Ajouter une activité Classify By Text and Image
Déterminez d’abord la classe du document. Cliquez sur l’activité Classify By Text and Image dans le volet Activities — elle sera ajoutée au workflow.Lorsque vous ajoutez cette activité, un nouveau champ est créé dans la structure de la compétence pour stocker les résultats de classification. Ce champ est masqué et non modifiable, mais vous pouvez le renommer dans le volet Activity Properties de l’onglet Activities. Renommez le champ en “Layout”.
Ajouter une activité IF pour créer une bifurcation dans le flux
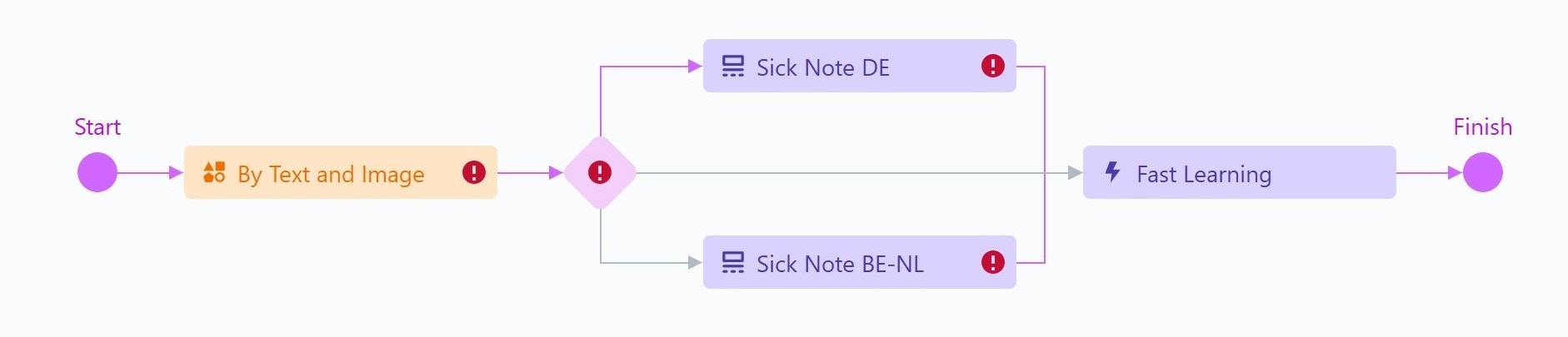
Les documents doivent être orientés vers différentes activités en fonction des résultats de classification.
- Cliquez sur l’activité Classify By Text and Image dans le workflow.
- Dans la fenêtre contextuelle, sélectionnez l’élément IF. Il sera ajouté au workflow après l’activité Classify By Text and Image.
Ajouter des activités Extraction Rules pour chaque classe
Ajoutez les activités permettant d’extraire les données des documents des différentes classes.
- Sélectionnez l’activité Extraction Rules comme élément suivant. Renommez-la en “Sick Note DE” — cette activité extraira les données des documents allemands.
- Cliquez sur l’activité IF et ajoutez une autre activité Extraction Rules. Renommez-la en “Sick Note BE-NL”. Elle traite les documents belges et néerlandais (les variantes de cette classe peuvent être gérées par une seule activité).
Ajouter une activité Fast Learning à la fin
L’activité Fast Learning permet de poursuivre l’entraînement de la compétence en production via Online Learning.
- Cliquez sur “Sick Note BE-NL” dans le flux de traitement.
- Dans la fenêtre contextuelle, sélectionnez l’activité Fast Learning. Elle est ajoutée après “Sick Note BE-NL”, mais “Sick Note DE” reste connecté à Finish.
- Survolez la flèche reliant “Sick Note DE” à Finish. La flèche devient orange.
- Faites glisser cette flèche et déposez-la sur l’activité Fast Learning.
- Survolez la flèche reliant l’activité IF à Finish. Faites également glisser cette flèche et déposez-la sur l’activité Fast Learning.
Étapes suivantes
Étape 3. Configurer et entraîner l’activité Classify
Téléversez des documents d’entraînement, attribuez-leur des classes et entraînez l’activité de classification.
Vue d’ensemble du tutoriel
Retour à l’introduction du tutoriel.