Antes de comenzar
Abra la actividad en el Activity Editor
- Abra la actividad “Sick Note DE” en el Activity Editor.
- Seleccione uno de los documentos del conjunto de documentos.
Habilite las propiedades avanzadas del elemento
Extraiga los datos del paciente
Cree el grupo PatientDataArea
- Haga clic en Create Element y seleccione el elemento grupo en la lista desplegable. Cambie su nombre a “PatientDataArea”.
- En la sección En qué condiciones, cambie el valor de Element is a Optional.
Localice la etiqueta del paciente con un elemento de texto estático
- Haga clic en Create Element y seleccione el elemento Texto estático de la lista desplegable. Cambie su nombre a “kwPatientTitle”.
- Introduzca el texto “Name, Vorname” en el campo Texto para buscar del panel Propiedades.
- Haga clic en Match. Cuando finalice el procesamiento, verá el Árbol de hipótesis debajo del documento.
- Asegúrese de que Advanced Designer haya encontrado correctamente el texto estático: un punto verde junto al nombre del elemento indica que la coincidencia se encontró correctamente.
- Haga clic en el nombre del elemento en el Árbol de hipótesis para ver un marco violeta alrededor de la región correspondiente del documento.
Encuentre el límite inferior con un separador
- Agregue un elemento separador al grupo y asígnele el nombre “SeparatorBottom”. Establezca su longitud mínima en 200.
- Haga clic con el botón derecho en el elemento y seleccione Match Element en el menú contextual. El Árbol de hipótesis contiene muchos puntos verdes; corresponden a distintos separadores que cumplen los criterios de búsqueda. Haga clic en cada punto para ver el objeto correspondiente en la imagen.
- Para acotar los criterios de búsqueda, especifique el área de búsqueda del separador:
- Haga clic en Match para encontrar el elemento “kwPatientTitle”, que se utilizará como elemento de anclaje.
- En la sección Dónde buscar del panel Propiedades, haga clic en Draw on Image.
- Seleccione el elemento “kwPatientTitle” en el documento. Haga clic en el icono de flecha hacia abajo para especificar el área de búsqueda debajo de la palabra clave y, a continuación, en el icono más cercano para buscar el separador más próximo a la palabra clave.
- Haga clic en Match y compruebe que Advanced Designer haya encontrado el separador debajo del elemento “kwPatientTitle”.
Busque el párrafo con el nombre y la dirección
- Cree un elemento de búsqueda de Párrafo y asígnele el nombre “NameAddressParagraph”.
- Cambie Text alignment a Left.
- Los datos del paciente ocupan de dos a cinco líneas, así que especifique Line count de 2 a 5.
- Especifique el área de búsqueda del párrafo mediante el menú Add en la sección Where to search. El elemento debe estar situado debajo del elemento “kwPatientTitle” y encima del elemento “SeparatorBottom”.
- Haga clic en Match.
Crear PatientGroup
Configurar el grupo repetido NameGroup
- Cree un elemento de búsqueda Grupo repetido y asígnele el nombre “NameGroup”. Especifique 2 como número máximo de repeticiones. Haga que el elemento sea opcional.
-
Para restringir el área de búsqueda a las líneas que forman parte del párrafo “NameAddressParagraph”, haga clic en el icono del editor de código situado debajo de la imagen del documento y pegue el siguiente script en la sección Search Conditions del Code Editor:
- Dentro del grupo repetido, cree un elemento Cadena de caracteres diseñado para capturar una línea de caracteres. Asígnele el nombre “NameLine”.
-
El texto que buscamos puede contener letras mayúsculas y minúsculas, así como un conjunto de signos de puntuación. Configure dos conjuntos de caracteres independientes:
- El primer conjunto contiene todas las letras latinas mayúsculas y minúsculas. Para agregar caracteres con signos diacríticos, cambie el subrango Unicode o pegue los caracteres directamente en el campo Selected characters.
- El segundo conjunto contiene los signos de puntuación: ,-.()’. Para evitar que la cadena contenga únicamente signos de puntuación, establezca Portion in text, % para el segundo conjunto en 40%.
- Desactive la opción Search for parts of words.
- Especifique el área de búsqueda para el elemento “NameLine”: debajo del elemento “kwPatientTitle” y lo más cerca posible de él.
- Haga clic en Match y revise el Tree of Hypotheses. Se encuentran dos cadenas de caracteres, pero la segunda contiene la dirección del paciente.
-
Para excluir la dirección de los resultados de búsqueda, agregue una condición de búsqueda mediante script:
- Seleccione el elemento de búsqueda “NameLine” y abra el editor de código de Search Conditions.
-
Pegue el siguiente script: se asume que la primera línea contiene un nombre completo si incluye una coma y un espacio; si se encuentra un nombre completo, el grupo repetido deja de buscar una segunda instancia:
- Haga clic en Match y asegúrese de que el nombre se haya encontrado correctamente.
