概觀
- 建立一個提示式擷取活動。
- 設定 LLM 連線。
- 撰寫有效的擷取提示。
- 定義輸出格式與結構。
- 套用嚴格度與驗證規則。
- 測試並微調您的擷取。
- 從發票中擷取供應商資訊
- 表頭層級的文件資料擷取
- 半結構化文件處理
- 版面配置多變的文件
先決條件
- 存取 ABBYY Vantage Advanced Designer 的權限。
- 已完成 LLM 連線設定。請參閱如何設定 LLM 連線。
- 一個已載入範例文件的文件 Skill。
- 對 JSON 結構有基本認識。
- 您想要擷取之資料的欄位定義。
了解提示式擷取
什麼是提示式擷取?
- Role:LLM 應該扮演的角色 (例如:“data extraction model”) 。
- Instructions:如何擷取與格式化資料。
- Output Structure:結果所需的精確 JSON 格式。
- Rules:處理模糊或缺漏資料的規則。
優點
- 無需訓練資料:只要進行提示工程即可運作。
- 具彈性:容易新增或修改欄位。
- 能處理變化:LLM 能理解不同的文件格式。
- 設定快速:比訓練傳統機器學習模型更快。
- 自然語言:可以用一般英文撰寫說明指令。
限制
- 成本:每次擷取都會觸發 LLM API 呼叫。
- 速度:對於簡單文件,比傳統擷取方式更慢。
- 一致性:不同執行之間的結果可能會略有差異。
- 上下文限制:篇幅很長的文件可能需要額外處理。
步驟 1:新增提示式活動
- 在 ABBYY Vantage Advanced Designer 中開啟您的文件 Skill。
- 在左側面板中,找到 EXTRACT FROM TEXT (NLP)。
- 尋找並按一下 Prompt-based。
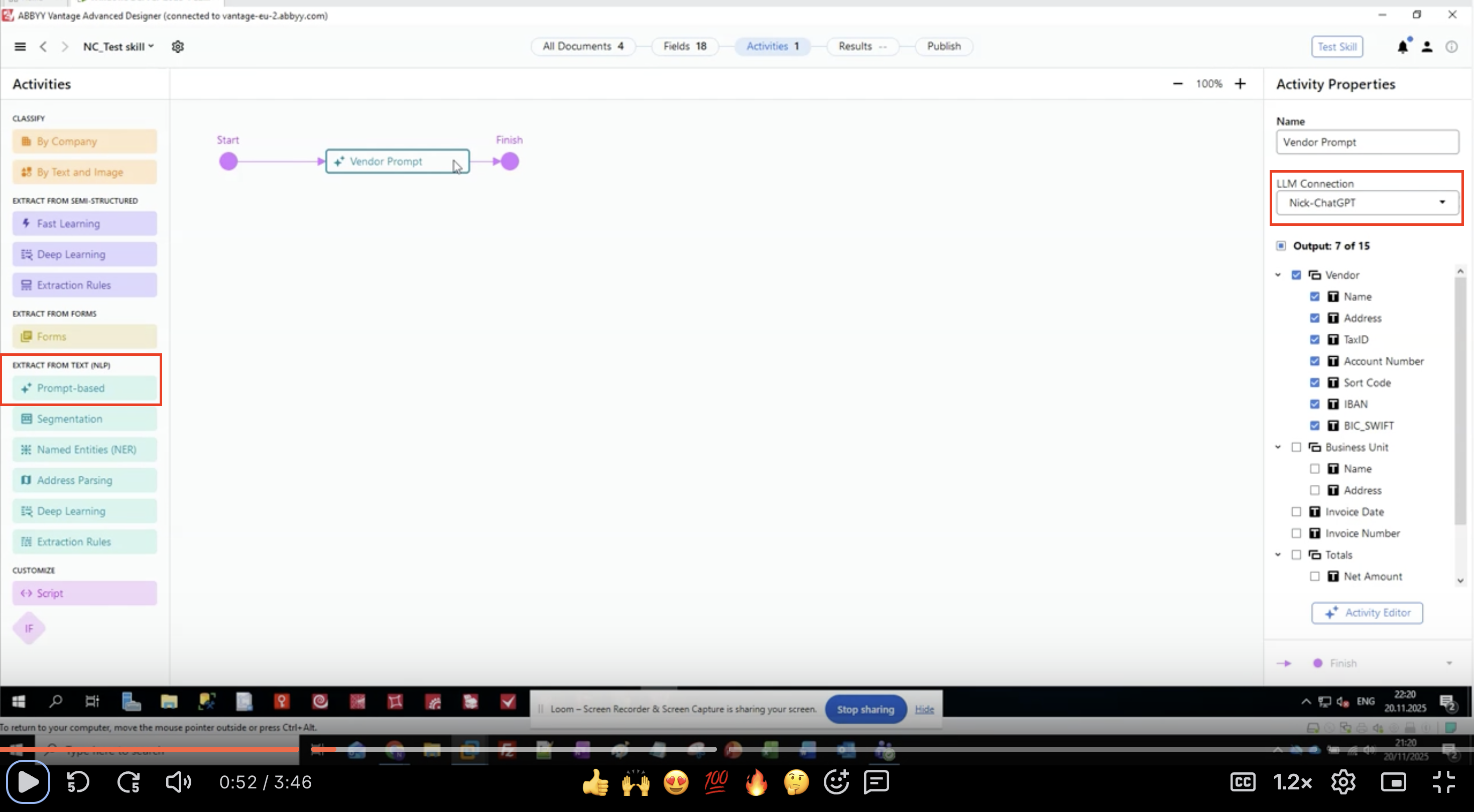
- 此活動會出現在您的工作流程畫布中。
- 將它連接在輸入與輸出活動之間。
