Conversion de documents
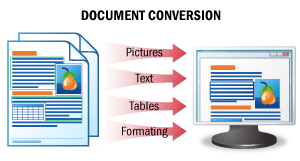
Le résultat de ce scénario est une version modifiable d’un document.
Dans ce scénario, les images de documents sont reconnues en conservant intégralement la mise en forme d’origine, et les données sont enregistrées dans un format de fichier modifiable. Vous obtenez ainsi des versions modifiables de vos documents, faciles à vérifier et à corriger.
Voir Conversion de documents pour plus de détails.
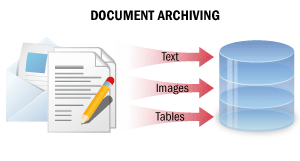
Dans ce scénario de traitement, les documents papier sont convertis en copies numériques non modifiables contenant toutes les informations du document dans un format consultable. Grâce à ce traitement, les copies numériques des documents peuvent être facilement retrouvées dans une archive électronique par recherche plein texte, des segments de texte peuvent être copiés, et les documents peuvent être envoyés par e-mail ou imprimés.
Voir Archivage de documents pour plus de détails.
Capture de données
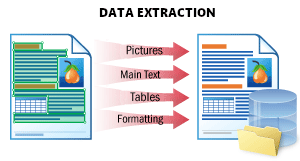
Ce scénario sert à extraire toutes les données possibles d’un document et à les stocker de manière structurée.
Le résultat est un fichier JSON qui représente la structure du document. Il stocke tous les objets du document : texte imprimé et manuscrit, tableaux, code-barres, coches et images, avec leur position et leurs attributs. Ce format est idéal pour un traitement ultérieur, le stockage des données dans une base de données ou l’intégration avec une autre application.
Voir Extraction de données pour plus de détails.
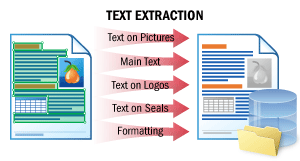
Ce scénario permet d’extraire le texte principal d’un document ainsi que les textes figurant sur les logos, les sceaux et tous les autres éléments.
L’ordre naturel du texte, « comme un humain le lirait », est préservé. Vous pouvez ensuite transmettre les documents à des moteurs de traitement du langage naturel (NLP) de votre côté, par exemple pour les résumer rapidement, rechercher des informations sensibles ou effectuer une analyse de sentiment.
Voir Extraction de texte pour plus de détails.
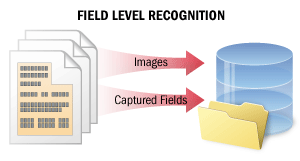
Dans le cas de la reconnaissance au niveau du champ, de courts fragments de texte sont reconnus afin de capturer les données de certains champs. La qualité de la reconnaissance est cruciale dans ce scénario.
Ce scénario peut également être utilisé dans le cadre de scénarios plus complexes où des données pertinentes doivent être extraites de documents (par exemple, pour capturer les données de documents papier dans des systèmes d’information et des bases de données ou pour classer et indexer automatiquement les documents dans des systèmes de gestion documentaire).
Dans ce scénario, le système reconnaît soit plusieurs lignes de texte dans seulement certains champs, soit l’intégralité du texte d’une petite image. Le système calcule un indice de certitude pour chaque caractère reconnu. Les indices de certitude peuvent ensuite être utilisés lors de la vérification des résultats de reconnaissance. En outre, le système peut stocker plusieurs variantes de reconnaissance pour les mots et les caractères du texte, qui peuvent ensuite être utilisées dans des algorithmes de vote afin d’améliorer la qualité de la reconnaissance.
Voir Reconnaissance au niveau du champ pour plus de détails.
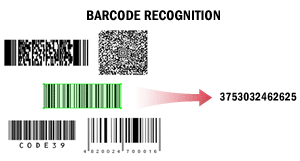
Dans ce scénario, ABBYY FineReader Engine est utilisé pour lire des code-barres. Les code-barres peuvent devoir être lus, par exemple, à des fins de séparation automatique des documents, de traitement des documents par un système de gestion documentaire ou d’indexation et de classification des documents.
Ce scénario peut être utilisé dans le cadre d’autres scénarios. Par exemple, les documents numérisés avec des scanners de production à grande vitesse peuvent être séparés au moyen de code-barres, ou des documents préparés pour un stockage à long terme peuvent être placés dans des systèmes de gestion documentaire d’archivage en fonction des valeurs de leurs code-barres.
