Method
Characters
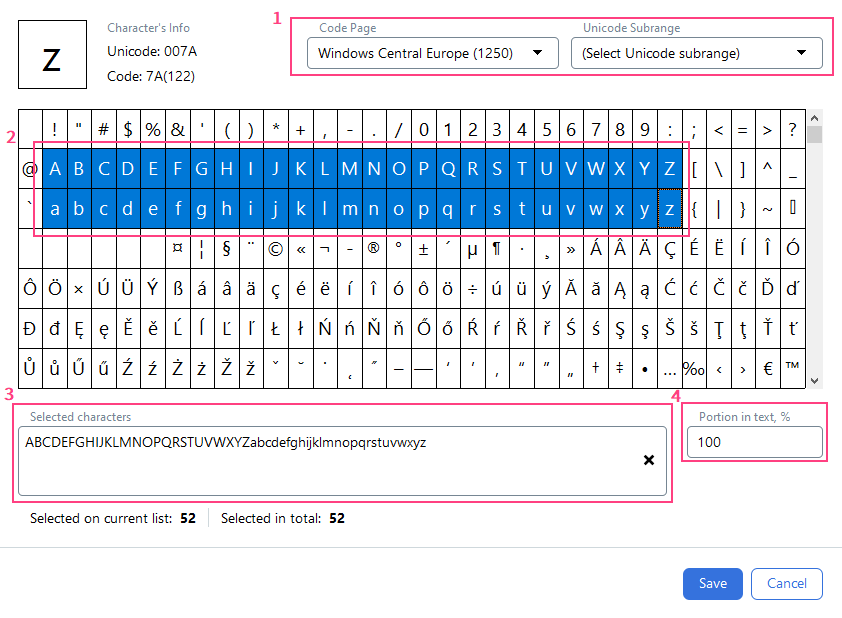
문자 집합 설정
- 드롭다운 목록에서 Code Page field 또는 Unicode Subrange field에서 적절한 문자 인코딩 표준을 선택합니다.
- 아래 표에서 필요한 문자를 선택합니다.
- 선택한 문자는 Selected characters field에 표시됩니다. 키보드를 사용해 문자 집합을 직접 지정할 수도 있습니다.
Portion in text, %field에서 검색할 텍스트에 포함된 문자 비율(0~100)을 지정합니다.
Regular Expression
정규식 알파벳
| 목록의 이름 | field에서의 기호 | 예시 | ||
|---|---|---|---|---|
| 임의의 문자 | * | “k”*“t” – ‘kit’, ‘kat’ 등을 허용합니다 | ||
| 문자 | C | C”at” – cat, bat, Rat, mat 등을 허용합니다 | ||
| 대문자 | A | A”at” – Cat, Bat, Rat, Mat 등을 허용합니다 | ||
| 소문자 | a | a”at” – car, bat, rat, mat 등을 허용합니다 | ||
| 문자 또는 숫자 | X | X – 임의의 한 개 문자 또는 숫자를 허용합니다 | ||
| 숫자 | N | N”th” – 5th, 4th, 6th 등을 허용합니다 | ||
| 문자열 | "" | "cat” | ||
| 또는 | ”dr”(“i" | "u”)“nk” – “drink” 또는 “drunk”를 허용합니다 | ||
| 집합에 포함된 문자 | [] | [hm]“at” – ‘hat’ 또는 ‘mat’를 허용합니다 | ||
| 집합에 포함되지 않은 문자 | [^] | [^b]“at” – ‘cat’, ‘mat’, ‘rat’는 허용하지만 ‘bat’는 허용하지 않습니다 | ||
| 반복 횟수: 임의 개수 (왼쪽 표현식 또는 하위 표현식에 적용) | {-} | [AB74]{-} – A, B, 7, 4의 임의 길이 조합을 허용합니다 | ||
| 반복 횟수: n회 | {n} | N{2}"th" – 25th, 84th, 11th 등을 허용합니다 | ||
| 반복 횟수: n~m회 | {n-m} | N{1-3}"th" – 5th, 84th, 111th 등을 허용합니다 | ||
| 반복 횟수: 0~n회 | {-n} | N{-2}"th" – th, 84th, 4th 등을 허용합니다 | ||
| 반복 횟수: n회 이상 | {n-} | N{2-}"th" – 25th, 834th, 311th, 34576th 등을 허용합니다 | ||
| 하위 표현식 | () |
정규식 예시
- 우편번호:
[0-9]{6}예시 값: “142172” - 우편번호 (USA):
[0-9]{5}("-"[0-9]{4}){-1}예시 값: “55416”, “33701-4313” - 소득: N
{4-8}[,]N{2}예시 값: “15000,00”, “4499,00” - 숫자로 표현된 월:
((|"0")[1-9])|("10")|("11")|("12")예시 값: “4”, “05”, “12” - 분수:
("-"|)([0-9]{1-})(|(("."| ",")([0-9]{1-})))예시 값: “1234,567”, “0.99”, “100,0”, “-345.6788903” - 이메일:
[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-3}"@"[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-4}"."([A-Za-z]{2-4}|"asia"|"museum"|"travel"|"example"|"localhost")예시 값: “support@abbyy.com”, “my-name@company.org.ru”, “info@gallery.museum”
확장 정규식
[% 및 %]) 구문으로 둘러싸인 추가 기능을 가진 정규식입니다. 확장 정규식에는 다음과 같은 추가 기능이 있습니다:
- 대괄호 안의 하나 이상의 문자에 대해, 자주 발생하는 OCR 오류가 추가로 허용됩니다. 예를 들어,
[%S%]는 S, $, 5를 허용할 수 있습니다. - 일반적인 문자 집합 및 OCR 오류를 위한
[%...%]내부의 특수 단어: a. LETTERS - 대문자 라틴 문자 및 일반적으로 대문자 라틴 문자로 인식되는 문자
b. DIGITS - 숫자 및 일반적으로 숫자로 인식되는 문자
c. LETERSANDDIGITS - 대문자 라틴 문자, 숫자 및 일반적으로 대문자 라틴 문자와 숫자로 인식되는 문자
[%DIGITS%]{9}는 9개의 연속된 숫자 또는 숫자에 대한 일반적인 OCR 오류를 허용하도록 지정합니다(예: “OI234Sb7B9”).
추가 속성
- 허용 오류는 최대 허용 인식 오류 비율을 지정합니다. 즉, 전체 문자 수 중 정의된 문자 집합에 속하지 않는 문자가 차지할 수 있는 최대 비율을 나타냅니다. 객체에 대한 가설은 해당 객체의 인식 오류 비율이 지정된 값보다 높지 않은 경우에만 수립될 수 있습니다.
- 단어 수는 검색 대상 텍스트에 포함될 수 있는 최소 및 최대 단어 수를 지정합니다.
- 문자 수는 검색 대상 텍스트에 포함될 수 있는 최소 및 최대 문자 수를 지정합니다.
- 단어 일부 검색은 가설에서 단어 조각을 허용할지 여부를 지정합니다. 단어 조각이 포함된 가설을 제외하고 전체 단어만 검색해야 하는 경우 이 옵션을 비활성화하십시오.
고급 속성
- Allow embedded hypotheses는 검색 영역 내의 문자를 사용해, 교차 가설과 중첩(포함) 가설을 포함한 모든 가능한 가설을 생성하도록 허용합니다.
- Max. space length는 인식된 객체 내부에 허용되는 공백의 최대 길이를 지정합니다.
- Text orientation은 찾으려는 텍스트의 방향을 지정합니다. 기본적으로 이 액티비티는 가로 방향의 텍스트만 찾으며, 회전된 텍스트에 대해서는 가설을 세우지 않습니다. 특정 방향으로 회전된 텍스트만 찾고 그 외 방향의 텍스트는 무시하려면 Clockwise 또는 Counter-clockwise 옵션만 선택해야 합니다. 텍스트 방향과 관계없이 모두 찾으려면 사용 가능한 모든 옵션을 활성화해야 합니다.
- Detect words by는 줄을 단어로 분할하는 방식을 지정합니다. 자동으로 (Pre-Recognition) 줄을 단어로 나누거나, 인접한 문자 사이의 공백이 Min. interword space에 입력한 값보다 크거나 같은 경우마다 (Interword Space) 줄을 단어로 나눕니다.