步驟 2:設定 LLM 連線
- 在工作流程中選取提示式活動。
- 在右側的 Activity Properties 面板中找到 LLM Connection。
- 按一下下拉式選單。
- 從清單中選取已設定好的 LLM 連線。
- 範例:
Nick-ChatGPT、Microsoft Foundry、Production GPT-4
- 範例:
- 確認已選取正確的連線。
步驟 3:定義輸出欄位
- 在 Activity Properties 面板中,找到 Output 區段。
- 您會看到欄位群組與欄位所組成的階層式清單。
- 在這個範例中,我們要擷取供應商資訊:
- 供應商 (Vendor)
- 名稱
- 地址
- 稅務識別號碼
- 帳戶號碼
- Sort Code
- IBAN
- BIC_SWIFT
- 業務單位 (Business Unit)
- 名稱
- 地址
- 發票日期 (Invoice Date)
- 發票號碼 (Invoice Number)
- 總計 (Totals)
- 淨金額
- 供應商 (Vendor)
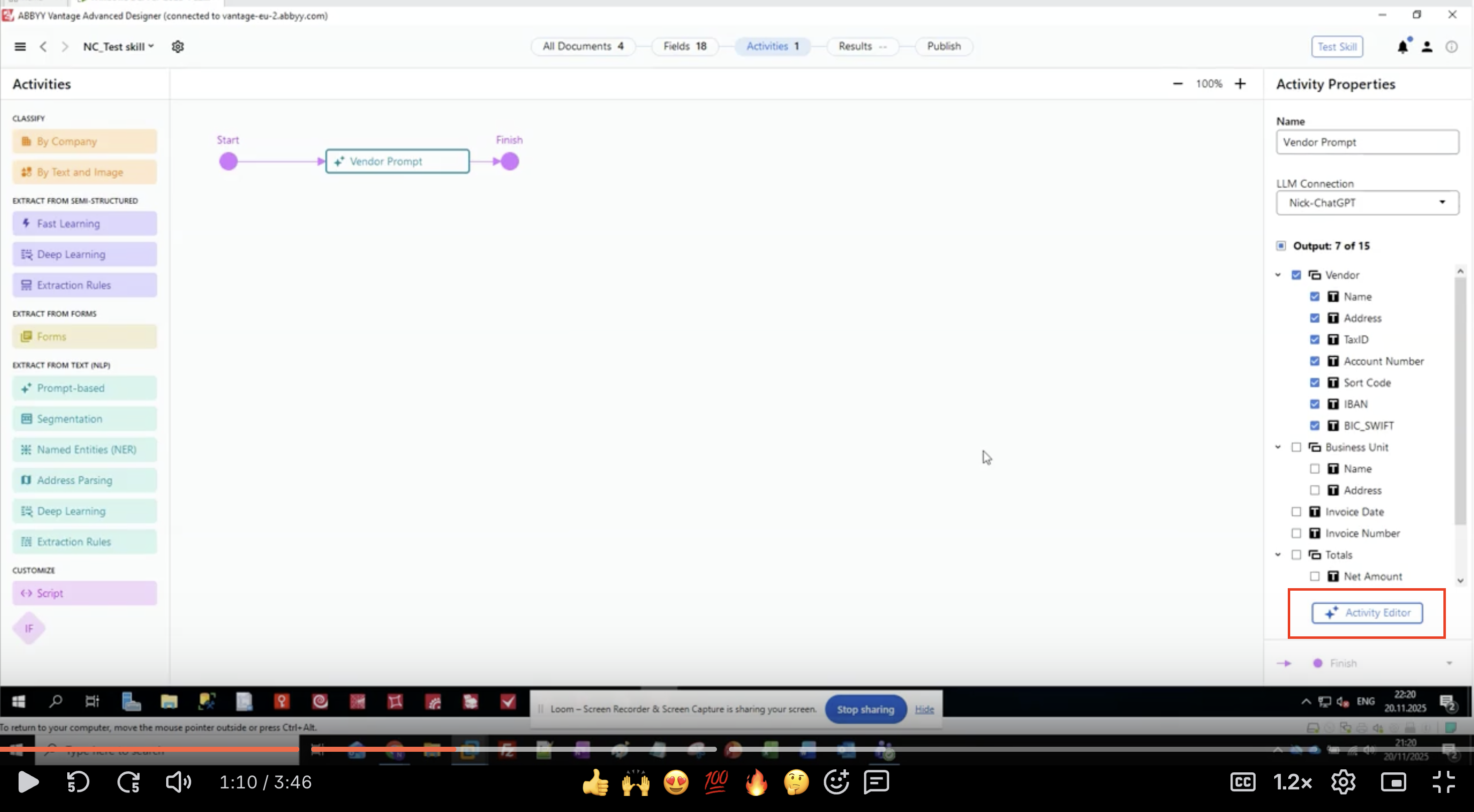
- 按一下 Activity Editor 按鈕,以開始設定提示。
步驟 4:撰寫角色定義
- 在 Activity Editor 中,您會看到 Prompt Text 介面。
- 從 ROLE 段落開始:
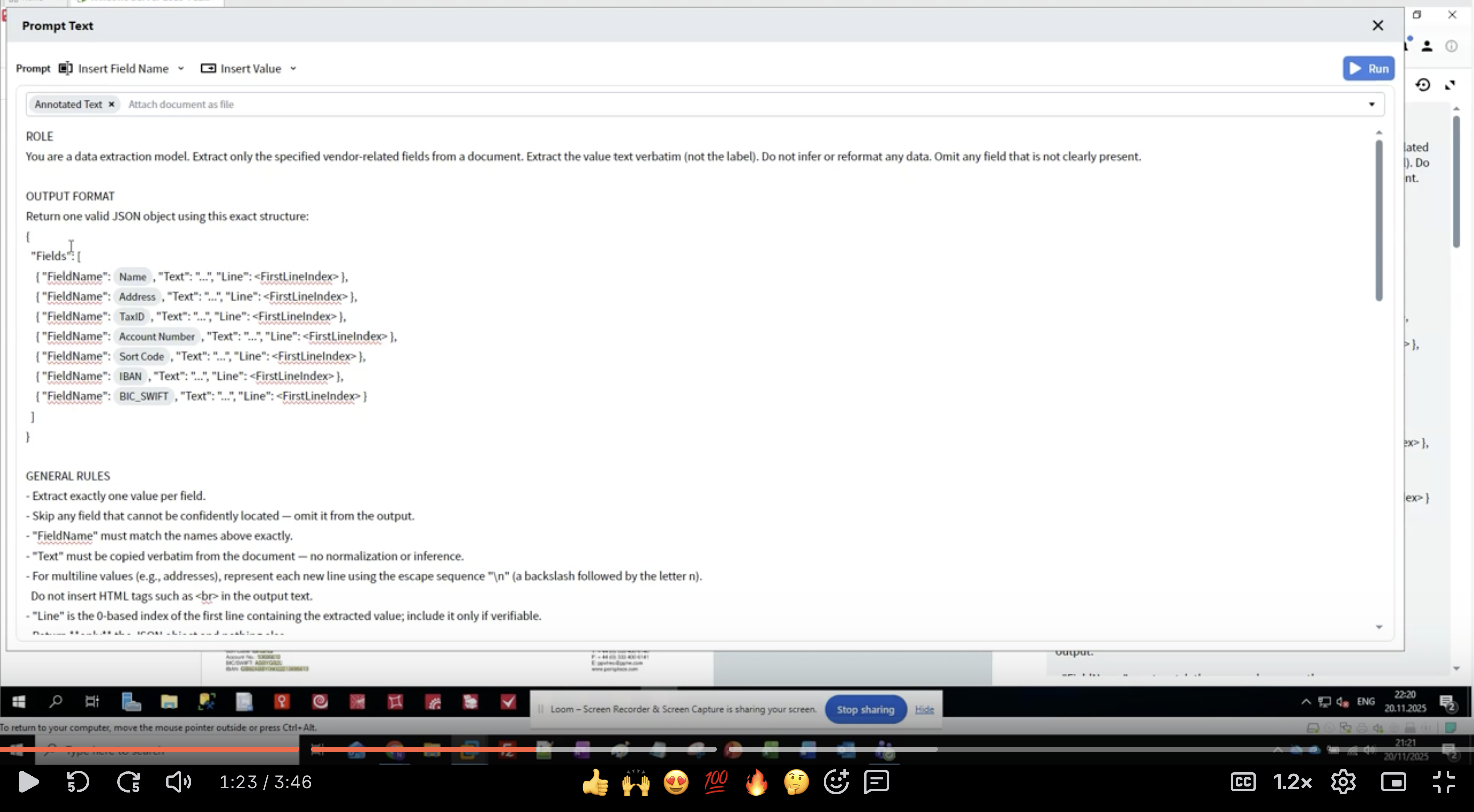
- 具體說明:使用「data extraction model」告訴 LLM 其用途。
- 定義範圍:使用「vendor-related fields」限制要擷取的內容。
- 設定預期:使用「value text verbatim」以避免重新格式化。
- 處理遺漏資料:使用「Omit any field that is not clearly present」。
