Search element structure
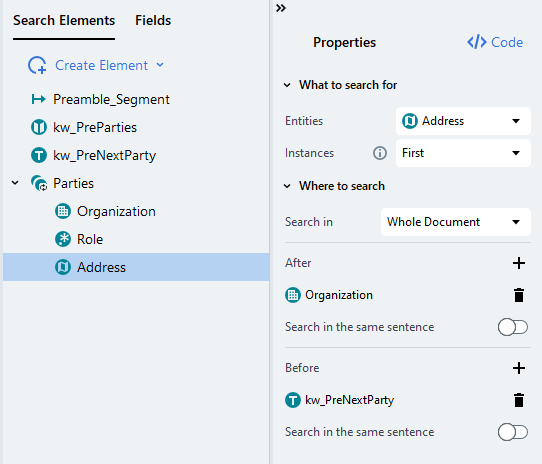
Parties.Address search element will look like this:
Read auto-generated code for NLP search-element properties — full-path references, name simplification, and rule-by-rule explanation in Advanced Designer.
Parties.Address search element will look like this: