Dokumentkonvertierung
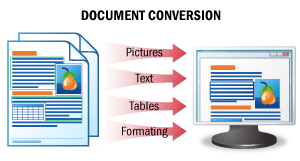
Das Ergebnis dieses Szenarios ist eine bearbeitbare Version eines Dokuments.
In diesem Szenario werden Dokumentbilder erkannt, wobei die ursprüngliche Formatierung vollständig erhalten bleibt, und die Daten in einem bearbeitbaren Dateiformat gespeichert. So erhalten Sie bearbeitbare Versionen Ihrer Dokumente, die sich einfach auf Fehler prüfen und bearbeiten lassen.
See Dokumentkonvertierung für weitere Informationen.
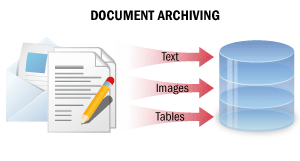
In diesem Verarbeitungsszenario werden Papierdokumente in nicht bearbeitbare digitale Kopien umgewandelt, die sämtliche Dokumentinformationen in einem durchsuchbaren Format enthalten. Dadurch lassen sich digitale Dokumentkopien in einem elektronischen Archiv per Volltextsuche leicht finden, Textabschnitte kopieren sowie Dokumente per E-Mail versenden oder ausdrucken.
See Dokumentarchivierung für weitere Informationen.
Datenerfassung
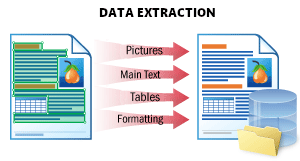
Dieses Szenario dient dazu, alle möglichen Daten aus einem Dokument zu extrahieren und strukturiert zu speichern.
Das Ergebnis ist eine JSON-Datei, die die Struktur des Dokuments abbildet. Sie enthält alle Dokumentobjekte: gedruckten und handschriftlichen Text, Tabellen, Barcodes, Häkchen und Bilder mit ihrer Position und ihren Attributen. Dieses Format eignet sich optimal für die Weiterverarbeitung, die Speicherung der Daten in einer Datenbank oder die Integration in eine andere Anwendung.
Weitere Informationen finden Sie unter Datenextraktion.
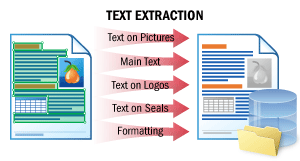
Dieses Szenario ermöglicht die Extraktion des Fließtexts eines Dokuments sowie von Texten auf Logos, Siegeln und anderen Elementen außerhalb des Fließtexts.
Die natürliche Reihenfolge des Textes – „wie ein Mensch ihn lesen würde“ – bleibt erhalten. Anschließend können Sie die Dokumente an NLP-Engines in Ihrer Umgebung übergeben, damit sie beispielsweise schnell zusammengefasst, nach sensiblen Informationen durchsucht oder einer Stimmungsanalyse unterzogen werden.
Weitere Informationen finden Sie unter Textextraktion.
Bei der Felderkennung werden kurze Textfragmente erkannt, um Daten aus bestimmten Feldern zu erfassen. Die Erkennungsqualität ist in diesem Szenario von entscheidender Bedeutung.
Dieses Szenario kann auch als Teil komplexerer Szenarien verwendet werden, in denen aussagekräftige Daten aus Dokumenten extrahiert werden sollen (zum Beispiel, um Daten aus Papierdokumenten in Informationssysteme und Datenbanken zu übernehmen oder Dokumente in Dokumentenmanagementsystemen automatisch zu klassifizieren und zu indizieren).
In diesem Szenario erkennt das System entweder mehrere Textzeilen in nur einigen Feldern oder den gesamten Text in einem kleinen Bild. Das System berechnet für jedes erkannte Zeichen einen Zuverlässigkeitswert. Diese Werte können anschließend bei der Überprüfung der Erkennungsergebnisse verwendet werden. Zusätzlich kann das System mehrere Erkennungsvarianten für Wörter und Zeichen im Text speichern, die anschließend in Abstimmungsalgorithmen verwendet werden können, um die Erkennungsqualität zu verbessern.
Weitere Informationen finden Sie unter Felderkennung.
In diesem Szenario wird ABBYY FineReader Engine zum Lesen von Barcodes verwendet. Barcodes müssen beispielsweise für die automatische Dokumententrennung, für die Verarbeitung von Dokumenten durch ein Document Management System oder für die Indizierung und Klassifizierung von Dokumenten gelesen werden.
Dieses Szenario kann auch als Teil anderer Szenarien verwendet werden. Beispielsweise können mit Hochgeschwindigkeits-Produktionsscannern gescannte Dokumente mithilfe von Barcodes getrennt werden, oder für die Langzeitarchivierung vorbereitete Dokumente können anhand ihrer Barcode-Werte in archivierende Document Management Systems übernommen werden.