- 保持角色說明清楚且精簡。
- 使用祈使句 (「Extract」、「Do not infer」) 。
- 明確說明「不要做什麼」。
- 定義如何處理邊界案例。
步驟 5:定義輸出格式
- 在 ROLE 區段下方新增 OUTPUT FORMAT 標題。
- 定義 JSON 結構:
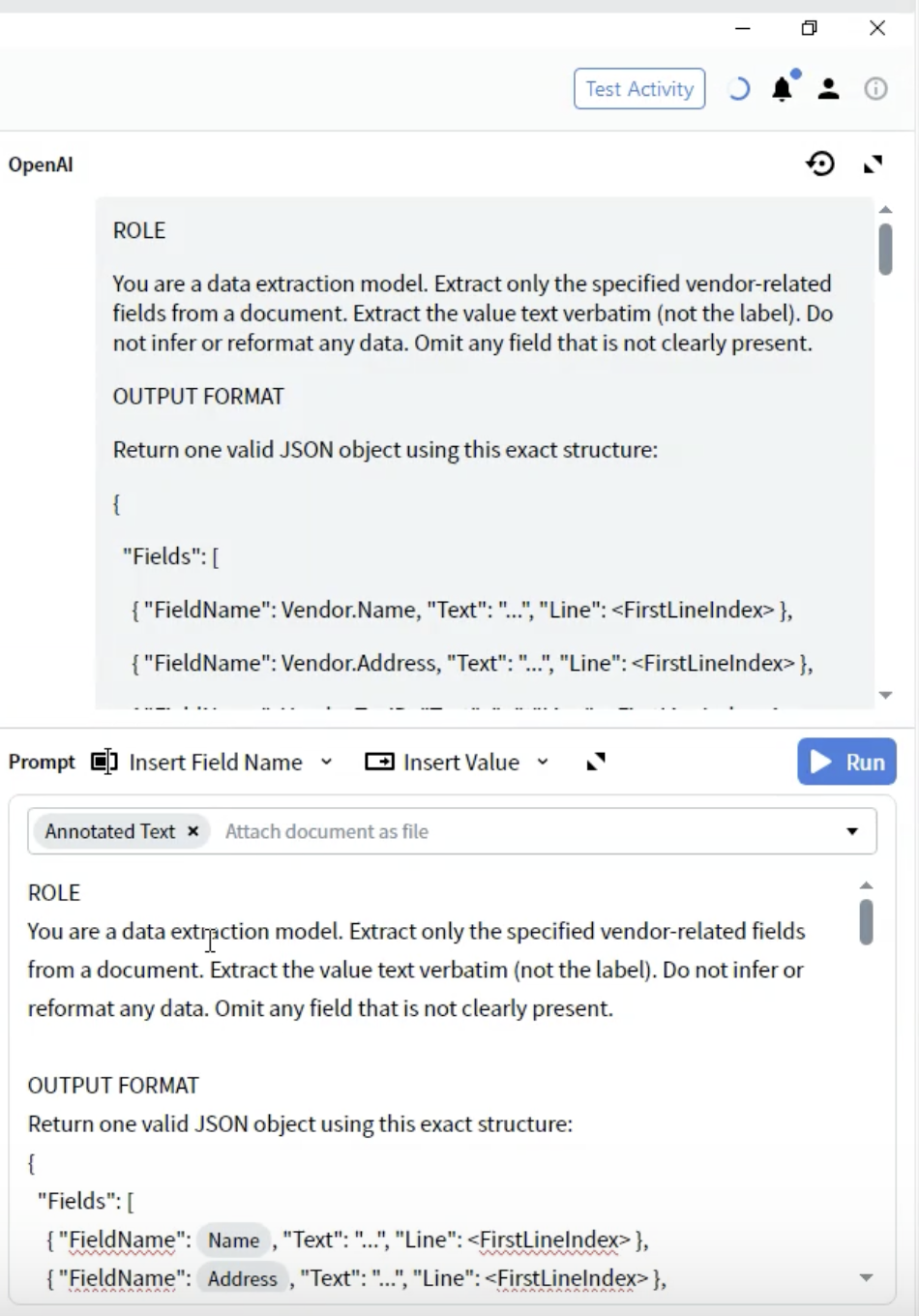
- FieldName:必須與您的欄位定義完全相符 (例如:
Vendor.Name) 。 - Text:擷取出的值,以字串形式表示。
- Line:值在文件中出現的位置,其行索引從 0 起算。
- 請使用您輸出設定中的完整欄位名稱。
- 即使某些欄位可能沒有值,也要全部包含。
- 結構必須是有效的 JSON。
- 行號有助於驗證與疑難排解。
步驟 6:新增欄位特定的擷取規則
- 辨識模式:列出每個欄位的替代標籤。
- 格式規格:描述要擷取的精確格式。
- 位置提示:說明通常在哪裡可以找到這些資料。
- 排除項目:定義不要擷取的內容。
- 為規則編號以提升清晰度。
- 提供多個標籤變化形式。
- 明確指明資料歸屬 (供應商端 vs. 客戶端) 。
- 在括號中加入格式範例。
- 明確說明相關欄位 (例如,“Ignore IBAN — it has its own field”) 。
步驟 7:套用嚴格性規則
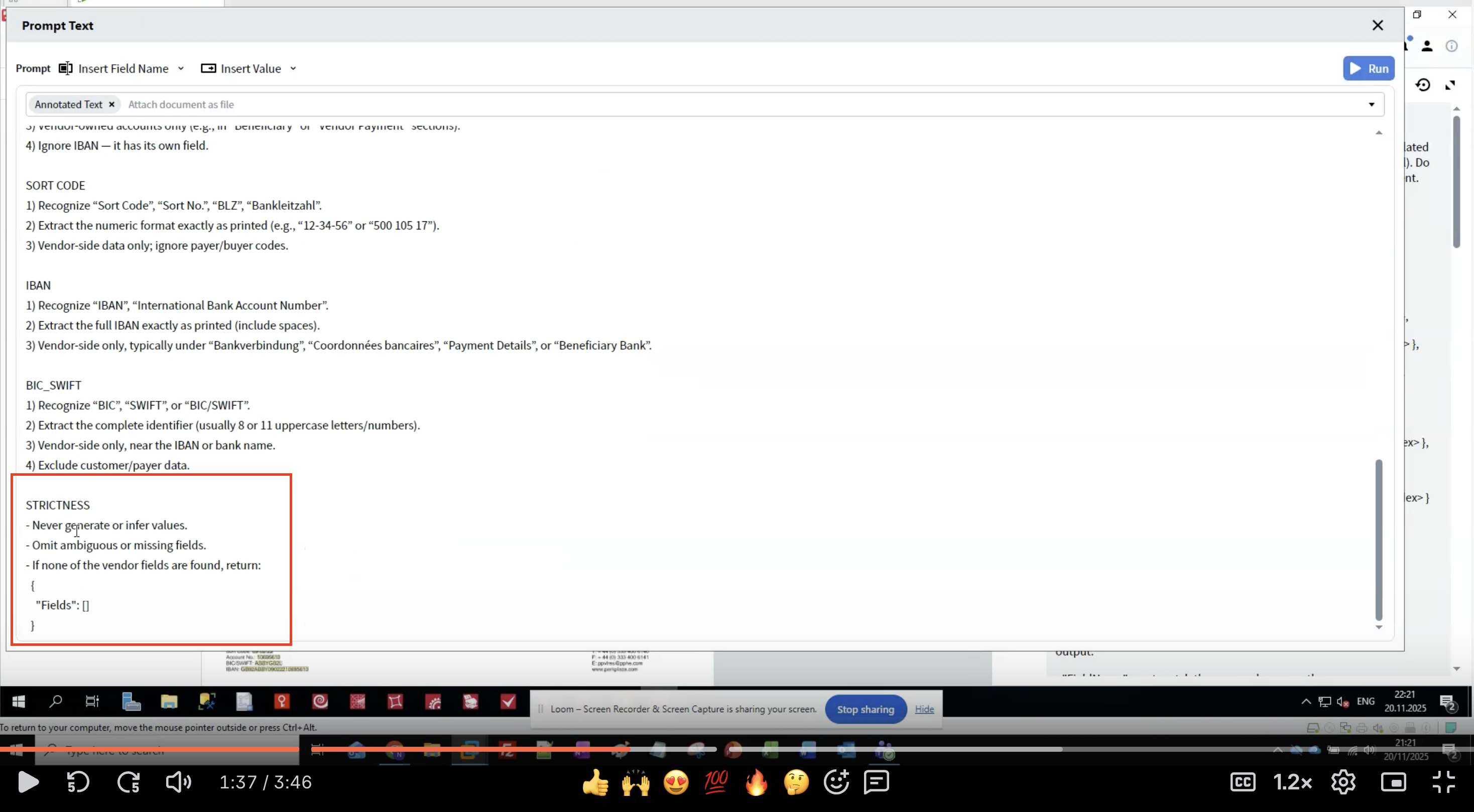
- 防止幻覺生成:LLM 可能產生看似合理但實際錯誤的資料。
- 確保一致性:明確規則可減少多次執行結果的差異。
- 處理遺漏資料:定義在找不到欄位時應該怎麼做。
- 維護資料完整性:逐字擷取可保留原始格式。
- 絕不可生成不存在於文件中的資料。
- 寧可省略不確定的擷取結果,也不要臆測。
- 若找不到任何欄位,則傳回空結構。
- 必須與欄位名稱完全相符。
- 保留原始文字格式。
步驟 8:選擇文件格式
