restituisce un errore e il matching viene interrotto. Questo scenario consente di saltare le attività se non sono adatte a un determinato documento. Tuttavia, in questo tutorial stiamo creando un’attività per estrarre dati da tutti i documenti in arrivo, quindi vogliamo che il gruppo sia facoltativo. Nella sezione Under what conditions, modifica il valore Element is in Optional.
- Vogliamo trovare il paragrafo che contiene il nome e l’indirizzo del paziente. Nei documenti tedeschi, il paragrafo che cerchiamo si trova sempre nel field con l’etichetta “Name, Vorname … ”. Dobbiamo trovare questo testo nel documento e usarlo come riferimento per cercare i dati che vogliamo estrarre.
a. Le parole chiave possono essere trovate usando l’elemento di ricerca Static Text. Fai clic su Create Element e seleziona l’elemento Static Text dall’elenco a discesa. Cambia il nome in “kwPatientTitle”.
b. Inserisci il testo “Name, Vorname” nel field Text to find del riquadro Properties.
c. fai clic su Match. Al termine dell’elaborazione, vedrai il Tree of Hypotheses sotto il documento. Assicurati che Advanced Designer abbia trovato correttamente il testo statico desiderato. Un punto verde accanto al nome dell’elemento indica che un elemento corrispondente è stato trovato nel documento. Se fai clic sul nome dell’elemento nel Tree of Hypotheses, vedrai una cornice viola attorno all’area corrispondente nel documento.
Se un elemento non è stato trovato, vedrai un punto arancione accanto al suo nome e una cornice arancione attorno all’immagine del documento. Tieni presente che la qualità dell’ipotesi di un elemento influisce sullo stato degli elementi successivi nella catena e sulla qualità complessiva della catena. Puoi trovare informazioni dettagliate sulla qualità delle ipotesi nella documentazione.
- Ora individuiamo il bordo inferiore della cella che contiene il nome e l’indirizzo del paziente. Lo faremo usando un elemento Separator.
a. Aggiungi un elemento Separator al gruppo e chiamalo “SeparatorBottom”. Imposta la lunghezza minima su 200.
b. Fai clic con il pulsante destro del mouse sull’elemento e seleziona Match Element nel menu contestuale. Vedrai che il Tree of Hypotheses contiene molti punti verdi. Corrispondono a diversi separatori che soddisfano i criteri di ricerca. Puoi fare clic su ciascun punto per vedere l’oggetto corrispondente nell’immagine.
c. Per restringere i criteri di ricerca, specifica l’area di ricerca del separatore. Fai clic su Match per trovare l’elemento “kwPatientTitle” che verrà usato come elemento di ancoraggio. Nella sezione Where to search del riquadro Properties, fai clic su Draw on Image. Seleziona l’elemento “kwPatientTitle” nel documento e fai clic sull’icona della freccia verso il basso per specificare l’area di ricerca sotto la parola chiave e sull’icona più vicina per cercare il separatore più vicino alla parola chiave. Trovi una descrizione dettagliata degli elementi di ancoraggio nella documentazione.
d. Fai clic su Match e verifica che Advanced Designer abbia trovato il separatore sotto l’elemento “kwPatientTitle”. Puoi controllare l’ipotesi per ogni elemento facendo clic sul suo nome nella sezione Tree of Hypotheses. - Un’etichetta e un separatore sono elementi di riferimento affidabili per i dati del paziente. Tuttavia, se la qualità di stampa è troppo bassa, è possibile che il testo dell’etichetta non venga riconosciuto o che il separatore non venga trovato. Per garantire buoni risultati di estrazione, cercheremo un paragrafo compreso tra l’etichetta e il separatore. Un paragrafo è un blocco uniforme di testo, il che significa che può essere trovato correttamente anche se alcuni elementi di contorno non sono stati trovati.
a. Crea un elemento di ricerca Paragraph e chiamalo “NameAddressParagraph”.
b. Modifica Text alignment in Left.
c. I dati del paziente occupano da due a cinque righe, quindi specifica Line count da 2 a 5.
d. Specifica l’area di ricerca per il paragrafo. Questa volta devi usare il menu Add nella sezione Where to search. L’elemento deve trovarsi sotto l’elemento “kwPatientTitle” e sopra l’elemento “SeparatorBottom”.
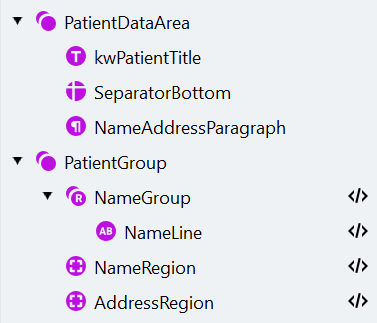
e. Fai clic su Match. - Ora vogliamo estrarre i dati del paziente. Crea un nuovo elemento di gruppo chiamato “PatientGroup”.
- Il nome del paziente può occupare una o due righe. Per acquisire più istanze di un elemento, useremo un gruppo ripetuto.
a. Crea un elemento di ricerca Repeating Group e chiamalo “NameGroup”. Specifica 2 come numero massimo di ripetizioni. Rendi l’elemento facoltativo.
b. Vogliamo cercare le righe che fanno parte del paragrafo “NameAddressParagraph”. Per specificare la regione dell’elemento come area di ricerca, fai clic sull’icona dell’editor di codice sotto l’immagine del documento e incolla il seguente script nella sezione Search Conditions del Code Editor:
d. Il testo che stiamo cercando può contenere lettere maiuscole e minuscole, nonché un insieme di segni di punteggiatura che possono comparire nei nomi. Configura due insiemi di caratteri separati. Il primo insieme deve contenere tutte le lettere latine maiuscole e minuscole. Per aggiungere caratteri con segni diacritici, modifica il sottorange Unicode oppure incolla direttamente i caratteri nel campo Selected characters.
e. L’altro insieme deve contenere i seguenti segni di punteggiatura: ,-.()’. Non vogliamo che la stringa contenga solo segni di punteggiatura, quindi imposta Portion in text, % per il secondo insieme al 40%. Questa proprietà definisce la percentuale massima consentita di caratteri provenienti da un determinato insieme.
Le impostazioni predefinite consentono alla stringa di contenere fino al 30% di caratteri non inclusi in alcun insieme. Questo aiuta a trovare stringhe anche quando alcuni caratteri vengono riconosciuti in modo errato o non sono inclusi nell’insieme (ad esempio i caratteri con segni diacritici). Puoi regolare questa impostazione modificando il valore Allowed errors nel riquadro Properties.
g. Specifica l’area di ricerca per l’elemento “NameLine”: sotto l’elemento “kwPatientTitle” e il più vicino possibile a esso.
h. fai clic su Match e controlla il Tree of Hypotheses. Vedrai che vengono trovate due stringhe di caratteri. Tuttavia, la seconda stringa contiene l’indirizzo del paziente.
i. Per escludere l’indirizzo dai risultati di ricerca, verificheremo se la prima stringa contiene sia il nome sia il cognome. Questo può essere fatto aggiungendo una semplice condizione di ricerca tramite script. Seleziona l’elemento di ricerca “NameLine” e apri l’editor di codice Search Conditions.
j. Presumiamo che la prima riga contenga il nome completo se contiene una virgola e uno spazio. Se contiene un nome completo, non vogliamo cercare una seconda istanza del gruppo ripetuto. Incolla il seguente script nell’editor:
- Il nome del paziente estratto nel passaggio 7 verrà mappato al field “Name”. Estraremo e mapperemo anche l’indirizzo del paziente.
a. All’interno di “PatientGroup”, crea un elemento di ricerca Character String chiamato “Address” con la stessa configurazione del set di caratteri dell’elemento “NameLine”.
b. Specifica l’area di ricerca per l’elemento usando il codice: l’indirizzo deve trovarsi sotto “NameLine” oppure, se questo elemento non è stato trovato, sotto la prima riga dell’elemento “NameAddressParagraph”.
d. fai clic su Match. La struttura degli elementi di ricerca dovrebbe essere la seguente:
- Apri la finestra di dialogo Manage Fields, crea i field corrispondenti e mappali agli elementi di ricerca come segue:
| Name | Type | Search element |
|---|---|---|
| Name | Text field nel gruppo “Patient” | NameLine |
| Address | Text field nel gruppo “Patient” | Address |
- elimina gli elementi di ricerca creati automaticamente per i nuovi field.
