Méthode
Caractères
Définition d’un ensemble de caractères
1
Sélectionner une norme d’encodage des caractères
Sélectionnez la norme d’encodage de caractères appropriée dans les listes déroulantes des champs Code Page ou Unicode Subrange.
2
Sélectionner les caractères
Sélectionnez les caractères souhaités dans le tableau ci-dessous.
3
Relire les caractères sélectionnés
Les caractères sélectionnés s’affichent dans le champ Selected characters. Vous pouvez également définir un ensemble de caractères à l’aide du clavier.
4
Indiquer la proportion de caractères
Dans le champ
Portion in text, %, indiquez la proportion de caractères (de 0 à 100) présents dans le texte recherché.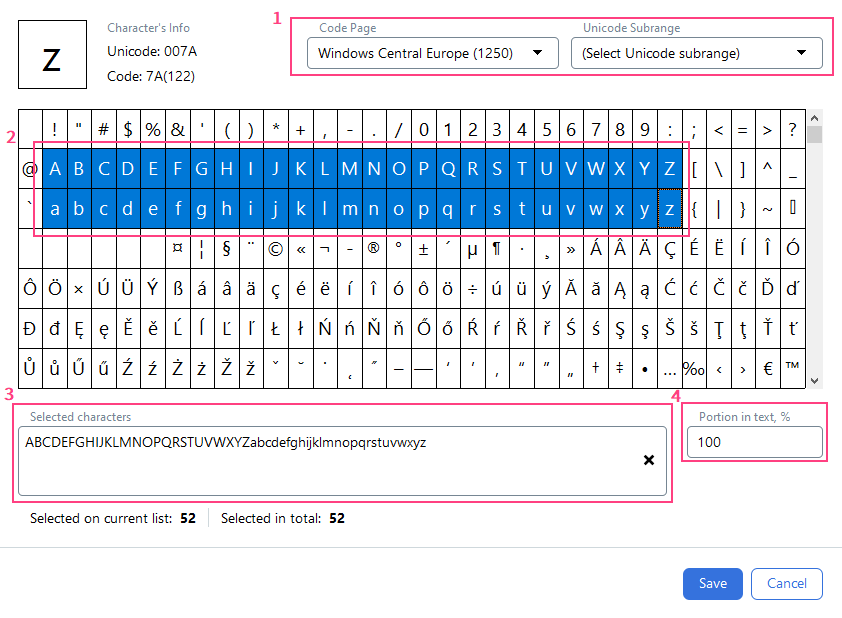
Expression régulière
Alphabet des expressions régulières
Exemples d’expressions régulières
Expressions régulières étendues
[% and %]). Les expressions régulières étendues offrent les fonctionnalités supplémentaires suivantes :
- Un ou plusieurs caractères entre crochets sont complétés par des erreurs OCR courantes. Par exemple,
[%S%]peut autoriser S, $ et 5. - Mots spéciaux à l’intérieur de
[%...%]pour des ensembles de caractères courants et des erreurs OCR :- LETTERS — Lettres latines majuscules et caractères couramment reconnus comme telles.
- DIGITS — Chiffres et caractères couramment reconnus comme tels.
- LETTERSANDDIGITS — Lettres latines majuscules, chiffres et caractères couramment reconnus comme lettres latines majuscules et chiffres.
[%DIGITS%]{9} indique neuf chiffres consécutifs ou des erreurs OCR courantes pour les chiffres, p. ex. “OI234Sb7B9”.
Propriétés supplémentaires
- Erreurs autorisées définit le pourcentage maximal d’erreurs de reconnaissance autorisé. Autrement dit, il indique le pourcentage maximal du nombre total de caractères pouvant provenir de caractères en dehors de l’ensemble défini. Une hypothèse pour un objet ne peut être formulée que si son pourcentage d’erreurs de reconnaissance ne dépasse pas la valeur spécifiée.
- Nombre de mots définit le nombre minimal et maximal de mots dans le texte recherché.
- Nombre de caractères définit le nombre minimal et maximal de caractères dans le texte recherché.
- Recherche de parties de mots indique si des fragments de mots sont autorisés dans les hypothèses. Désactivez cette option si vous souhaitez exclure les hypothèses contenant des fragments de mots et ne rechercher que des mots entiers.
Propriétés avancées
- Autoriser les hypothèses imbriquées permet d’utiliser les caractères présents dans la zone de recherche pour générer toutes les hypothèses possibles, y compris les hypothèses intersectées et imbriquées.
- Longueur max. d’espace permet d’indiquer la longueur maximale de l’espace à l’intérieur de l’objet détecté.
- Orientation du texte permet d’indiquer l’orientation du texte recherché. Par défaut, l’activité ne recherche que le texte orienté horizontalement et ne formulera pas d’hypothèse pour du texte pivoté. Si vous devez trouver du texte pivoté d’une certaine manière et ignorer le texte écrit dans toute autre direction, sélectionnez uniquement l’option Sens horaire ou Sens anti‑horaire. Pour trouver le texte quelle que soit son orientation, activez toutes les options disponibles.
- Détecter les mots selon spécifie comment les lignes doivent être découpées en mots : automatiquement (Pré‑reconnaissance) ou en découpant une ligne en mots (Espace inter‑mots) chaque fois que l’espace entre des caractères adjacents est supérieur ou égal à la valeur saisie dans Min. espace inter‑mots.