- 在 Activity Editor 中找到 Prompt 下拉選單。
- 您會看到多種將文件提供給 LLM 的方式選項。
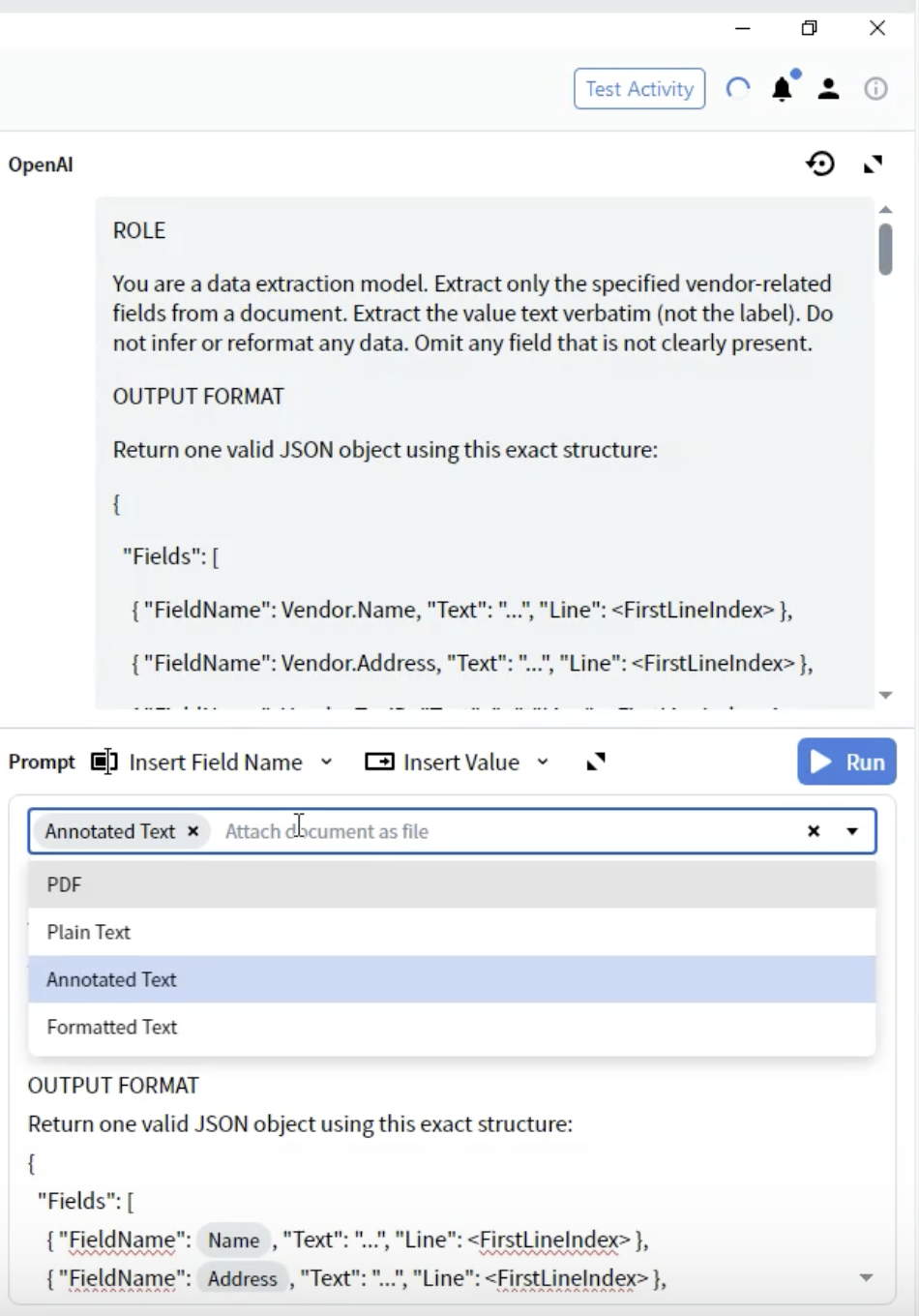
- PDF:原始 PDF 檔案
- 適用於:版面配置很重要的文件
- 注意事項:檔案較大,且部分 LLM 對 PDF 的支援有限
- Plain Text:未格式化的文字擷取
- 適用於:單純的純文字文件
- 注意事項:會遺失所有格式與版面資訊
- Annotated Text ⭐ (推薦)
- 適用於:大多數文件類型
- 注意事項:以文字為基礎,同時保留結構
- 優點:在結構與效能之間提供最佳平衡
- Formatted Text:保留基本格式的文字
- 適用於:部分格式仍然重要的文件
- 注意事項:介於 Plain 和 Annotated 之間的折衷方案
- 選擇 Annotated Text 以獲得最佳效果。
步驟 9:測試您的擷取
執行 Activity
- 關閉 Activity Editor。
- 前往 All Documents 分頁。
- 選擇一份測試文件。
- 按一下 Test Activity 或 Run 按鈕。
- 等待 LLM 處理文件。
- 處理時間:通常為 5–30 秒,視文件複雜度而定。
- 等待 API 回應時,您會看到載入指示器。
檢閱結果
- 介面會切換為 Predictive view。
- 檢閱顯示擷取欄位的 Output 面板。
- 按一下每個欄位即可檢視:
- 擷取的值
- 信心度 (若有提供)
- 文件影像上對應區域的醒目標示
- ✅ 所有預期的欄位都已填入
- ✅ 值與文件內容完全相符
- ✅ 沒有由幻覺或推測產生的資料
- ✅ 正確處理多行欄位
- ✅ 遺漏的欄位被省略 (而非以錯誤資料填入)
常見結果模式
步驟 10:精煉你的提示詞
常見問題與解決方案
- 解決方案:加入更明確的位置信息提示。
- 範例:「僅限供應商端;排除客戶/買方地址」
- 解決方案:強調必須逐字擷取。
- 範例:「請完全依照原樣擷取數字格式 (例如:‘12-34-56’) 」
- 解決方案:強化嚴格規則。
- 範例:「絕不要產生或推斷值。若不存在則省略。」
- 解決方案:指定跳脫字元序列。
- 範例:「對於多行值,使用
\n作為換行符號」
- 解決方案:確認欄位名稱完全一致。
- 範例:使用
Vendor.Account Number而非AccountNumber
迭代改進流程
- 使用多個文件測試:不要只針對單一範例最佳化。
- 記錄模式:注意哪些規則有效、哪些需要進一步調整。
- 加入具體範例:在括號中包含格式示例。
- 調整嚴格程度:根據過度/不足擷取的情況進行調整。
- 測試邊界案例:嘗試含有缺失欄位、版面異常的文件。
優化範例
瞭解擷取流程
提示式擷取的運作方式
- 文件轉換:您的文件會轉換成所選格式 (建議使用 Annotated Text) 。
- 提示組合:會將您的角色、輸出格式、欄位規則與嚴格性規則加以整合。
- API 呼叫:提示與文件會透過您的連線傳送給 LLM。
- LLM 處理:LLM 會讀取文件,並依照您的指示擷取資料。
- JSON 回應:LLM 會以指定的 JSON 格式傳回結構化資料。
- 欄位對應:Vantage 會將 JSON 回應對應到您定義的輸出欄位。
- 驗證:行號與信心分數 (若有提供) 可協助驗證正確性。
Token 使用量與成本
- 文件長度:文件愈長,使用的 token 愈多。
- 提示複雜度:提示愈詳細,token 數就會增加。
- 格式選擇:相較於 PDF,Annotated Text 通常更有效率。
- 欄位數量:欄位越多,提示就越長。
- 在提示中使用精簡但清楚的語句。
- 避免重複相同指示。
- 移除不必要的範例。
- 針對相關資料考慮將欄位分組。
最佳做法
提示撰寫
- ✅ 使用清楚的祈使句 (“Extract”、“Recognize”、“Omit”) 。
- ✅ 為每個欄位提供多種標籤名稱變化。
- ✅ 在括號中加入格式範例。
- ✅ 明確說明不要擷取的內容 (排除項目) 。
- ✅ 為規則編號以便參考。
- ✅ 全文使用一致的術語。
- ❌ 使用含糊的指示 (“get the name”) 。
- ❌ 假設 LLM 了解特定領域的慣例。
- ❌ 撰寫過長、過於複雜的句子。
- ❌ 在文件不同部分前後矛盾。
- ❌ 忽略嚴格性相關規則。
Field 定義
- 從設定辨識樣式開始 (替代標籤) 。
- 指定要保留的精確格式。
- 提供位置提示 (典型位置) 。
- 定義資料歸屬 (供應商 vs. 客戶) 。
- 說明多行值的處理方式。
- 參考相關欄位以避免混淆。
測試策略
- 從簡單文件開始:先測試基本擷取功能。
- 擴展到各種變化:嘗試不同版面與格式。
- 測試邊界案例:欄位缺失、非典型位置、多重符合。
- 紀錄失敗案例:保留擷取失敗的範例。
- 有系統地反覆調整:一次只變更一個因素。
效能最佳化
- 讓提示詞保持精簡。
- 使用 Annotated Text 格式。
- 將每個活動中的欄位數量降到最少。
- 考慮切分複雜文件。
- 提供完整的欄位規則。
- 加入格式範例。
- 新增嚴格的規則設定。
- 使用多樣的文件樣本進行測試。
- 最佳化提示詞長度。
- 使用效率較高的文件格式。
- 在適當情況下快取結果。
- 透過 LLM 供應商的儀表板監控 token 使用量。
疑難排解
擷取問題
- 檢查欄位名稱拼寫是否完全相符。
- 驗證資料是否符合所選的文件格式。
- 在辨識樣式中加入更多標籤變化。
- 暫時降低嚴格度,以查看 LLM 是否能找到該欄位。
- 檢查文件品質是否影響 OCR 或文字擷取。
- 強化針對供應商的規格說明。
- 對客戶/買方資料加入明確的排除規則。
- 提供位置提示 (例如:「文件頂端」、「開立人區段」) 。
- 加入正確與錯誤擷取的對照範例。
- 明確指定跳脫序列格式 (
