提取签发日期
- 在 Fields 选项卡中打开 Manage Fields 对话框,并选择要在此活动中使用的 “Date” 字段。点击 Save。
- 转到 Search Elements 选项卡。您将看到为 “Date” 字段创建的 Date 类型搜索元素。该元素会自动映射到该字段。
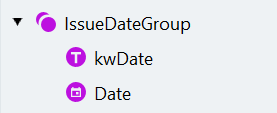
- 创建一个名为 “IssueDateGroup” 的 Group 搜索元素。将该元素设为可选。
- 添加一个名为 “kwDate” 的 Static Text 元素,用于查找标签,以帮助我们定位实际日期。
- 此文档类别包含荷兰语或法语的文档,因此标签文本有多个选项。您可以在 Text to find 对话框中将每个选项分别输入到新的一行。第一行输入文本 “Date”,第二行输入 “Datum”。
- 禁用 Search for parts of words 选项。
- 将 “Date” 搜索元素拖放到该组中,并将其放在 “kwDate” 元素下面。
- 为 “Date” 元素指定搜索区域。
a. 删除在创建该元素时自动添加的 Nearest to 关系。 b. 选择 “kwDate” 元素作为与我们要查找的元素最近的元素。
c. 日期可能位于关键字的右侧或下方。在 “kwDate” 元素下方指定搜索区域。
d. 搜索区域还应包含关键字所在的那一行。点击元素名称右侧的底部边界图标,并选择 Top Boundary of Region。由于各行可能不在同一水平线上,将 Below 值设置为 -10,以便将搜索区域稍微向上扩展到该行之上。 - 点击 Match,以确保日期被正确定位。
提取病假日期
您不仅可以对位于文档表格中的字段使用 Table Cell 元素。如果您需要从表单中提取数据,而内容位于类似的方框或类表格结构中,它也会很有用。如果这些方框具有清晰的分隔线,Table Cell 元素会非常有效。
-
打开 Manage Fields 对话框,并向当前活动添加以下字段:
- Start Date
- End Date
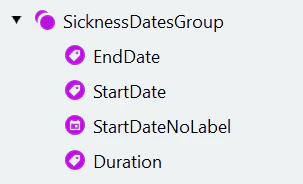
- 转到 Search Elements 选项卡,为开始日期提取创建 Group 元素。为组中包含的元素设置以下参数:
| Parameter | Value |
|---|---|
| Group search element: | |
| Name | StartDateGroup |
| Static Text search element: | |
| Name | kwStartDate |
| Text to find | Vanaf / From, A partir du, Van |
| Search for parts of words | Disabled |
| Table Cell search elements: | |
| Name | StartDateDay |
| Search pattern | Number |
| Character count | {1, 1, 3, 3} |
| Search for parts of words | Disabled |
| Search area | Below the “kwStartDate” element, nearest to “kwStartDate” |
| Table Cell search element: | |
| Name | StartDateMonth |
| Search pattern | Number |
| Character count | {1, 1, 3, 3} |
| Search for parts of words | Disabled |
| Search area | Below the “kwStartDate” element, right of “StartDateDay”, nearest to “StartDateDay” |
| Table Cell search element: | |
| Name | StartDateYear |
| Search pattern | Number |
| Character count | {2, 2, 4, 4} |
| Search for parts of words | Disabled |
| Search area | Below the “kwStartDate” element, right of “StartDateMonth”, nearest to “StartDateMonth” |
Table Cell 元素会按原样返回单元格中的文本。在此情况下,搜索模式包含一个 Number,它只识别数字,因此该元素返回的文本将是一个数字。
- 创建 “StartDateGroup” 元素的副本,并将其重命名为 “EndDateGroup”。
