开始之前
- 在 Activity Editor 中打开 “Sick Note DE” 活动。
- 从文档集里选择其中一个文档。
- 确保已启用元素属性的高级模式。要打开或关闭此模式,请单击 Properties 窗格上的图标。
- 所有上传的文档都已完成预先识别,查看在图像上检测到了哪些对象会很有帮助。单击该图标。如果由于屏幕尺寸原因看不到此图标,请单击图标并选择 Recognized Words。对应的对象将在文档图像上高亮显示。您可以随时在不同类型的高亮对象之间切换。例如,当查找段落时,切换到 Recognized Lines 会很有帮助,而切换到 Separators 则有助于配置 Separator 搜索元素。
- 如果搜索元素位于搜索区域之外,将不会被找到。在文档图像的上下文菜单中启用 Show search area 选项。当您评估匹配结果时,每个元素的搜索区域将以绿色高亮显示。
提取患者的数据
- 单击 Create Element,并从下拉列表中选择 Group 元素。将其名称更改为 “PatientDataArea”。
- 新建的组搜索元素默认设置为必需。如果未找到必需元素,Activity Editor 会报错并中止匹配。这种情况使得当某个活动不适用于某份文档时,可以跳过该活动。不过,在本教程中,我们要创建一个从所有传入文档中提取数据的活动,因此我们希望该组是可选的。在 Under what conditions 部分,将 Element is 的值更改为 Optional。
- 我们要找到包含患者姓名和地址的段落。在德语文档中,我们要查找的段落始终位于标签为 “Name, Vorname … ” 的字段中。我们需要在文档中找到这段文本,并将其用作搜索要提取数据的参考。
a. 可以使用 Static Text 搜索元素来查找关键字。单击 Create Element,并从下拉列表中选择 Static Text 元素。将其名称更改为 “kwPatientTitle”。
b. 在 Properties 窗格 的 Text to find 字段中输入文本 “Name, Vorname”。
c. 单击 Match。处理完成后,您会在文档下方看到 Tree of Hypotheses。请确保 Advanced Designer 已成功找到所需的静态文本。元素名称旁边的绿色圆点表示已在文档上成功找到相应元素。如果您在 Tree of Hypotheses 中单击该元素名称,就会看到文档上对应区域周围出现一个紫色框。
如果未找到某个元素,您会在其名称旁边看到一个橙色圆点,并在文档图像周围看到一个橙色框。请记住,元素的假设质量会影响链中后续元素的状态以及整条链的总体质量。您可以在文档中找到有关假设质量的详细信息。
- 现在让我们找到包含患者姓名和地址的单元格的下边界。我们将使用 Separator 元素来完成此操作。
a. 将一个 Separator 元素添加到该组中,并将其命名为 “SeparatorBottom”。将其最小长度设置为 200。
b. 右键单击该元素,并在上下文菜单中选择 Match Element。您会看到 Tree of Hypotheses 中有许多绿色圆点。它们对应符合搜索条件的不同分隔线。您可以单击每个圆点,在图像上查看相应的对象。
c. 为了缩小搜索条件范围,请为该分隔线指定搜索区域。单击 Match 以找到将用作锚定元素的 “kwPatientTitle” 元素。在 Properties 窗格 的 Where to search 部分,单击 Draw on Image。在文档上选择 “kwPatientTitle” 元素,然后单击向下箭头图标,以指定关键字下方的搜索区域,再单击最近图标以查找最靠近该关键字的分隔线。您可以在文档中找到关于锚定元素的详细说明。
d. 单击 Match,并检查 Advanced Designer 是否已找到位于 “kwPatientTitle” 元素下方的分隔线。您可以通过在 Tree of Hypotheses 部分单击每个元素的名称来检查其对应的假设。 - 标签和分隔线是患者数据的可靠参考元素。但是,如果打印质量太低,标签文本可能无法识别,或者找不到分隔线。为了确保良好的提取结果,我们将搜索位于标签和分隔线之间的一个段落。段落是一个统一的文本块,这意味着即使某些边界元素未找到,它也能被成功找到。
a. 创建一个 Paragraph 搜索元素,并将其命名为 “NameAddressParagraph”。
b. 将 Text alignment 更改为 Left。
c. 患者数据占据两到五行,因此将 Line count 指定为 2 到 5。
d. 为该段落指定搜索区域。这次,您应在 Where to search 部分使用 Add 菜单。该元素应位于 “kwPatientTitle” 元素下方且位于 “SeparatorBottom” 元素上方。
e. 单击 Match。 - 现在我们要提取患者的数据。创建一个名为 “PatientGroup” 的新组元素。
- 患者的姓名可能占用一行或两行。为了捕获元素的多个实例,我们将使用重复组。
a. 创建一个 Repeating Group 搜索元素,并将其命名为 “NameGroup”。将最大重复次数指定为 2。将该元素设为可选。
