- Klicken Sie im Dokumentdefinitions-Editor mit der rechten Maustaste auf den Namen des Dokumentabschnitts und wählen Sie Feld erstellen.
- Erstellen Sie ein Textfeld.
- Wählen Sie auf der Registerkarte Allgemein die Option Kann Region haben aus.
- Geben Sie im Feld Name einen Namen für das Feld an (zum Beispiel PreambleSegment). Wichtig! Feldnamen dürfen weder Leerzeichen noch nicht englische Zeichen enthalten und nicht mit einer Zahl beginnen.
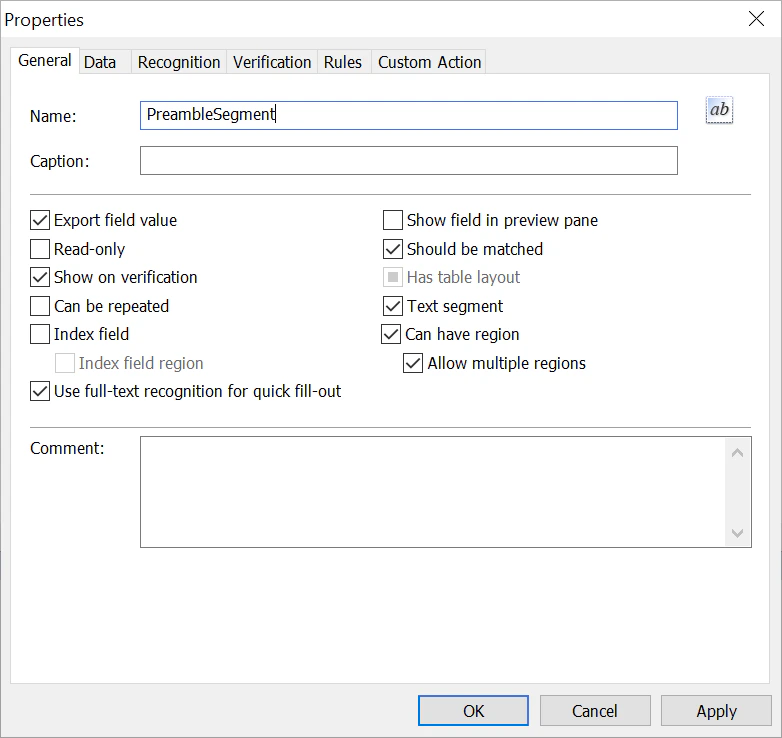
Wenn eine Segmentierung verwendet wird, sollte für jedes Segment ein separates Textfeld erstellt werden.
- Erstellen Sie ein nicht wiederholbares Feld in einer wiederholbaren Gruppe.
- Wählen Sie in den Feldeigenschaften die Option Textsegment aus.
- Wählen Sie die Option Mehrere Regionen zulassen aus, wenn einige Segmente auf unterschiedlichen Seiten beginnen und enden.
- Klicken Sie im Dokumentdefinitions-Editor mit der rechten Maustaste auf den Namen des Dokumentabschnitts.
- Wählen Sie Eigenschaften…
- Klicken Sie im daraufhin geöffneten Dialogfeld auf die Registerkarte NLP und dann auf Erstellen…
- Geben Sie im Feld Name einen Namen für Ihr Segmentierungsmodell an (zum Beispiel SegmentationModel).
- Wählen Sie im Feld Modelltyp die Option Segmentierung aus.
-
Wählen Sie in der Liste Sprache die erforderliche Sprache aus.
