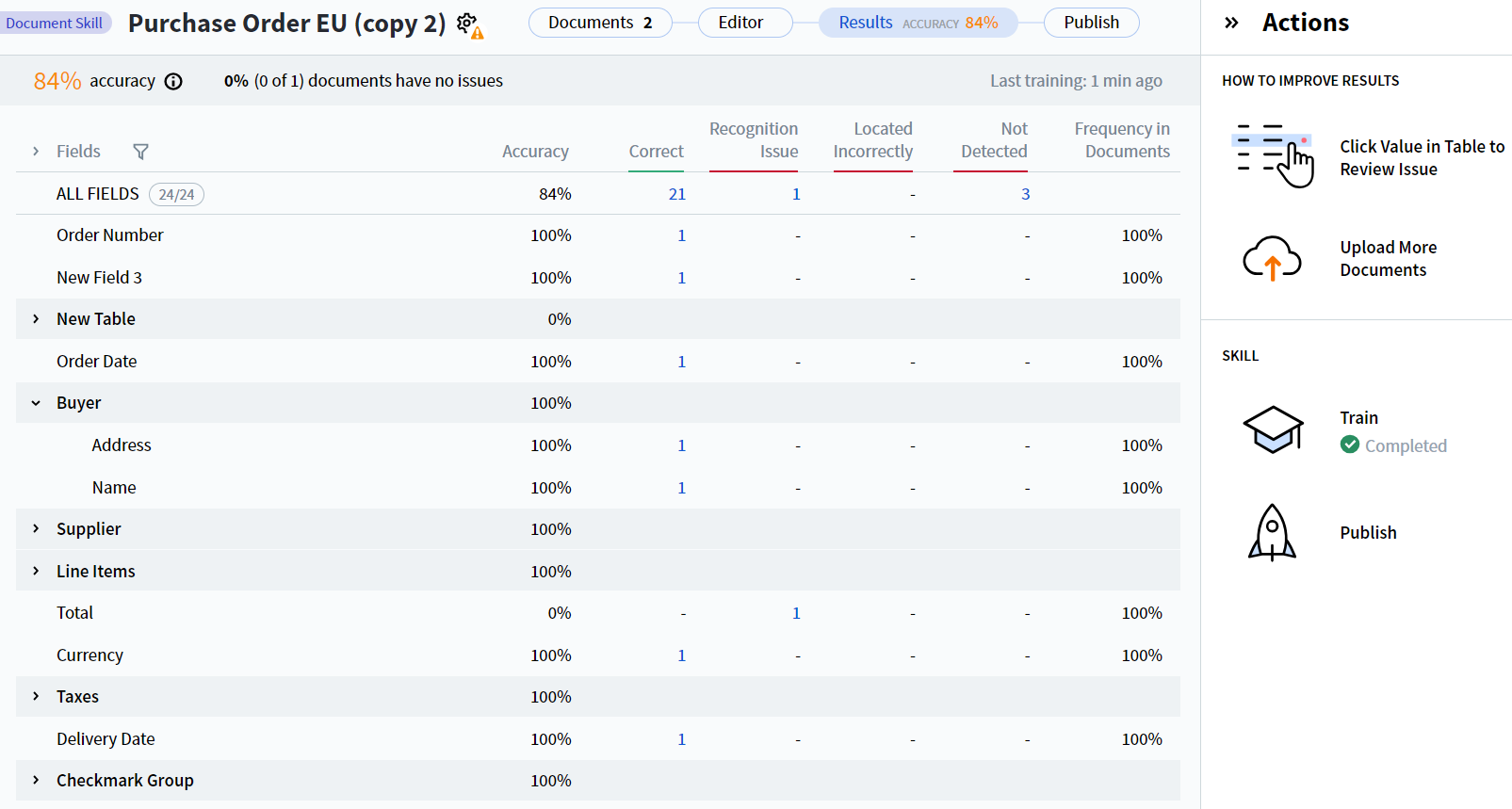
L’onglet Results du Document Skill Designer contient des statistiques d’extraction des champs pour les compétences de document. Utilisez ces statistiques pour déterminer comment améliorer la qualité de l’extraction.
Tous les champs extraits par la compétence apparaissent dans la colonne Fields. Les champs appartenant à un groupe sont regroupés dans une liste déroulante réduite portant le nom du groupe.
Les statistiques d’extraction des champs suivantes sont disponibles :
-
Accuracy — Pourcentage de champs dont les valeurs ont été correctement extraites, à la fois pour chaque champ et pour l’ensemble des champs (ligne ALL FIELDS).