Cree el elemento Region NameRegion
- Cree un elemento de búsqueda Region en el grupo “PatientGroup” y cámbiele el nombre a “NameRegion”.
-
Abra el Code Editor y pegue el siguiente script en la sección Search Conditions:
Crear el elemento AddressRegion de tipo Region
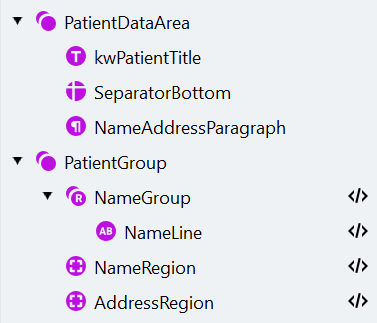
Crear y mapear los campos del paciente
Extraiga el tipo de parte de baja por enfermedad
Crear el TypeOfSickNoteGroup y el PrimaryGroup
Configurar el PrimaryGroup
- Dentro del grupo “PrimaryGroup”, cree un elemento texto estático llamado “kwCheckmark” (texto que se debe buscar: “Erstbescheinigung”).
- Este elemento no está relacionado con los elementos buscados anteriormente. En lugar de hacer coincidir todo el árbol de elementos, haga coincidir solo el elemento nuevo haciendo clic en Match Element en el menú contextual del elemento “kwCheckmark”. Asegúrese de que la palabra clave se encuentre correctamente.
- Ahora busque la marca de verificación usando un elemento colección de objetos, que se utiliza para encontrar varios objetos gráficos como marcas de verificación, códigos de barras e imágenes.
- Agregue un elemento colección de objetos llamado “Checkmark”.
- En la lista desplegable Type del panel Propiedades, desmarque todas las opciones excepto Checkmark.
- Establezca el ancho y la altura mínimos del objeto en 30, y el ancho y la altura máximos del objeto en 130.
- Especifique el área de búsqueda de la marca de verificación a la izquierda del elemento “kwCheckmark”.
-
La marca de verificación debe estar situada aproximadamente en la misma línea que la palabra clave. Especifique dónde deben estar situados los bordes superior e inferior del elemento con respecto a la palabra clave pegando el siguiente código en la sección Search Conditions del Code Editor:
- Haga clic en Match.
Crear y configurar el SecondaryGroup
- Copie el grupo “PrimaryGroup” y cambie el nombre de la copia a “SecondaryGroup”.
- Al copiar un grupo, también copia todos sus elementos con sus propiedades. Seleccione el elemento “kwCheckmark” en el grupo “SecondaryGroup” y cambie el texto que se debe buscar a “Folgebescheinigung”.
- El elemento de búsqueda colección de objetos encuentra una colección de todos los objetos adecuados dentro del área de búsqueda. Si las marcas de verificación están situadas en la misma línea, el elemento “Checkmark” de “SecondaryGroup” también puede encontrar la marca de verificación principal. Para evitarlo, excluya la marca de verificación principal (elemento “Checkmark” de “PrimaryGroup”) del área de búsqueda del elemento “Checkmark” de “SecondaryGroup”.
- Haga clic en Match.
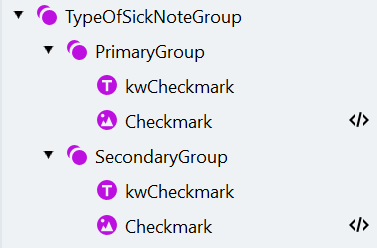
Crear y asignar los campos del tipo de parte de baja por enfermedad
Extraer los datos del médico
Cree DoctorAreaGroup y DataArea
- Cree un elemento Group llamado “DoctorAreaGroup” y haga que el elemento sea opcional.
- Para encontrar la etiqueta del cuadro, cree un elemento Static Text llamado “kwDoctorTitle” (texto a buscar: “Unterschrift des Arztes”).
- Dentro del grupo “DoctorAreaGroup”, cree otro grupo llamado “DataArea”.
Agregue los cuatro separadores delimitadores
Cree BoxRegion
Crear el grupo DoctorGroup
Añada la colección de objetos Signature
Agregue el párrafo "DoctorInformation"
Compruebe que se hayan encontrado los elementos
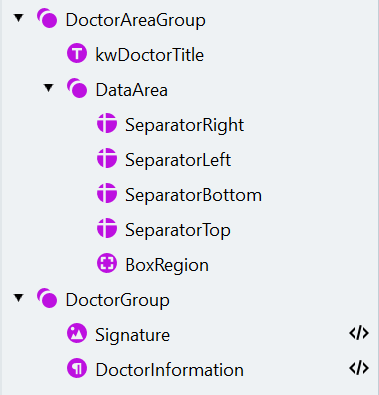
Cree y asigne los campos del médico