b. 我们要搜索属于 “NameAddressParagraph” 段落的行。要将该元素的区域指定为搜索区域,请单击文档图像下方的代码编辑器图标,并将以下脚本粘贴到 Code Editor 的 Search Conditions 部分:
d. 我们要查找的文本可能包含大写和小写字母,以及姓名中可能出现的一组标点符号。请配置两个独立的字符集。第一个字符集应包含所有拉丁大写和小写字母。要添加带变音符号的字符,请更改 Unicode 子范围,或将这些字符直接粘贴到 Selected characters 字段中。
e. 另一个字符集应包含以下标点符号: ,-.()’. 我们不希望该字符串只包含标点符号,因此将第二个字符集的 Portion in text, % 设置为 40%。此属性定义了某个字符集中字符所允许的最大百分比。
默认设置允许字符串中最多包含 30% 未包含在任何字符集中的字符。即使某些字符识别错误或未包含在字符集中(例如带变音符号的字符),这也有助于找到字符串。您可以通过更改 Properties 窗格 中的 Allowed errors 值来调整此设置。
g. 为 “NameLine” 元素指定搜索区域:位于 “kwPatientTitle” 元素下方,且距离其最近。
h. 单击 Match 并查看 Tree of Hypotheses。您会看到找到了两个字符串。但是,第二个字符串包含患者的地址。
i. 为了将地址从搜索结果中排除,我们将检查第一个字符串是否同时包含名字和姓氏。这可以通过添加一个简单的脚本搜索条件来实现。选择 “NameLine” 搜索元素并打开 Search Conditions 代码编辑器。
j. 我们假设,如果第一行包含逗号和空格,则其中包含完整姓名。如果它包含完整姓名,我们就不希望再搜索重复组的第二个实例。将以下脚本粘贴到编辑器中:
- 在步骤 7 中提取的患者姓名将映射到 “Name” 字段。我们还将提取并映射患者地址。
a. 在 “PatientGroup” 中,创建一个名为 “Address” 的 Character String 搜索元素,其字符集配置与 “NameLine” 元素相同。
b. 使用代码为该元素指定搜索区域:地址必须位于 “NameLine” 下方;如果未找到该元素,则位于 “NameAddressParagraph” 元素第一行的下方。
d. 单击 Match。 搜索元素结构应如下所示:
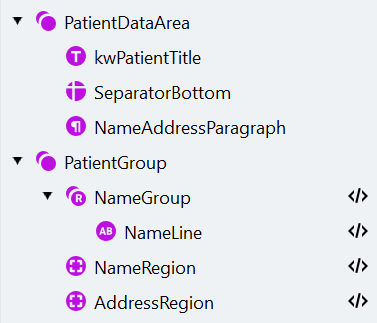
- 打开 Manage Fields 对话框,创建相应字段,并按如下方式将其映射到搜索元素:
| Name | Type | Search element |
|---|---|---|
| Name | ”Patient” 组中的 Text 字段 | NameLine |
| Address | ”Patient” 组中的 Text 字段 | Address |
- 删除为新字段自动创建的搜索元素。
提取病假条的类型
- 创建一个名为 “TypeOfSickNoteGroup” 的 Group 元素。将该元素设置为可选。
- 为了存储两个勾选状态的信息,创建一个 Repeating Group 搜索元素,并将其命名为 “PrimaryGroup”。 a. 较好的做法是限制该元素组的搜索区域。使用代码指定搜索区域:在 “PatientGroup” 元素的右侧、在 (稍后将创建的) “DoctorAreaGroup” 元素的上方。**注意:**在使用尚未创建的元素时,一定要指定 “Exists” 条件。
Checkmark,Checkmark state:Checked,Minimum height:10,Maximum width:20,Maximum height:20。指定该元素位于 “kwPrimary” 元素的左侧且与之最近。
d. 单击 Match。
- 复制并粘贴 “PrimaryGroup” 组,将复制的组重命名为 “SecondaryGroup”。将该组设为必需。
- 编辑 “SecondaryGroup”。 a. 将 “kwPrimary” 元素重命名为 “kwSecondary”,并将要查找的文本设置为 “Folgebescheinigung”。指定搜索区域:位于 “PrimaryGroup” 中 “kwPrimary” 元素的下方。 b. 为 “Checkmark” 元素指定搜索区域:位于 “kwSecondary” 的左侧且与之最近。 c. Object Collection 搜索元素会在搜索区域内找到所有合适对象的集合。如果复选标记位于同一行,“SecondaryGroup” 的 “Checkmark” 元素也可能找到主复选标记。为避免这种情况,请将主复选标记 (“PrimaryGroup” 的 “Checkmark” 元素) 从 “SecondaryGroup” 的 “Checkmark” 元素的搜索区域中排除。 d. 单击 Match。
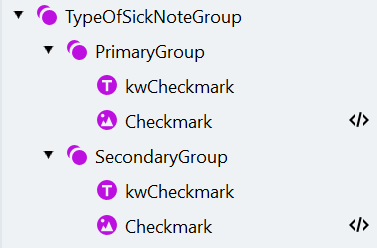
- 打开 Manage Fields 窗口,创建相应字段并按如下方式将其映射到搜索元素:
| Name | Type | Search element |
|---|---|---|
| Type of Sick Note | Checkmark group | |
| Primary | “Type of Sick Note” 复选标记组中的复选标记 | PrimaryGroup -> Checkmark |