- 重命名组的子元素:将 “kwStartDate” 改为 “kwEndDate”,将 “StartDateDay” 改为 “EndDateDay”,将 “StartDateMonth” 改为 “EndDateMonth”,将 “StartDateYear” 改为 “EndDateYear”。
- 将 “kwEndDate” 元素的 Text to find 更改为 “Tot en met / Till and incl., Jusqu’ au, Tot en met”。
- 为 “EndDateDay” 元素指定搜索区域。它应位于 “kwEndDate” 元素的下方,并且最靠近该元素。删除其他关系。
-
打开 Manage Fields 对话框,并添加名为 “Start Date Composed” 的 Data Composition Field。将以下元素映射到字段:
- “StartDateDay” 到
Day - “StartDateMonth” 到
Month - “StartDateYear” 到
Year
- “StartDateDay” 到
-
创建名为 “End Date Composed” 的 Data Composition Field。将以下元素映射到字段:
- “EndDateDay” 到
Day - “EndDateMonth” 到
Month - “EndDateYear” 到
Year
- “EndDateDay” 到
- 将 “Start Date Composed” 和 “End Date Composed” 数据组合字段映射到 “Start Date” 和 “End Date” 字段。
提取病假条类型
- 在 Fields 选项卡上打开 Manage Fields 对话框,并启用 “Type of Sick Note” 复选标记组。启用组中的 “Primary” 和 “Secondary” 复选标记,以便在当前活动中使用。点击 Save。
- 构建一个与德国文档类似的结构,但请注意,在荷兰和比利时文档中,标签(复选标记旁边的文本)是在前面的。此类组的子元素顺序确实很重要。a. 创建一个名为 “TypeOfSickNoteGroup” 的 Group 元素。 b. 复制此组并将其重命名为 “PrimaryGroup”。将其放入 “TypeOfSickNoteGroup” 中。 c. 向 “PrimaryGroup” 组添加一个名为 “kwCheckmark” 的 Static Text 元素。 d. 将要查找的文本设置为 “eerste / Primary, première, primair”。
在这些文档中,复选标记旁边的文本位于复选标记的左侧,因此我们将搜索区域设置在其左侧,而不是右侧。
| Parameter | Value |
|---|---|
| Static Text search element: | |
| Name | Checkmark |
| Text to find | X |
| Character count | {1, 1, 3, 3} |
| Search for parts of words | Disabled |
| Search area | Right of “kwCheckmark”, nearest to “kwCheckmark” |
| Static Text search element: | |
| Name | XMark |
| Text to find | X |
| Character count | {1, 1, 3, 3} |
| Search for parts of words | Disabled |
| Search area | Below the “kwCheckmark” top boundary, Below value = -15, Left of “kwCheckmark”, Above the “kwCheckmark” bottom boundary, Above value = -15, Nearest to “kwCheckmark” |
| Under what conditions | Do not find element if “Checkmark” is found |
| Region search element: | |
| Name | CheckmarkRegion |
| Search Conditions section of the Code Editor | if Checkmark.IsFound then RSA: Checkmark.Rect; else if XMark.IsFound then RSA: XMark.Rect; else DontFind; |
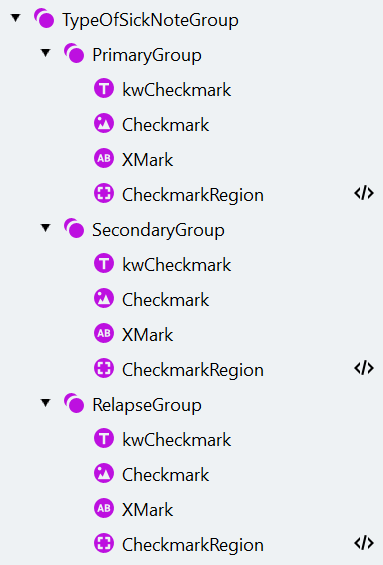
- 打开 Manage Fields 窗口,在 “Type of Sick Note” 复选标记组中添加一个 “Relapse” 复选标记。启用组中的所有复选标记以在当前活动中使用,然后点击 Save。
- 将这些复选标记映射到相应的 Region 元素,并删除在启用这些字段时自动创建的元素。