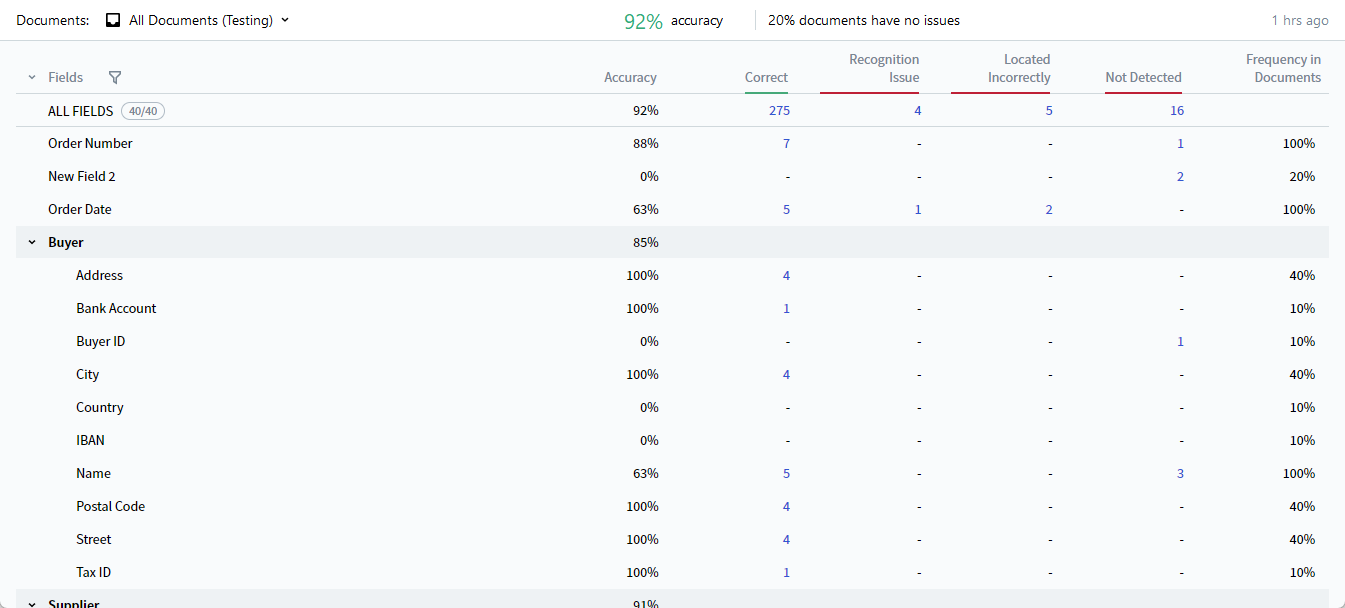
L’onglet Results affiche les statistiques d’extraction des champs d’une compétence. L’analyse de ces statistiques vous aide à identifier les points à améliorer dans la qualité de l’extraction.
Avant de publier une compétence, vérifiez la qualité d’extraction des champs pour vous assurer qu’elle est correctement configurée. Pour tester une compétence, cliquez sur Test Skill — Advanced Designer compare l’annotation de référence aux résultats d’extraction.
La colonne fields répertorie tous les champs extraits par la compétence. Les champs appartenant à un groupe apparaissent dans une liste déroulante réduite portant le nom du groupe.
Les documents comportant une annotation non confirmée sont exclus des résultats de test. L’annotation de référence générée automatiquement à partir de l’annotation prédite reste non confirmée tant que vous n’avez pas copié l’annotation prédite vers la référence à l’aide de la commande Copy Predicted Labeling to Reference du menu contextuel. Vérifiez l’état de l’annotation dans l’onglet Documents ; confirmez l’annotation dans l’onglet fields.
Statistiques propres à l’activité