La précision par champ est calculée comme suit :
La ligne ALL FIELDS utilise la même formule, chaque terme étant agrégé sur l’ensemble des champs.
-
Correct — Nombre d’instances de champ dont la valeur extraite correspond à la valeur de référence.
-
problème de reconnaissance — Nombre d’instances de champ détectées dans le document, mais non correctement reconnues.
-
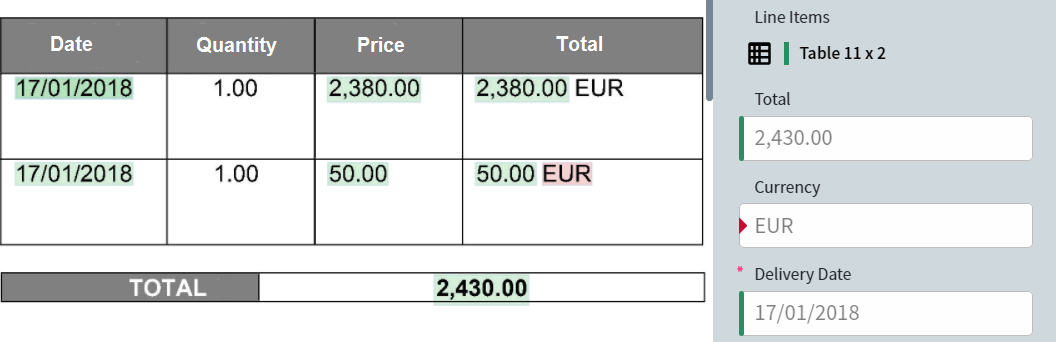
mauvaise localisation — Nombre d’instances de champ dont les valeurs diffèrent des valeurs prédites, car leurs régions ont été détectées à des emplacements différents de ceux définis dans l’annotation.
-
non détecté — Nombre d’instances de champ non détectées.
-
Frequency in Documents — Pourcentage de documents contenant le champ donné.
Par défaut, les statistiques s’affichent pour tous les champs. Pour filtrer, cliquez sur l’icône de filtre en haut de la colonne Fields, puis sélectionnez les champs à afficher.
Pour une analyse plus poussée de la qualité — Precision, Recall et F-measure pour les valeurs de champ et la détection des régions — modifiez votre compétence dans Advanced Designer. Consultez Advanced Accuracy Reports pour plus de détails. Pour que ces statistiques reflètent la qualité en production, la distribution des documents de votre jeu de test doit correspondre à celle observée en production. Par exemple, si 30 % de vos factures en production proviennent d’un fournisseur particulier, environ 30 % du jeu de test doivent également en provenir. L’utilisation d’un jeu aveugle (documents non utilisés pour l’entraînement ni lors de tests précédents) renforce encore la validité des résultats.
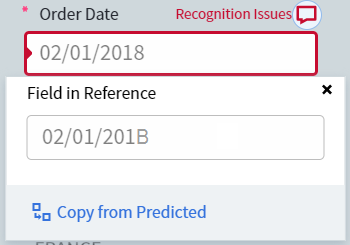
En cliquant sur la valeur dans la colonne Problème de reconnaissance pour le champ Order Date, un onglet s’ouvre affichant uniquement les documents dans lesquels Order Date présente un problème de reconnaissance.
- Reference — Affiche l’étiquetage de référence créé lors de la configuration de la compétence (avant l’entraînement), ainsi que les valeurs de champ extraites à partir de celui-ci. Les valeurs de champ et les régions peuvent être modifiées dans ce mode.
- Predicted — Affiche les valeurs de champ et les régions obtenues lors du traitement des documents. Non modifiable.
- Difference — Affiche les différences entre l’étiquetage de référence et l’étiquetage prédit. Les valeurs et les régions identiques apparaissent en vert ; celles qui diffèrent apparaissent en rouge. Non modifiable.
Passez d’un mode à l’autre en cliquant sur l’onglet correspondant dans la barre d’outils.
Corriger l’étiquetage de référence
Un problème de reconnaissance signifie qu’un ou plusieurs caractères n’ont pas été reconnus correctement. Pour le corriger, ajustez les propriétés du champ afin que ces caractères soient interprétés correctement. Par exemple, si un champ contient uniquement des nombres, définissez son type de données sur Number. Cela évitera, par exemple, que le chiffre “1” soit reconnu comme “l” (L minuscule) ou “I” (i majuscule).