Lors de l’extraction de code-barres à partir de textes, le système peut détecter tous les code-barres ou seulement des code-barres d’un certain type ayant une certaine valeur. Le système peut obtenir la valeur d’un code-barres et calculer sa somme de contrôle.
Les valeurs des code-barres reconnus peuvent être enregistrées dans les formats les plus adaptés à un traitement ultérieur, par exemple au format TXT.
Voir Reconnaissance de code-barres pour plus de détails.
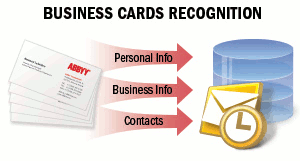
Les cartes de visite contiennent des informations professionnelles sur une entreprise ou une personne. Les cartes de visite peuvent inclure le nom de la personne, l’entreprise, les numéros de téléphone, le fax, l’e-mail, les adresses de site Web et des informations similaires. Vous pouvez avoir besoin de capturer ces informations à partir de cartes de visite papier et de les enregistrer au format électronique. Il peut s’agir d’un carnet d’adresses électronique sur un téléphone mobile, d’un client de messagerie ou de tout autre système de stockage de données. Par exemple, les cartes de visite sont souvent transmises par e-mail ou sur le réseau au format vCard.
Voir Reconnaissance des cartes de visite pour plus de détails.
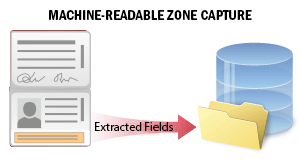
Les documents officiels de voyage ou d’identité de nombreux pays comportent une zone lisible par machine (MRZ), qui permet un traitement plus précis des données du document.
Ce scénario sert à extraire des données d’une zone lisible par machine sur des documents d’identité lors des processus d’intégration des clients ou de vérification. Le système reconnaît la MRZ sur l’image du document et en extrait les données. Les données extraites comprennent plusieurs champs contenant des informations personnelles sur le document et son titulaire (type de document et date d’expiration, prénom et nom du titulaire, etc.). Vous pouvez examiner les champs, vérifier les données et les enregistrer dans un fichier externe pour un traitement ultérieur.
Voir Capture de la zone lisible par machine pour plus de détails.
Autres

Dans ce scénario, ABBYY FineReader Engine est utilisé sur un poste de numérisation, qui numérise les images et les enregistre sous forme de fichiers.
Ce scénario peut être utilisé dans le cadre d’autres scénarios à l’étape préliminaire du traitement des documents, c.-à-d. pour obtenir des versions électroniques des documents en vue d’un traitement ultérieur. Parmi les exemples d’utilisation figurent la numérisation de documents à des fins d’archivage, l’obtention de versions modifiables de documents et l’extraction de données utiles à partir de documents.
Les documents papier sont numérisés et les images sont enregistrées dans un format électronique, ce qui permet d’obtenir des versions électroniques de haute qualité de vos documents imprimés.
Voir Numérisation pour plus de détails.
La classification de documents consiste à affecter un document à l’une des catégories définies par l’utilisateur. Vous pouvez être amené à traiter un flux de documents composé de plusieurs types de documents, par exemple des contrats, des factures ou des reçus. Vous devez identifier le type de chaque document. Par exemple, vous souhaitez trier les documents dans différents dossiers ou les renommer en fonction de leur type. Cela peut être fait automatiquement à l’aide d’un système préentraîné.
L’aspect principal de ce scénario est que vous savez quels types de documents vous allez traiter. ABBYY FineReader Engine peut classer les documents d’après leur apparence ou leur contenu.
Voir Classification de documents pour plus de détails.

Lorsque vous travaillez avec des documents papier, vous devez repérer et corriger les erreurs ou les modifications apportées intentionnellement.
Ce scénario sert à comparer des documents particulièrement importants, tels que des contrats et des documents bancaires, avec leurs copies. Le résultat de comparaison contient des informations sur les différences de type de contenu (texte uniquement), de nature de modification (suppression, insertion ou modification) et sur leur emplacement dans l’original et la copie. Vous pouvez obtenir la liste des différences détectées ou la zone correspondant à une modification, puis enregistrer le résultat de comparaison dans un fichier externe pour un traitement ultérieur ou un archivage à long terme.
Voir Document Comparison pour plus de détails.