方法
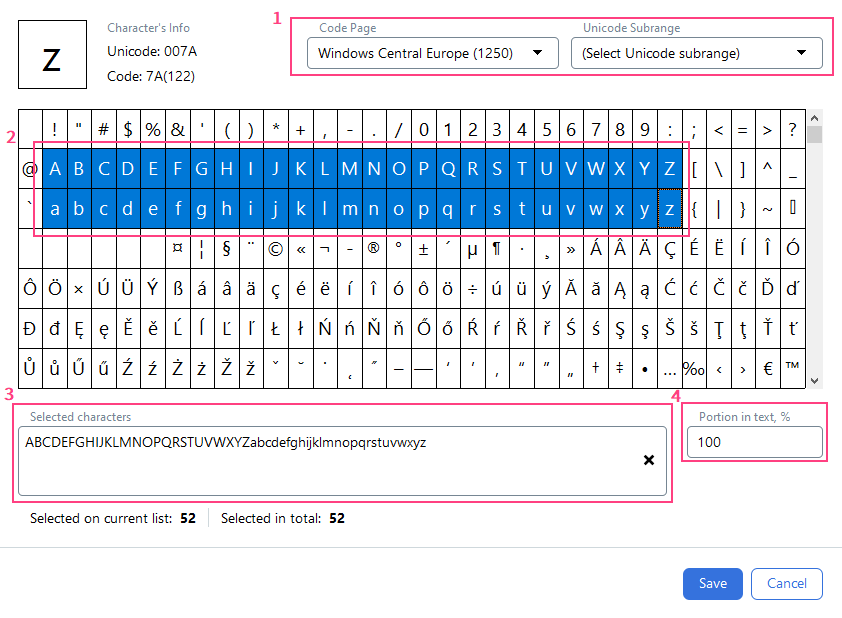
Characters
設定字元集
- 從 Code Page 欄位或 Unicode Subrange 欄位的下拉清單中選擇適當的字元編碼標準。
- 在下方表格中選取適當的字元。
- 您選取的字元會顯示在 Selected characters 欄位中。您也可以使用鍵盤輸入來指定字元集。
- 在
Portion in text, %欄位中,指定在要搜尋文字中出現的字元所佔比例 (從 0 到 100) 。
Regular Expression
正則表達式字元集
| 列表中的名稱 | 欄位中的符號 | 範例 | ||
|---|---|---|---|---|
| 任意字元 | * | “k”*“t” – 允許 ‘kit’、‘kat’ 等。 | ||
| 字母 | C | C”at” – 允許 cat、bat、Rat、mat 等。 | ||
| 大寫字母 | A | A”at” – 允許 Cat、Bat、Rat、Mat 等。 | ||
| 小寫字母 | a | a”at” – 允許 car、bat、rat、mat 等。 | ||
| 字母或數字 | X | X – 允許任一個字母或數字。 | ||
| 數字 | N | N”th” – 允許 5th、4th、6th 等。 | ||
| string | "" | "cat” | ||
| 或 | ”dr”(“i" | "u”)“nk” – 允許 “drink” 或 “drunk”。 | ||
| 來自集合的字元 | [] | [hm]“at” – 允許 ‘hat’ 或 ‘mat’。 | ||
| 不在集合中的字元 | [^] | [^b]“at” – 允許 ‘cat’、‘mat’、‘rat’,但不允許 ‘bat’。 | ||
| 任意次數重複 (套用於左側的運算式或子運算式) | {-} | [AB74]{-} – 允許任意長度、由 A、B、7、4 組成的任意組合。 | ||
| 重複次數為 n | {n} | N{2}"th" – 允許 25th、84th、11th 等。 | ||
| 重複 n 到 m 次 | {n-m} | N{1-3}"th" – 允許 5th、84th、111th 等。 | ||
| 重複 0 到 n 次 | {-n} | N{-2}"th" – 允許 th、84th、4th 等。 | ||
| 重複 n 次以上 | {n-} | N{2-}"th" – 允許 25th、834th、311th、34576th 等。 | ||
| 子運算式 | () |
正則表達式示例
- 郵政編碼:
[0-9]{6}範例值:“142172” - 郵遞區號 (USA):
[0-9]{5}("-"[0-9]{4}){-1}範例值:“55416”、“33701-4313” - 收入:N
{4-8}[,]N{2}範例值:“15000,00”、“4499,00” - 數字格式的月份:
((|"0")[1-9])|("10")|("11")|("12")範例值:“4”、“05”、“12” - 小數:
("-"|)([0-9]{1-})(|(("."| ",")([0-9]{1-})))範例值:“1234,567”、“0.99”、“100,0”、“-345.6788903” - 電子郵件地址:
[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-3}"@"[A-Za-z0-9_]{1-}(("."| "-")[A-Za-z0-9_]{1-}){-4}"."([A-Za-z]{2-4}|"asia"|"museum"|"travel"|"example"|"localhost")範例值:“support@abbyy.com”、“my-name@company.org.ru”、“info@gallery.museum”
擴充正規表示式
[% 和 %]) 。擴充正規表示式具有以下額外功能:
- 括號內的一個或多個字元會自動擴充為包含常見 OCR 誤讀錯誤的變體。例如,
[%S%]可以允許 S、$ 和 5。 - 在
[%...%]中可使用特殊關鍵字來表示常見字元集與 OCR 誤讀錯誤:a. LETTERS - 大寫拉丁字母以及通常會被辨識為大寫拉丁字母的字元;b. DIGITS - 數字以及通常會被辨識為數字的字元;c. LETERSANDDIGITS - 大寫拉丁字母、數字,以及通常會被辨識為大寫拉丁字母與數字的字元。
[%DIGITS%]{9} 指定九個連續的數字或數字的常見 OCR 誤讀錯誤,例如「OI234Sb7B9」。
其他屬性
- 允許錯誤 指定可接受的最大辨識錯誤百分比。換句話說,它表示在所有字元中,允許不屬於已定義字元集的字元所佔的最大百分比。只有當某個物件的辨識錯誤百分比不高於此指定值時,才會為該物件建立假設。
- 字數 指定所搜尋文字的最小與最大單字數。
- 字元數 指定所搜尋文字的最小與最大字元數。
- 搜尋字的一部分 指定在假設中是否允許使用單字片段。如果您需要排除包含單字片段的假設,並且只搜尋完整單字,請停用此選項。
進階屬性
- Allow embedded hypotheses 允許根據搜尋區域中的字元產生所有可能的假設——包括相交與嵌入的假設。
- Max. space length 可用來指定在偵測到的物件內可包含的空白之最大長度。
- Text orientation 可用來指定您要尋找的文字方向。預設情況下,此活動只會尋找水平方向的文字,且不會對旋轉文字建立假設。如果您需要只找到以特定方式旋轉的文字,並忽略以其他任何方向書寫的文字,則只需選取 順時針 (Clockwise) 或 逆時針 (Counter-clockwise) 選項。若要不論方向皆能找到文字,請啟用所有可用選項。
- Detect words by 指定應如何將一行分割為單字:自動 (Pre-Recognition),或是在鄰近字元之間的空白大於或等於 Min. interword space 中輸入的值時,透過將一行分割成多個單字 (Interword Space) 來進行。