\n) 。 - 提供正確多行輸出範例。
- 驗證文件格式是否保留換行。
- 加入指示:「使用
\n保留原始換行符號」。
- 強調「逐字」與「與印刷內容完全相同」。
- 新增嚴格規則:「不得進行標準化或推論」。
- 提供具體範例,說明需保留原始格式。
- 加入反面範例:「不要變成 ‘12-34-56’,請保持為 ‘12 34 56’」。
效能問題
- 若使用 PDF,請改用 Annotated Text 格式。
- 在不犧牲關鍵指示的前提下簡化提示詞。
- 若影像尺寸非常大,降低文件解析度。
- 檢查 LLM 服務提供者的狀態與頻率限制。
- 對於結構較簡單的文件,考慮使用速度較快的模型。
- 提高嚴格度設定。
- 讓指示更具體且不含歧義。
- 增加更多格式範例。
- 降低可能造成多種解讀的提示詞複雜度。
- 使用較高的 temperature 設定進行測試 (若連線設定支援) 。
- 最佳化提示詞長度。
- 使用 Annotated Text 取代 PDF。
- 在離峰時段以批次方式處理文件。
- 對於結構較簡單的文件,考慮使用較小/較便宜的模型。
- 在 LLM 服務提供者的主控台中監控並設定預算警示。
進階技巧
條件式擷取
多語言支援
驗證規則
欄位關係
限制與考量
目前功能
- ✅ 標頭層級欄位擷取
- ✅ 單行與多行值
- ✅ 每份文件可擷取多個欄位
- ✅ 條件式擷取邏輯
- ✅ 多語系文件
- ✅ 多變的文件版面配置
- ⚠️ 表格擷取 (依實作而異)
- ⚠️ 巢狀複雜結構
- ⚠️ 超大型文件 (token 限制)
- ⚠️ 即時處理 (API 延遲)
- ⚠️ 結果完全可重現的保證
何時應使用提示式擷取
- 版面配置多變的文件
- 半結構化文件
- 快速原型設計與測試
- 小到中等規模的文件量
- 無可用訓練資料時
- 多語言文件處理
- 大規模正式環境 (傳統機器學習可能較快)
- 高度結構化表單 (以範本為基礎的擷取)