Beim Extrahieren von Barcodes aus Texten kann das System alle Barcodes oder nur Barcodes eines bestimmten Typs mit einem bestimmten Wert erkennen. Das System kann den Wert eines Barcodes auslesen und seine Prüfsumme berechnen.
Erkannte Barcode-Werte können in Formaten gespeichert werden, die für die Weiterverarbeitung am besten geeignet sind, zum Beispiel in TXT.
Weitere Informationen finden Sie unter Barcode Recognition.
Visitenkarten enthalten geschäftliche Informationen über ein Unternehmen oder eine Person. Visitenkarten können den Namen einer Person, das Unternehmen, Telefonnummern, Fax, E-Mail, Website-Adressen und ähnliche Informationen enthalten. Unter Umständen müssen Sie diese Informationen von Papier-Visitenkarten erfassen und in elektronischer Form speichern. Das kann ein elektronisches Adressbuch eines Mobiltelefons, E-Mail-Clients oder ein anderes Datenspeicher- system sein. Beispielsweise werden Visitenkarten häufig per E-Mail oder über ein Netzwerk im vCard-Format weitergegeben.
Weitere Informationen finden Sie unter Business Cards Recognition.
Die offiziellen Reise- oder Ausweisdokumente vieler Länder enthalten eine maschinenlesbare Zone (MRZ), die eine präzisere Verarbeitung der Dokumentdaten ermöglicht.
Dieses Szenario dient dazu, Daten aus der maschinenlesbaren Zone auf Ausweisdokumenten während des Kunden-Onboardings oder in Verifizierungsprozessen zu extrahieren. Das System erkennt die MRZ im Dokumentbild und extrahiert die darin enthaltenen Daten. Die extrahierten Daten umfassen mehrere Felder mit personenbezogenen Informationen zum Dokument und seinem Inhaber (Dokumenttyp und Ablaufdatum, Vor- und Nachname des Dokumentinhabers usw.). Sie können die Felder durchsuchen, die Daten überprüfen und sie zur weiteren Verarbeitung in einer externen Datei speichern.
Weitere Informationen finden Sie unter Erfassung der maschinenlesbaren Zone.
Weitere

In diesem Szenario wird ABBYY FineReader Engine auf einem „Scan-Computer“ verwendet, der Bilder scannt und als Dateien speichert.
Dieses Szenario kann in einer frühen Phase der Dokumentverarbeitung als Teil anderer Szenarien eingesetzt werden, d. h. zum Erstellen elektronischer Versionen von Dokumenten für die weitere Verarbeitung. Beispiele sind das Scannen von Dokumenten zu Archivierungszwecken, das Erstellen bearbeitbarer Dokumentversionen und das Extrahieren relevanter Daten aus Dokumenten.
Papierdokumente werden gescannt und die Bilder in einem elektronischen Format gespeichert, sodass hochwertige elektronische Versionen Ihrer gedruckten Dokumente entstehen.
Weitere Informationen finden Sie unter Scannen.
Die Aufgabe der Dokumentklassifizierung besteht darin, ein Dokument einer benutzerdefinierten Kategorie zuzuordnen. Möglicherweise arbeiten Sie mit einem Dokumentenbestand, der aus mehreren Dokumenttypen besteht, zum Beispiel Verträgen, Rechnungen und Belegen. Sie müssen den Typ jedes Dokuments identifizieren. So möchten Sie die Dokumente beispielsweise in verschiedene Ordner sortieren oder sie entsprechend ihrem Typ umbenennen. Dies kann automatisch mit einem vortrainierten System erfolgen.
Der wichtigste Aspekt dieses Szenarios ist, dass Sie die Dokumenttypen kennen, die verarbeitet werden sollen. ABBYY FineReader Engine kann Dokumente anhand ihres Erscheinungsbilds oder ihres Inhalts klassifizieren.
Weitere Informationen finden Sie unter Dokumentklassifizierung.

Bei der Arbeit mit Papierdokumenten müssen Sie Fehler oder absichtlich vorgenommene Änderungen finden und korrigieren.
Dieses Szenario wird verwendet, um besonders wichtige Dokumente wie Verträge und Bankunterlagen mit ihren Kopien zu vergleichen. Das Vergleichsergebnis enthält Informationen über Unterschiede bei der Inhaltsart (nur Text), der Art der Änderung (gelöscht, eingefügt oder geändert) sowie deren Positionen im Original und in der Kopie. Sie können die Liste der erkannten Unterschiede oder den Bereich jeder Änderung abrufen und das Vergleichsergebnis zur weiteren Verarbeitung oder Langzeitspeicherung in einer externen Datei speichern.
Weitere Informationen finden Sie unter Dokumentvergleich.