Avant de commencer
Ouvrez l’activité dans l’Éditeur d’activité
- Ouvrez l’activité “arrêt maladie DE” dans l’Éditeur d’activité.
- Sélectionnez l’un des documents de l’ensemble de documents.
Activez les propriétés avancées de l’élément
Extraction des données du patient
Créez le group PatientDataArea
- Cliquez sur Create Element et sélectionnez l’élément Group dans la liste déroulante. Renommez-le “PatientDataArea”.
- Dans la section Under what conditions, remplacez la valeur Element is par Optional.
Repérez le libellé du patient à l’aide d’un élément Static Text
- Cliquez sur Create Element et sélectionnez l’élément Static Text dans la liste déroulante. Renommez-le en “kwPatientTitle”.
- Saisissez le texte “Name, Vorname” dans le champ Text to find du volet Properties.
- Cliquez sur Match. Une fois le traitement terminé, le Tree of Hypotheses s’affiche sous le document.
- Assurez-vous qu’Advanced Designer a bien trouvé le texte statique souhaité : un point vert à côté du nom de l’élément indique une correspondance réussie.
- Cliquez sur le nom de l’élément dans le Tree of Hypotheses pour afficher un cadre violet autour de la région correspondante dans le document.
Repérez la limite inférieure à l’aide d’un Separator
- Ajoutez un élément Separator au groupe et nommez-le « SeparatorBottom ». Définissez sa longueur minimale sur 200.
- Cliquez avec le bouton droit sur l’élément, puis sélectionnez Match Element dans le menu contextuel. Le Tree of Hypotheses contient de nombreux points verts : ils correspondent à différents séparateurs répondant aux critères de recherche. Cliquez sur chaque point pour voir l’objet correspondant sur l’image.
- Pour affiner les critères de recherche, spécifiez la zone de recherche du Separator :
- Cliquez sur Match pour trouver l’élément « kwPatientTitle », qui sera utilisé comme élément d’ancrage.
- Dans la section Where to search du volet Properties, cliquez sur Draw on Image.
- Sélectionnez l’élément « kwPatientTitle » dans le document, puis cliquez sur l’icône de flèche vers le bas pour définir la zone de recherche sous le mot-clé et sur l’icône la plus proche afin de rechercher le Separator le plus proche du mot-clé.
- Cliquez sur Match et vérifiez qu’Advanced Designer a trouvé le Separator sous l’élément « kwPatientTitle ».
Recherchez le Paragraph du nom et de l’adresse
- Créez un élément de recherche Paragraph et nommez-le “NameAddressParagraph”.
- Définissez Text alignment sur Left.
- Les données du patient occupent de deux à cinq lignes ; indiquez donc Line count de 2 à 5.
- Définissez la zone de recherche du paragraphe à l’aide du menu Add dans la section Where to search. L’élément doit se trouver sous l’élément “kwPatientTitle” et au-dessus de l’élément “SeparatorBottom”.
- Cliquez sur Match.
Créer le PatientGroup
Configurer le groupe répétitif NameGroup
- Créez un élément de recherche Repeating Group et nommez-le “NameGroup”. Indiquez 2 comme nombre maximal de répétitions. Rendez l’élément facultatif.
-
Pour limiter la zone de recherche aux lignes faisant partie du paragraphe “NameAddressParagraph”, cliquez sur l’icône de l’éditeur de code sous l’image du document et collez le script suivant dans la section Conditions de recherche de l’éditeur de code :
- Dans le groupe répétitif, créez un élément Character String destiné à capturer une ligne de caractères. Nommez-le “NameLine”.
-
Le texte recherché peut contenir des lettres majuscules et minuscules, ainsi qu’un ensemble de signes de ponctuation. Configurez deux jeux de caractères distincts :
- Le premier jeu contient toutes les lettres latines majuscules et minuscules. Pour ajouter des caractères diacrités, modifiez la sous-plage Unicode ou collez directement les caractères dans le champ Caractères sélectionnés.
- Le second jeu contient les signes de ponctuation suivants : ,-.()’. Pour éviter que la chaîne ne contienne uniquement des signes de ponctuation, définissez Portion dans le texte, % sur 40 % pour le second jeu.
- Désactivez l’option Rechercher des parties de mots.
- Indiquez la zone de recherche de l’élément “NameLine” : sous l’élément “kwPatientTitle” et au plus près de celui-ci.
- Cliquez sur Match et examinez l’arbre des hypothèses. Deux chaînes de caractères sont trouvées, mais la seconde contient l’adresse du patient.
-
Pour exclure l’adresse des résultats de recherche, ajoutez une condition de recherche par script :
- Sélectionnez l’élément de recherche “NameLine” et ouvrez l’éditeur de code Conditions de recherche.