- 對成本敏感的應用程式 (傳統方法可能較便宜)
- 對延遲極度敏感的應用程式 (LLM API 會有網路延遲)
- 需要離線處理的情境 (傳統方法不需網際網路連線)
與文件 Skill 整合
使用擷取的資料
- 驗證活動:將商業規則套用至擷取的值。
- 指令碼活動:處理或轉換擷取的資料。
- 匯出活動:將資料傳送到外部系統。
- 檢閱介面:手動驗證擷取的欄位。
與其他活動搭配使用
欄位對應
"FieldName": "Vendor.Name"→ 對應到輸出欄位Vendor.Name。- 在輸出結構中會保留欄位階層。
- 行號有助於驗證與除錯。
摘要
- ✅ 建立一個提示式擷取活動。
- ✅ 設定 LLM 連線。
- ✅ 撰寫包含角色、格式與規則的完整擷取提示。
- ✅ 選擇最佳的文件格式 (Annotated Text) 。
- ✅ 套用嚴謹規則以確保資料品質。
- ✅ 測試擷取並檢閱結果。
- ✅ 學習提示工程的最佳實務。
- 提示式擷取使用自然語言指令。
- Annotated Text 格式可提供最佳結果。
- 清楚、具體的提示能帶來一致的擷取結果。
- 嚴謹規則可避免幻覺並維持資料品質。
- 透過反覆測試與調整可提升準確度。
後續步驟
- 使用多樣化的文件進行測試:在不同版面與各種變體上進行驗證。
- 優化你的提示詞:根據結果持續改進。
- 監控成本:在 LLM 供應商的主控台中追蹤 token 使用量。
- 最佳化效能:為速度與準確度微調提示詞。
- 探索表格擷取:嘗試擷取明細項目 (若有支援) 。
- 與工作流程整合:與其他作業結合以完成端到端處理。
其他資源
- ABBYY Vantage Advanced Designer 說明文件: https://docs.abbyy.com
- LLM 連線設定指南: 如何設定 LLM 連線。
- 提示工程最佳實務: 請參閱您的 LLM 供應商的說明文件。
- 支援: 如需技術協助,請聯絡 ABBYY 支援團隊。