Estrazione del tipo di certificato di malattia
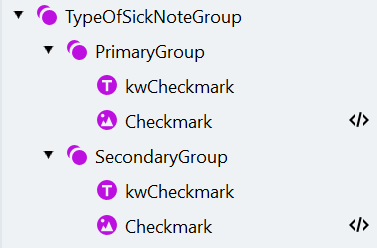
- Crea un elemento Group chiamato “TypeOfSickNoteGroup”. Rendi l’elemento facoltativo.
- Per memorizzare le informazioni su entrambi i segni di spunta, crea un elemento di ricerca Repeating Group e chiamalo “PrimaryGroup”.
a. È una buona idea limitare l’area di ricerca per il gruppo di elementi. Specifica l’area di ricerca usando il codice: a destra dell’elemento “PatientGroup” e sopra l’elemento “DoctorAreaGroup” (che verrà creato più avanti). **Note: **Specifica sempre la condizione “Exists” quando usi elementi futuri.
c. Crea un elemento di ricerca Object Collection chiamato “Checkmark” con le seguenti impostazioni: Type:
Checkmark, Checkmark state: Checked, Minimum height: 10, Maximum width: 20, Maximum height: 20. Specifica che l’elemento si trova a sinistra dell’elemento “kwPrimary” ed è il più vicino a esso. d. fai clic su Match.
- Copia e incolla il gruppo “PrimaryGroup”. Rinomina il gruppo copiato in “SecondaryGroup”. Questo gruppo sarà obbligatorio.
- Modifica il gruppo “SecondaryGroup”.
a. Rinomina l’elemento “kwPrimary” in “kwSecondary” e imposta il testo da trovare su “Folgebescheinigung”. Specifica l’area di ricerca: sotto l’elemento “kwPrimary” del “PrimaryGroup”.
b. Specifica l’area di ricerca per l’elemento “Checkmark”: a sinistra di “kwSecondary” e il più vicino a esso.
c. L’elemento di ricerca Object Collection trova una raccolta di tutti gli oggetti idonei all’interno dell’area di ricerca. Se i segni di spunta si trovano sulla stessa riga, l’elemento “Checkmark” del “SecondaryGroup” potrebbe trovare anche il segno di spunta Primary. Per evitare questo, escludi il segno di spunta primario (elemento “Checkmark” del “PrimaryGroup”) dall’area di ricerca per l’elemento “Checkmark” del “SecondaryGroup”.
d. fai clic su Match.
- Apri la finestra Manage Fields, crea i field corrispondenti e mappali agli elementi di ricerca come segue:
| Name | Type | Search element |
|---|---|---|
| Type of Sick Note | Checkmark group | |
| Primary | Checkmark in the “Type of Sick Note” checkmark group | PrimaryGroup -> Checkmark |
| Secondary | Checkmark in the “Type of Sick Note” checkmark group | SecondaryGroup -> Checkmark |
- elimina gli elementi di ricerca creati automaticamente per i nuovi field.
Estrazione dei dati del medico
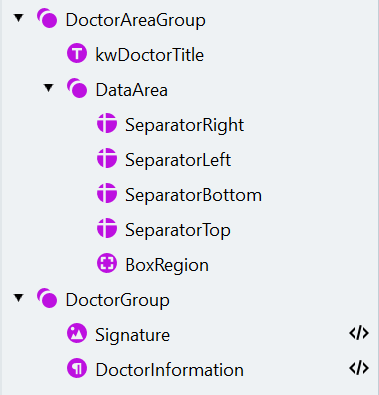
- Crea un elemento Group chiamato “DoctorAreaGroup”. Imposta l’elemento come facoltativo.
