- Dans le Document Definition Editor, cliquez avec le bouton droit sur le nom de la Document Section et sélectionnez Create Field.
- Créez un champ Text.
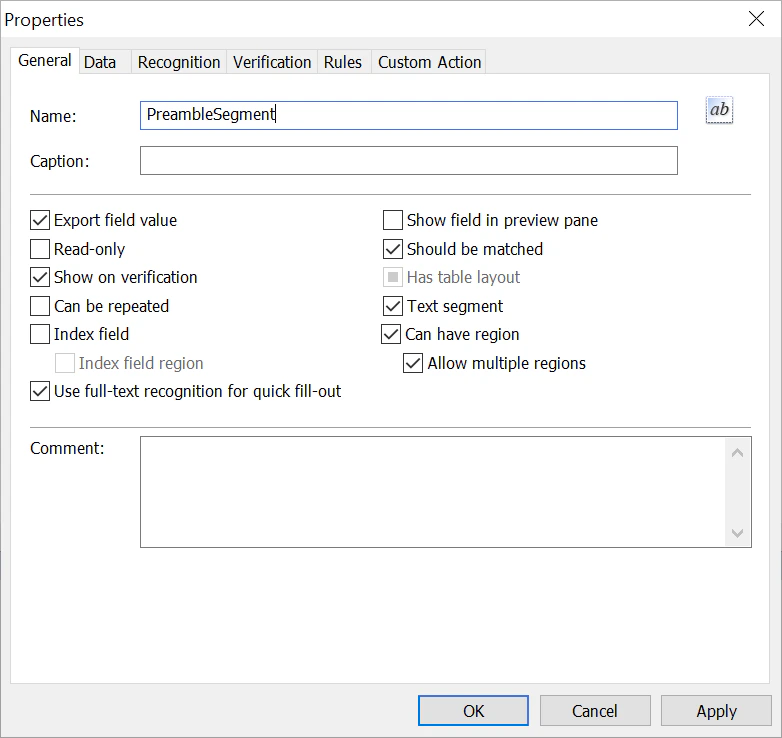
- Dans l’onglet Général, sélectionnez l’option Can have region.
- Dans le champ Name, indiquez un nom pour le champ (par exemple, PreambleSegment). Important ! Les noms de champ ne doivent pas contenir d’espaces, ni de caractères non anglais, ni commencer par un chiffre.
Si la segmentation est utilisée, un champ Text distinct doit être créé pour chaque segment.
- Créez un champ non répétable dans un groupe répétitif.
- Sélectionnez l’option Text segment dans les propriétés du champ.
- Sélectionnez l’option Allow multiple regions si certains segments commencent sur une page et se terminent sur une autre.
- Dans le Document Definition Editor, cliquez avec le bouton droit sur le nom de la Document Section.
- Sélectionnez Properties…
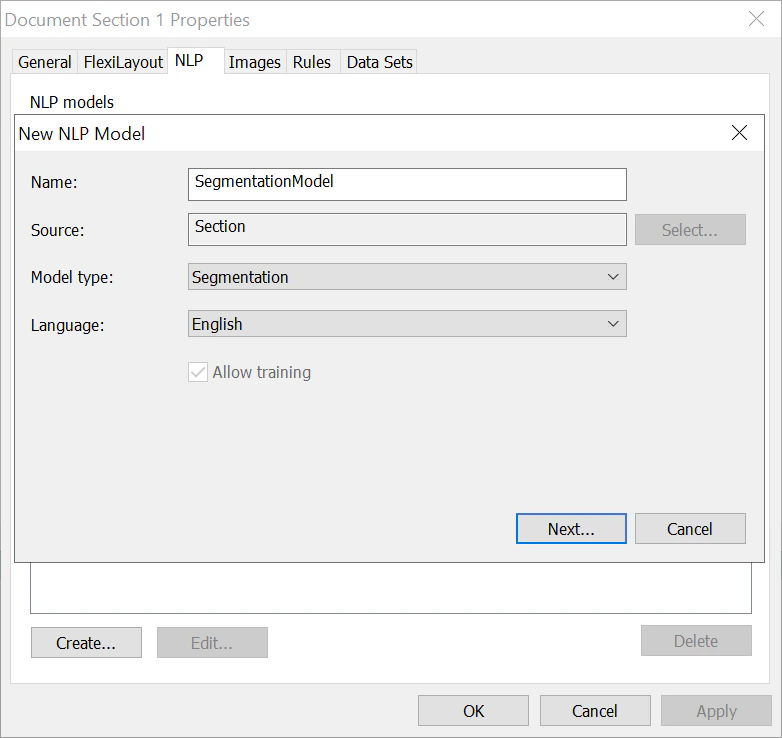
- Dans la boîte de dialogue qui s’ouvre, cliquez sur l’onglet NLP, puis sur Create…
- Dans le champ Name, indiquez un nom pour votre modèle de segmentation (par exemple, SegmentationModel).
- Dans le champ Model type, choisissez Segmentation.
-
Dans la liste Language, sélectionnez la langue requise.
- Cliquez sur Next…
- Dans la boîte de dialogue qui s’ouvre, indiquez tous les champs dans lesquels les segments seront extraits.
- Cliquez sur OK.
L’option Allow training vous permet d’entraîner votre modèle NLP pendant le traitement des documents. Votre modèle NLP sera entraîné lorsque vous entraînerez l’extraction de champs à l’aide d’un lot d’entraînement d’extraction de champs. Les résultats de l’entraînement peuvent être désactivés ou supprimés. Pour désactiver les résultats de l’entraînement, cliquez avec le bouton droit sur le lot d’entraînement et sélectionnez l’élément Disabled dans le menu contextuel. Pour supprimer les résultats de l’entraînement, cliquez avec le bouton droit sur le lot d’entraînement et sélectionnez l’élément Delete dans le menu contextuel.
- Dans le Document Definition Editor, ouvrez les propriétés de la section de document et cliquez sur l’onglet NLP.
- Cliquez sur Create…
- Indiquez un Name pour votre modèle NLP (par exemple, EntitiesExtraction).
- Pour la source de données, sélectionnez soit une section (si aucune segmentation n’est utilisée), soit un segment (si vous avez choisi d’utiliser la segmentation).
- Dans le champ Model type, choisissez Extraction.
- Dans la liste Language, sélectionnez la langue requise.
- Cliquez sur Next…
- Choisissez les champs de résultat qui seront extraits de la section ou du segment de document sélectionné.
- Cliquez sur Document Definition > Save pour enregistrer votre Document Definition.
- Cliquez sur Document Definition > Close pour fermer le Document Definition Editor.
- Cliquez sur Document Definition > Publish pour publier votre Document Definition.
L’option Allow training vous permet d’entraîner votre modèle NLP pendant le traitement des documents. Votre modèle NLP sera entraîné lorsque vous entraînerez l’extraction de champs à l’aide d’un lot d’entraînement d’extraction de champs. Les résultats de l’entraînement peuvent être désactivés ou supprimés. Pour désactiver les résultats de l’entraînement, cliquez avec le bouton droit sur le lot et sélectionnez l’élément Disabled dans le menu contextuel. Pour supprimer les résultats de l’entraînement, cliquez avec le bouton droit sur le lot et sélectionnez l’élément Delete dans le menu contextuel.