跳轉到主要內容模糊區間(Fuzzy interval) 是一種工具,讓程式能根據假設的長度來評估其品質。模糊區間可以用長度單位(點、毫米等)或字元數(如針對行)來衡量。對於一個模糊區間,必須指定四個數值,用以決定可能值與最佳值的範圍。為了簡化操作,程式中提供了一個易於使用的模糊區間編輯器。
假設有一個模糊區間 {f1,f2,f3,f4},且偵測到的字串長度(以字元計,或偵測到空白時以點計)為 L。若長度 L 位於 f2 與 f3 之間(即 L>=f2 and L<=f3),則該假設的品質為 1。若長度位於 f1 與 f2 之間,則假設的品質會由 0 線性變化為 1(Quality(f1) = 0, Quality(f2)=1)。同樣地,若長度位於 f3 與 f4 之間,則假設的品質會由 1 線性變化為 0(Quality(f3) = 1, Quality(f4) = 0)。若長度不在 f1 與 f4 的範圍內(即 L<f1 or L>f4),則假設的品質為 0(Quality(L) = 0)。針對偵測到的物件,其假設品質會再乘上 Character count 屬性的數值,而該屬性會根據偵測到的物件長度來選取。
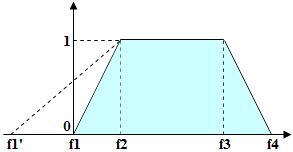
注意: 對於多個元素所組成的任一假設鏈,其品質是透過將鏈中每個元素的假設品質相乘來計算的。若鏈條足夠長,而各個假設的品質評估因為限制過於嚴格而偏低,則整條假設鏈的最終品質也可能變得非常低。
因此,建議盡量確保所選假設具有盡可能高的品質評估值。另一方面,又必須能夠依品質區分不同的假設,以便選出最佳者。因此,必須以適當的方式設定模糊區間(這些是用於假設評估的數學函式),以避免對可接受的假設施加過大的懲罰。
模糊區間的左邊界也可以使用負值(即使實際上不存在負長度的字串)。這有助於讓 (0, 1) 區間上的品質曲線不那麼陡峭,從而降低品質懲罰。如果需要為此參數設定一個下限(例如字串的長度不得小於 10 個字元,而其長度的模糊區間為 [-10,20,30,40}),則可以在 Hypothesis Evaluation 中直接設定 Value.Length >=10 來達成。
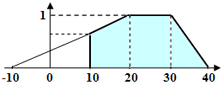 我們不建議將區間邊界設定得過於嚴格。這在處理品質不一的影像時尤為重要。例如,在某些影像上,可能因為原始文件品質不佳或掃描設定的關係,導致字母之間出現空白。在這種情況下,程式可能會將一個字元解讀為多個字元;若該區間設定過於嚴格,就會導致該假設的品質大幅下降。結果,程式可能會捨棄該假設(儘管其本質上可能是正確的),而選擇另一個假設。因此,若需要透過比較長度在多個假設之間進行選擇,建議在 Hypothesis Evaluation 中使用額外條件來完成。
我們不建議將區間邊界設定得過於嚴格。這在處理品質不一的影像時尤為重要。例如,在某些影像上,可能因為原始文件品質不佳或掃描設定的關係,導致字母之間出現空白。在這種情況下,程式可能會將一個字元解讀為多個字元;若該區間設定過於嚴格,就會導致該假設的品質大幅下降。結果,程式可能會捨棄該假設(儘管其本質上可能是正確的),而選擇另一個假設。因此,若需要透過比較長度在多個假設之間進行選擇,建議在 Hypothesis Evaluation 中使用額外條件來完成。