- Il riquadro che stiamo cercando contiene un’etichetta. Per trovarla, crea un elemento Static Text chiamato “kwDoctorTitle” (testo da trovare: “Unterschrift des Arztes”).
- All’interno del gruppo “DoctorAreaGroup”, crea un altro gruppo chiamato “DataArea”.
- Il riquadro che contiene le informazioni e la firma del medico è delimitato da una combinazione di quattro separatori. Si trovano attorno all’elemento “kwDoctorTitle”. Tuttavia, dovremmo configurare gli elementi in modo che il programma possa trovarli anche se l’elemento “kwDoctorTitle” non è stato trovato. Nel gruppo “DataArea”, crea quattro elementi di ricerca Separator con le seguenti proprietà:
| Name | Orientation | Minimum length | Search area |
|---|---|---|---|
SeparatorRight | Vertical | 180 | A destra di “kwDoctorTitle”, il più vicino al bordo destro della pagina |
SeparatorLeft | Vertical | 180 | A sinistra di “kwDoctorTitle”, a sinistra di “SeparatorRight” (nel caso in cui “kwDoctorTitle” non sia stato trovato), il più vicino a “SeparatorRight”, sotto “SeparatorRight” (fai clic sull’icona a destra del nome del separatore e seleziona Top Boundary of Region), escludi “SeparatorRight” |
SeparatorBottom | Horizontal | 200 | Sotto “kwDoctorTitle” (con regolazione di -10 punti), a destra di “SeparatorLeft”, a sinistra di “SeparatorRight”, il più vicino al bordo inferiore della pagina (questa impostazione sarà utile nel caso in cui “kwDoctorTitle” non sia stato trovato) |
SeparatorTop | Horizontal | 200 | Sopra “kwDoctorTitle”, a destra di “SeparatorLeft”, il più vicino a “TypeOfSickNoteGroup”, escludi “SeparatorBottom” |
- Potremmo specificare manualmente l’area di ricerca per la firma e le informazioni del medico rispetto ai separatori trovati. Invece di farlo, creeremo un elemento Region che corrisponde all’area delimitata dai separatori. Crea un elemento di ricerca Region chiamato “BoxRegion” e specifica l’area di ricerca: a sinistra di “SeparatorRight”, a destra di “SeparatorLeft”, sopra “SeparatorBottom” e sotto “SeparatorTop”.
- Crea un nuovo gruppo chiamato “DoctorGroup”.
- Per individuare la firma del medico, crea un elemento Object Collection con le seguenti impostazioni all’interno di “DoctorGroup”:
| Property | Value |
|---|---|
| Name | Signature |
| Type | Picture |
| Minimum width | 15 |
| Minimum height | 15 |
| Maximum width | 600 |
| Maximum height | 350 |
| Search Conditions section of the Code Editor | La firma può trovarsi in parte all’esterno del riquadro. Per trovare l’intera immagine, espanderemo l’area di ricerca di 100 dot in ogni direzione: RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect.GetInflated(100dot,100dot); |
- Per estrarre le informazioni testuali nel riquadro, crea un elemento Paragraph con le seguenti impostazioni:
| Property | Value |
|---|---|
| Name | DoctorInformation |
| Maximum line count | 6 |
| Search area | Sopra “kwDoctorTitle”, escludi “Signature” |
| Search Conditions section of the Code Editor | RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect; |
- Fai clic su Match e assicurati che gli elementi vengano trovati correttamente.
- Apri la finestra di dialogo Manage Fields, crea i field corrispondenti e mappali agli elementi di ricerca come segue:
| Name | Type | Search element |
|---|---|---|
| Doctor Information | Text field in the “Doctor” group | DoctorInformation |
| Signature | Image field in the “Doctor” group | Signature |
- Elimina gli elementi di ricerca che sono stati creati automaticamente per i nuovi field.