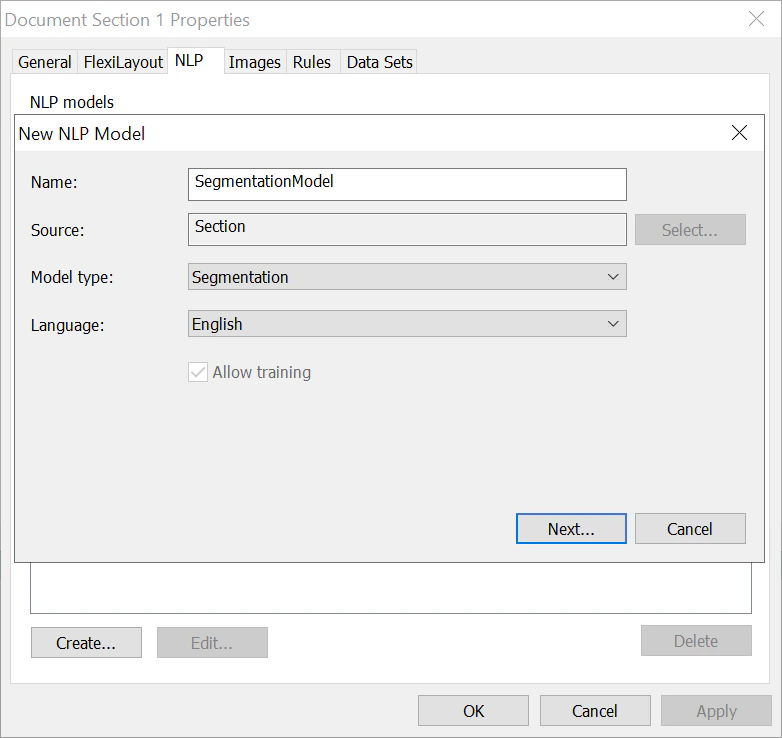
- Klicken Sie auf Weiter…
- Geben Sie im daraufhin geöffneten Dialogfeld alle Felder an, in die die Segmente extrahiert werden sollen.
- Klicken Sie auf OK.
Mit der Option Training zulassen können Sie Ihr NLP-Modell während der Dokumentverarbeitung trainieren. Ihr NLP-Modell wird trainiert, wenn Sie die Feldextraktion mit einem Trainings-Batch für die Feldextraktion trainieren. Trainingsergebnisse können entweder deaktiviert oder gelöscht werden. Um Trainingsergebnisse zu deaktivieren, klicken Sie mit der rechten Maustaste auf den Trainings-Batch und wählen Sie im Kontextmenü den Eintrag Disabled aus. Um Trainingsergebnisse zu löschen, klicken Sie mit der rechten Maustaste auf den Trainings-Batch und wählen Sie im Kontextmenü den Eintrag Delete aus.
- Öffnen Sie im Dokumentdefinitions-Editor die Eigenschaften des Dokumentabschnitts und klicken Sie auf die Registerkarte NLP.
- Klicken Sie auf Erstellen…
- Geben Sie im Feld Name einen Namen für Ihr NLP-Modell an (zum Beispiel EntitiesExtraction).
- Wählen Sie für die Datenquelle entweder einen Abschnitt (wenn keine Segmentierung verwendet wird) oder ein Segment (wenn Sie die Segmentierung verwenden).
- Wählen Sie im Feld Modelltyp die Option Extraktion aus.
- Wählen Sie in der Liste Sprache die erforderliche Sprache aus.
- Klicken Sie auf Weiter…
- Wählen Sie die Ergebnisfelder aus, die aus dem ausgewählten Dokumentabschnitt oder Segment extrahiert werden.
- Klicken Sie auf Dokumentdefinition > Speichern, um Ihre Dokumentdefinition zu speichern.
- Klicken Sie auf Dokumentdefinition > Schließen, um den Dokumentdefinitions-Editor zu schließen.
- Klicken Sie auf Dokumentdefinition > Publish, um Ihre Dokumentdefinition zu veröffentlichen.
Mit der Option Training zulassen können Sie Ihr NLP-Modell während der Dokumentverarbeitung trainieren. Ihr NLP-Modell wird trainiert, wenn Sie die Feldextraktion mit einem Trainings-Batch für die Feldextraktion trainieren. Trainingsergebnisse können entweder deaktiviert oder gelöscht werden. Um Trainingsergebnisse zu deaktivieren, klicken Sie mit der rechten Maustaste auf den Batch und wählen Sie im Kontextmenü den Eintrag Disabled aus. Um Trainingsergebnisse zu löschen, klicken Sie mit der rechten Maustaste auf den Batch und wählen Sie im Kontextmenü den Eintrag Delete aus.