| Secondary | “Type of Sick Note” 复选标记组中的复选标记 | SecondaryGroup -> Checkmark |
- 删除为新字段自动创建的搜索元素。
提取医生数据
- 创建一个名为 “DoctorAreaGroup” 的 Group 元素。将该元素设置为可选。
- 我们要查找的框中包含一个标签。要找到它,请创建一个名为 “kwDoctorTitle” 的 Static Text 元素(要查找的文本:“Unterschrift des Arztes”)。
- 在 “DoctorAreaGroup” 组内,再创建一个名为 “DataArea” 的组。
- 包含医生信息和签名的框是由四条分隔线组合而成的。它们位于 “kwDoctorTitle” 元素的四周。不过,我们应当以一种方式配置这些元素,使程序即使在没有找到 “kwDoctorTitle” 元素的情况下也能找到它们。在 “DataArea” 组中,创建四个具有以下属性的 Separator 搜索元素:
| Name | Orientation | Minimum length | Search area |
|---|---|---|---|
SeparatorRight | Vertical | 180 | 位于 “kwDoctorTitle” 右侧,最接近页面右边缘 |
SeparatorLeft | Vertical | 180 | 位于 “kwDoctorTitle” 左侧,位于 “SeparatorRight” 左侧(如果未找到 “kwDoctorTitle”),最接近 “SeparatorRight”,位于 “SeparatorRight” 下方(单击分隔线名称右侧的图标并选择 Top Boundary of Region),排除 “SeparatorRight” |
SeparatorBottom | Horizontal | 200 | 位于 “kwDoctorTitle” 下方(向上调整 -10 点),位于 “SeparatorLeft” 右侧,位于 “SeparatorRight” 左侧,最接近页面下边缘(如果未找到 “kwDoctorTitle”,此设置会很有用) |
SeparatorTop | Horizontal | 200 | 位于 “kwDoctorTitle” 上方,位于 “SeparatorLeft” 右侧,最接近 “TypeOfSickNoteGroup”,排除 “SeparatorBottom” |
- 我们可以基于找到的分隔线,手动指定医生签名和医生信息的搜索区域。但我们不会这么做,而是创建一个 Region 元素,对应由这些分隔线围成的区域。创建一个名为 “BoxRegion” 的 Region 搜索元素,并指定搜索区域:位于 “SeparatorRight” 左侧,位于 “SeparatorLeft” 右侧,位于 “SeparatorBottom” 上方,位于 “SeparatorTop” 下方。
- 创建一个名为 “DoctorGroup” 的新组。
- 为了定位医生的签名,在 “DoctorGroup” 内创建一个具有以下设置的 Object Collection 元素:
| Property | Value |
|---|---|
| Name | Signature |
| Type | Picture |
| Minimum width | 15 |
| Minimum height | 15 |
| Maximum width | 600 |
| Maximum height | 350 |
| Search Conditions section of the Code Editor | 签名可能部分位于该框外部。为了找到整个图像,我们将在各个方向上将搜索区域扩展 100 点:RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect.GetInflated(100dot,100dot); |
- 要提取该框中的文本信息,请创建一个具有以下设置的 Paragraph 元素:
| Property | Value |
|---|---|
| Name | DoctorInformation |
| Maximum line count | 6 |
| Search area | 位于 “kwDoctorTitle” 上方,排除 “Signature” |
| Search Conditions section of the Code Editor | RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect; |
- 单击 Match,并确认这些元素均被正确找到。
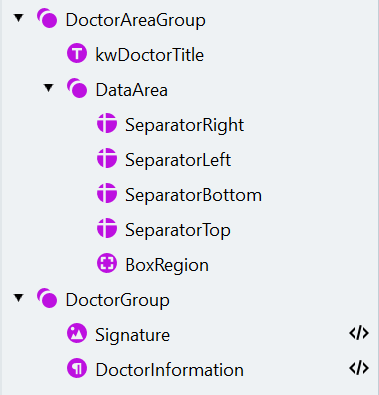
- 打开 Manage Fields 对话框,创建相应字段,并按如下方式将它们映射到搜索元素:
| Name | Type | Search element |
|---|---|---|
| Doctor Information | ”Doctor” 组中的文本字段 | DoctorInformation |
| Signature | ”Doctor” 组中的图像字段 | Signature |
- 删除为新字段自动创建的搜索元素。