-
Collez le script suivant : il suppose que la première ligne contient un nom complet si elle comporte une virgule et un espace. Si un nom complet est trouvé, le groupe répétitif cesse de rechercher une deuxième instance :
- Cliquez sur Match et vérifiez que le nom est correctement trouvé.
Créez l’élément Region nommé NameRegion
- Créez un élément de recherche Region dans le groupe “PatientGroup” et renommez-le “NameRegion”.
-
Ouvrez l’éditeur de code et collez le script suivant dans la section Conditions de recherche :
Créez l’élément AddressRegion de type Region
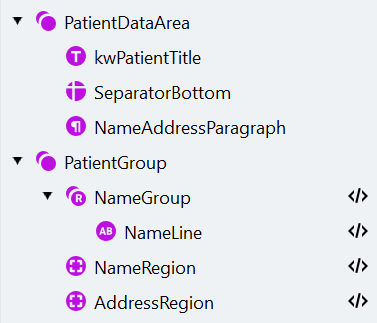
Créez et associez les champs du patient
Extraction du type d’arrêt maladie
Créer le TypeOfSickNoteGroup et le PrimaryGroup
Configurer le PrimaryGroup
- À l’intérieur du groupe “PrimaryGroup”, créez un élément Static Text appelé “kwCheckmark” (texte à trouver : “Erstbescheinigung”).
- Cet élément n’est pas lié aux éléments recherchés précédemment. Au lieu d’associer toute l’arborescence des éléments, associez uniquement le nouvel élément en cliquant sur Match Element dans le menu contextuel de l’élément “kwCheckmark”. Assurez-vous que le mot-clé a bien été trouvé.
- Trouvez maintenant la coche à l’aide d’un élément Object Collection, qui sert à trouver différents objets graphiques tels que des coches, des code-barres et des images.
- Ajoutez un élément Object Collection appelé “Checkmark”.
- Dans la liste déroulante Type du volet Properties, désélectionnez toutes les options sauf Checkmark.
- Définissez la largeur et la hauteur minimales de l’objet sur 30, et sa largeur et sa hauteur maximales sur 130.
- Indiquez la zone de recherche de la coche à gauche de l’élément “kwCheckmark”.
-
La coche doit se trouver approximativement sur la même ligne que le mot-clé. Indiquez où doivent se situer les bordures supérieure et inférieure de l’élément par rapport au mot-clé en collant le code suivant dans la section Search Conditions de l’éditeur de code :
- Cliquez sur Associer.
Créer et configurer le SecondaryGroup
- Copiez le groupe “PrimaryGroup” et renommez la copie en “SecondaryGroup”.
- Lorsque vous copiez un groupe, vous copiez également tous ses éléments avec leurs propriétés. Sélectionnez l’élément “kwCheckmark” dans le groupe “SecondaryGroup” et remplacez le texte à trouver par “Folgebescheinigung”.
- L’élément de recherche Object Collection trouve une collection de tous les objets appropriés dans la zone de recherche. Si les coches se trouvent sur la même ligne, l’élément “Checkmark” du “SecondaryGroup” peut aussi trouver la coche primaire. Pour éviter cela, excluez la coche primaire (élément “Checkmark” du “PrimaryGroup”) de la zone de recherche de l’élément “Checkmark” du “SecondaryGroup”.
- Cliquez sur Associer.
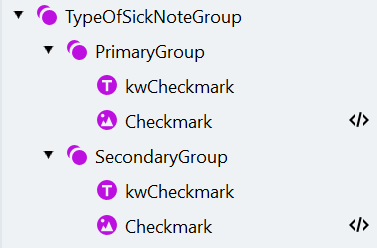
Créer et mapper les champs du type d’arrêt maladie
Extraire les données du médecin
Créez « DoctorAreaGroup » et « DataArea »
- Créez un élément Group nommé “DoctorAreaGroup” et définissez cet élément comme facultatif.
- Pour trouver le libellé de la zone, créez un élément Static Text nommé “kwDoctorTitle” (texte à rechercher : “Unterschrift des Arztes”).
- À l’intérieur du groupe “DoctorAreaGroup”, créez un autre groupe nommé “DataArea”.
Ajoutez les quatre Separator de bordure
Créez l’élément BoxRegion
Créez le groupe DoctorGroup
Ajoutez l’Object Collection nommée Signature
Ajoutez le Paragraph DoctorInformation
Vérifiez que les éléments ont bien été trouvés
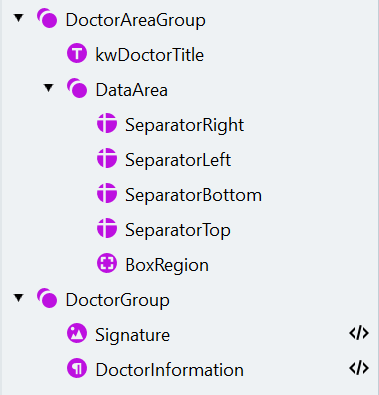
Créer et associer les champs du médecin