Décrire le Texte de recherche
Décrire le Texte de recherche à l’aide d’une expression régulière
Syntaxe des expressions régulières
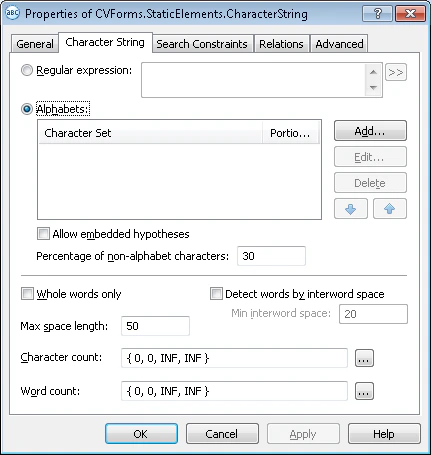
Décrire le Texte de recherche à l’aide d’un alphabet
1
Sélectionnez un mode de génération des hypothèses
Pour utiliser les caractères de la zone de recherche afin de générer toutes les hypothèses possibles, y compris les hypothèses qui se chevauchent et les hypothèses imbriquées, sélectionnez Allow embedded hypotheses. Pour générer des hypothèses de longueur maximale, désactivez Allow embedded hypotheses.
2
Créez un ou plusieurs alphabets
Pour chaque alphabet :
- Cliquez sur Add….
- Dans la boîte de dialogue Add New Alphabet, sélectionnez la page de codes requise dans la liste Code page.
- Dans la Character map, sélectionnez les caractères qui apparaissent dans le Texte de recherche. Les caractères sélectionnés ainsi que leur nombre s’affichent dans le champ Selected on screen/selected in all.
- Dans le champ Percentage of alphabet characters, spécifiez le pourcentage requis de caractères de l’alphabet dans le Texte de recherche.
Vous pouvez spécifier plusieurs alphabets, mais ils ne doivent pas se chevaucher, c’est-à-dire contenir les mêmes caractères.
Propriétés supplémentaires de Character String
- Mots entiers uniquement – Recherche uniquement des mots entiers.
-
Détecter les mots selon l’espace intermot – Indique comment les lignes sont divisées en mots. Désactivez cette option pour détecter automatiquement les mots. Lorsqu’elle est activée, une ligne est divisée en mots chaque fois que l’espace entre des caractères voisins est supérieur ou égal à la valeur saisie dans Espace intermot min.
En cas de détection automatique des mots, les fins de mots sont détectées à partir des espaces, d’autres symboles séparant les mots (par exemple,
,,;,/ou?) ou d’autres attributs. L’ensemble exact des symboles séparateurs dépend de la langue de pré-reconnaissance sélectionnée. Pour vous assurer que FlexiLayout Studio divise correctement les lignes en mots, vérifiez les objets texte dans les images de test (View → Images → Objects → Recognized Words). -
Word count – Indique le nombre de mots dans la chaîne de caractères à l’aide d’un intervalle approximatif. L’intervalle par défaut est
{-1,-1,INF,INF}(c’est-à-dire que les hypothèses comportant un nombre quelconque de mots sont associées). - Max space length – Indique la longueur maximale de l’espace à l’intérieur de l’objet, mesurée dans les unités de mesure définies par l’utilisateur. Vous pouvez estimer la longueur de l’espace en examinant les coordonnées des objets voisins : placez le pointeur de la souris sur un objet voisin pour afficher ses coordonnées dans la barre d’état. Lors de la recherche de texte, des caractères sont ajoutés à la chaîne de caractères jusqu’à ce que la distance entre des éléments voisins dépasse Max space length.
-
Character count – Indique la longueur de la chaîne de caractères (le nombre de caractères) à l’aide d’un intervalle approximatif, qui évalue également la qualité de l’hypothèse en fonction de sa longueur. Utilisez le bouton
 pour spécifier des intervalles approximatifs dans une fenêtre séparée qui les visualise.
pour spécifier des intervalles approximatifs dans une fenêtre séparée qui les visualise.